Blog Articles

Author: Subham Khandelwal
Published: 2023-12-30 12:56:03
Last Updated: 2023-12-30 12:56:03
Published on: Medium

Author: Subham Khandelwal
Published: 2023-11-19 07:19:02
Last Updated: 2023-12-12 07:12:49
Published on: Medium
Author: Subham Khandelwal
Published: 2023-09-30 17:48:30
Last Updated: 2023-09-30 17:48:30
Published on: Medium
Author: Subham Khandelwal
Published: 2023-09-30 17:48:30
Last Updated: 2023-12-12 07:08:35
Published on: Medium

Author: Subham Khandelwal
Published: 2023-04-16 08:20:58
Last Updated: 2023-04-16 08:20:58
Published on: Medium

Author: Subham Khandelwal
Published: 2023-03-21 12:58:58
Last Updated: 2023-03-22 03:18:15
Published on: Medium
Author: Subham Khandelwal
Published: 2023-03-21 12:58:58
Last Updated: 2023-12-12 07:24:01
Published on: Medium

Author: Subham Khandelwal
Published: 2023-03-18 12:06:59
Last Updated: 2023-12-16 07:05:36
Published on: Medium

Author: Subham Khandelwal
Published: 2023-03-13 11:29:04
Last Updated: 2023-03-13 12:59:16
Published on: Medium

Author: Subham Khandelwal
Published: 2023-03-09 11:34:46
Last Updated: 2023-03-12 09:55:32
Published on: Medium

Author: Subham Khandelwal
Published: 2023-03-03 12:11:01
Last Updated: 2023-03-03 12:11:01
Published on: Medium

Author: Subham Khandelwal
Published: 2023-02-25 11:19:59
Last Updated: 2023-02-25 11:19:59
Published on: Medium

Author: Subham Khandelwal
Published: 2023-02-21 06:41:07
Last Updated: 2023-02-26 05:47:35
Published on: Medium

Author: Subham Khandelwal
Published: 2023-02-10 15:43:30
Last Updated: 2023-02-10 15:43:30
Published on: Medium

Author: Subham Khandelwal
Published: 2023-02-08 12:10:52
Last Updated: 2023-02-08 12:10:52
Published on: Medium

Author: Subham Khandelwal
Published: 2023-02-06 09:36:01
Last Updated: 2023-02-06 09:36:01
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-30 15:30:09
Last Updated: 2023-01-30 15:30:09
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-30 15:27:07
Last Updated: 2023-01-30 15:27:07
Published on: Medium
Author: Subham Khandelwal
Published: 2023-01-28 10:52:25
Last Updated: 2023-01-28 10:52:25
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-28 05:30:23
Last Updated: 2023-01-28 05:30:23
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-28 05:25:17
Last Updated: 2023-01-28 05:25:17
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-23 18:41:02
Last Updated: 2023-01-23 18:41:02
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-18 07:03:39
Last Updated: 2023-02-06 09:41:33
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-18 07:02:16
Last Updated: 2023-01-18 07:06:56
Published on: Medium
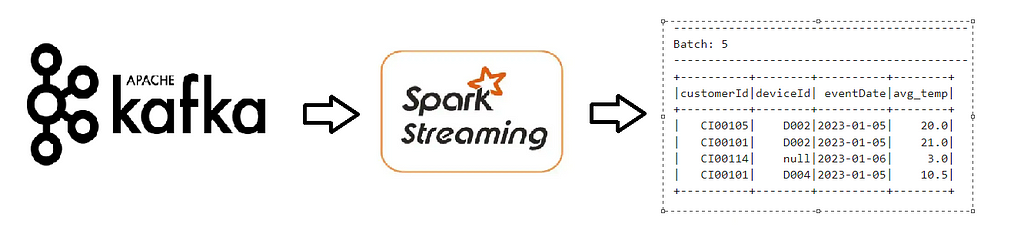
Author: Subham Khandelwal
Published: 2023-01-09 14:36:13
Last Updated: 2023-01-09 14:36:13
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-05 09:35:32
Last Updated: 2023-01-05 09:35:32
Published on: Medium

Author: Subham Khandelwal
Published: 2023-01-04 09:21:00
Last Updated: 2023-01-04 09:21:00
Published on: Medium

Author: Subham Khandelwal
Published: 2022-12-18 09:20:13
Last Updated: 2022-12-18 09:20:13
Published on: Medium
Author: Subham Khandelwal
Published: 2022-11-27 14:33:42
Last Updated: 2022-11-27 14:33:42
Published on: Medium
Author: Subham Khandelwal
Published: 2022-11-19 07:47:52
Last Updated: 2022-11-19 07:47:52
Published on: Medium
Author: Subham Khandelwal
Published: 2022-11-14 11:26:36
Last Updated: 2022-11-14 11:26:36
Published on: Medium
Author: Subham Khandelwal
Published: 2022-11-11 08:54:34
Last Updated: 2022-11-11 08:54:34
Published on: Medium
Author: Subham Khandelwal
Published: 2022-11-04 10:46:59
Last Updated: 2022-11-04 10:46:59
Published on: Medium
Author: Subham Khandelwal
Published: 2022-11-02 10:46:47
Last Updated: 2022-11-02 10:46:47
Published on: Medium
Author: Subham Khandelwal
Published: 2022-10-31 11:24:31
Last Updated: 2022-10-31 11:24:31
Published on: Medium

Author: Subham Khandelwal
Published: 2022-10-28 10:00:51
Last Updated: 2022-10-28 10:00:51
Published on: Medium

Author: Subham Khandelwal
Published: 2022-10-25 13:00:28
Last Updated: 2022-10-25 13:00:28
Published on: Medium
Author: Subham Khandelwal
Published: 2022-10-22 11:08:54
Last Updated: 2022-10-25 11:16:02
Published on: Medium
Author: Subham Khandelwal
Published: 2022-10-21 13:16:56
Last Updated: 2022-10-25 11:16:53
Published on: Medium
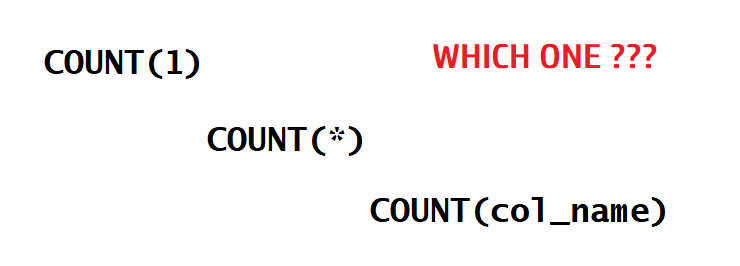
Author: Subham Khandelwal
Published: 2022-10-20 07:54:25
Last Updated: 2022-10-25 11:17:27
Published on: Medium
Author: Subham Khandelwal
Published: 2022-10-19 11:33:55
Last Updated: 2022-10-25 11:18:34
Published on: Medium

Author: Subham Khandelwal
Published: 2022-10-18 11:46:43
Last Updated: 2022-10-25 11:18:02
Published on: Medium
Author: Subham Khandelwal
Published: 2022-10-17 10:32:39
Last Updated: 2022-10-25 10:19:10
Published on: Medium
Author: Subham Khandelwal
Published: 2022-10-16 11:40:14
Last Updated: 2022-10-25 11:23:41
Published on: Medium
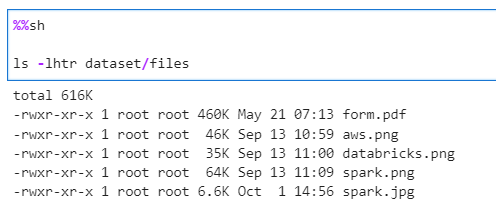
Author: Subham Khandelwal
Published: 2022-10-15 12:47:04
Last Updated: 2022-10-15 11:47:04
Published on: Medium
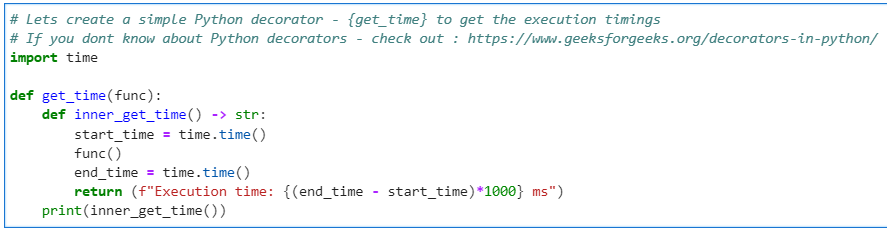
Author: Subham Khandelwal
Published: 2022-10-14 12:09:19
Last Updated: 2022-10-25 11:19:58
Published on: Medium
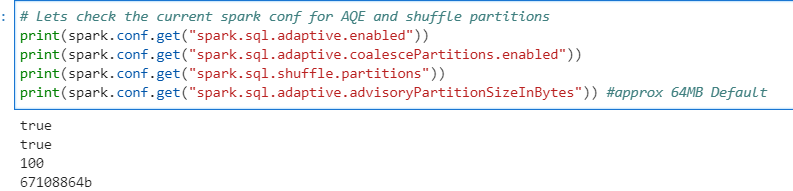
Author: Subham Khandelwal
Published: 2022-10-13 12:16:57
Last Updated: 2022-10-25 11:22:28
Published on: Medium

Author: Subham Khandelwal
Published: 2022-10-12 13:14:09
Last Updated: 2022-10-12 16:27:04
Published on: Medium
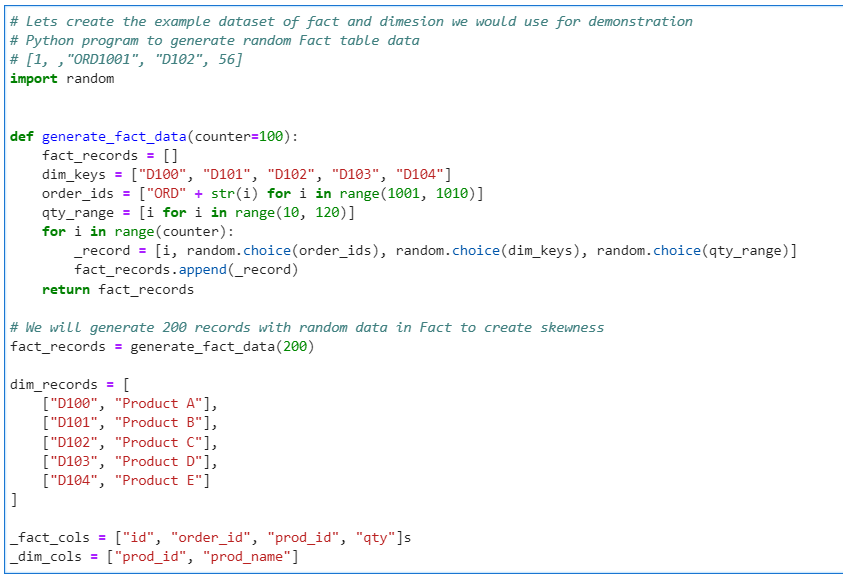
Author: Subham Khandelwal
Published: 2022-10-11 09:52:48
Last Updated: 2022-10-11 09:52:48
Published on: Medium
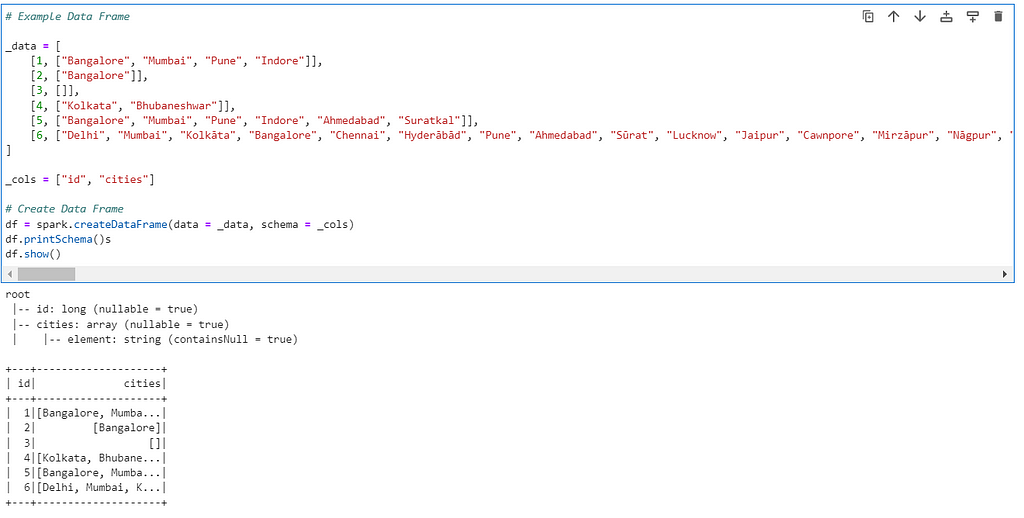
Author: Subham Khandelwal
Published: 2022-10-10 12:41:46
Last Updated: 2022-10-10 12:48:16
Published on: Medium
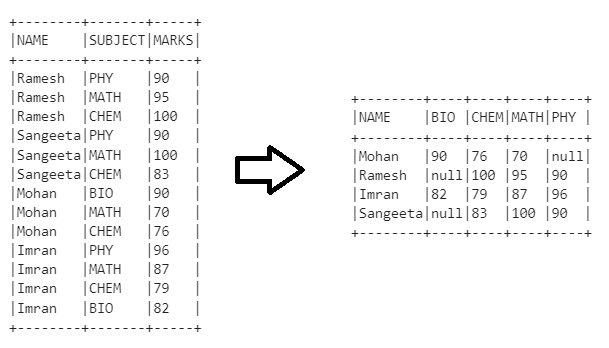
Author: Subham Khandelwal
Published: 2022-10-09 08:51:24
Last Updated: 2022-10-09 08:51:24
Published on: Medium
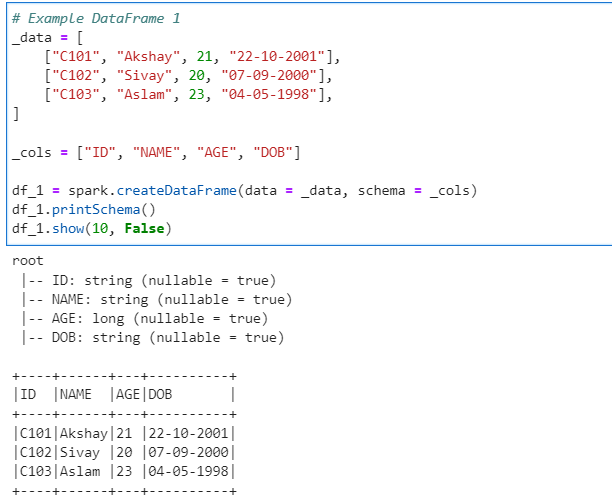
Author: Subham Khandelwal
Published: 2022-10-08 14:41:07
Last Updated: 2022-10-08 14:45:39
Published on: Medium

Author: Subham Khandelwal
Published: 2022-10-07 08:23:49
Last Updated: 2022-10-07 08:23:49
Published on: Medium
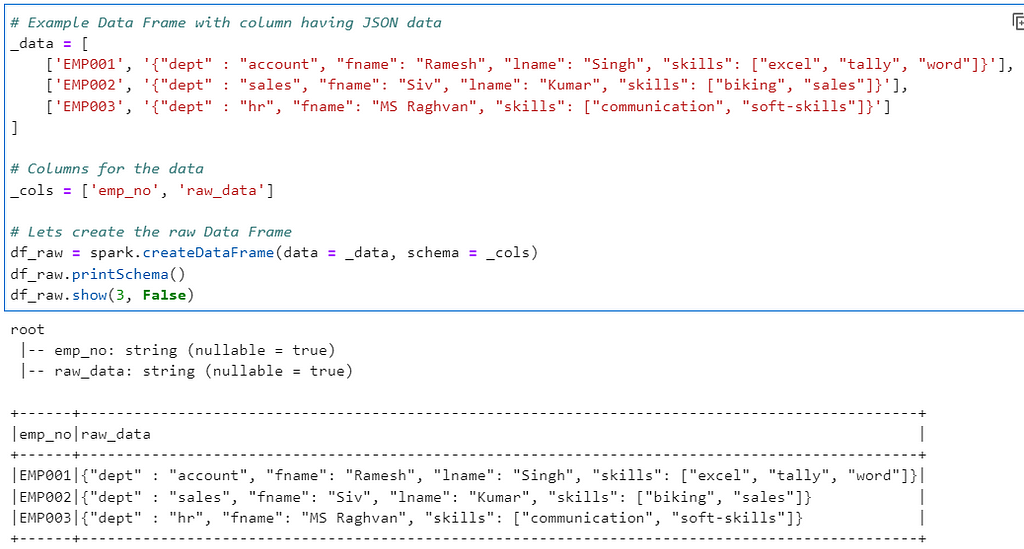
Author: Subham Khandelwal
Published: 2022-10-06 11:18:31
Last Updated: 2022-10-06 11:18:31
Published on: Medium
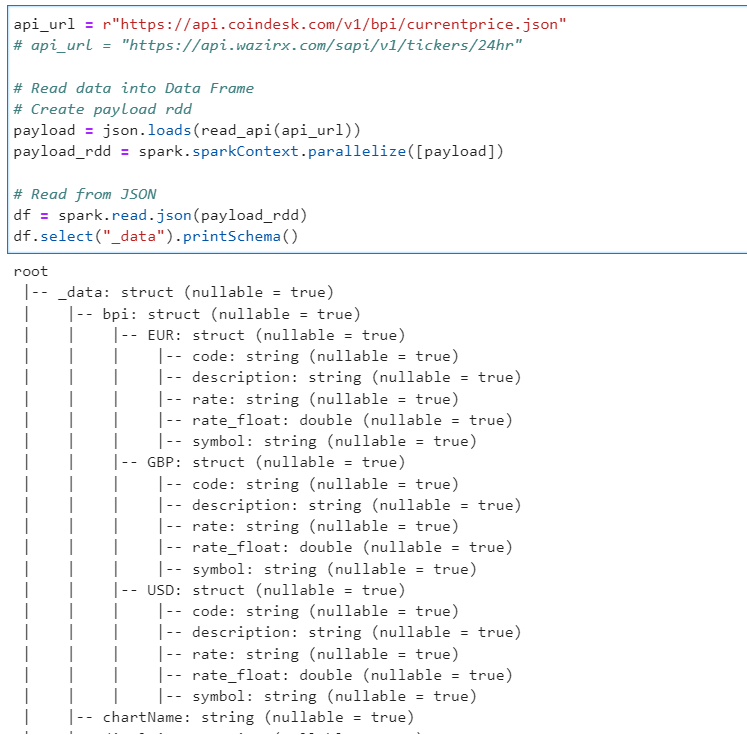
Author: Subham Khandelwal
Published: 2022-10-05 07:40:35
Last Updated: 2022-10-05 07:40:35
Published on: Medium
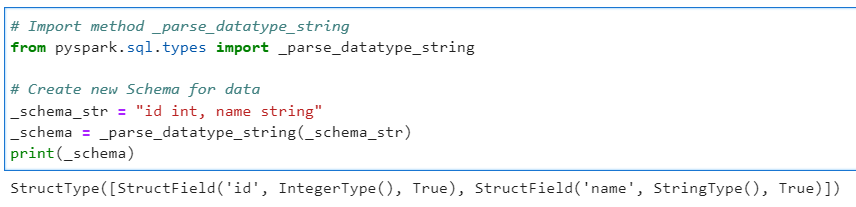
Author: Subham Khandelwal
Published: 2022-10-04 10:36:05
Last Updated: 2022-10-05 08:02:59
Published on: Medium
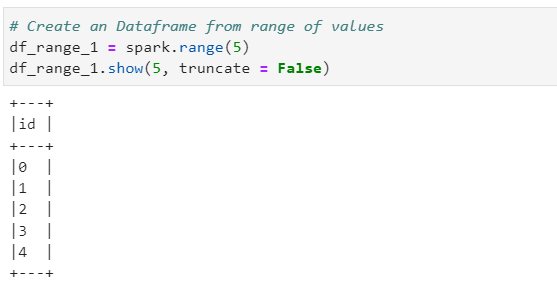
Author: Subham Khandelwal
Published: 2022-10-04 10:00:52
Last Updated: 2022-10-04 10:03:17
Published on: Medium
| Title | Author | Published | Last Updated | Published on |
|---|---|---|---|---|
| PySpark — Optimize Joins in Spark | Subham Khandelwal | 2023-12-30 12:56:03 | 2023-12-30 12:56:03 | Medium |
| PySpark — DAG & Explain Plans | Subham Khandelwal | 2023-11-19 07:19:02 | 2023-12-12 07:12:49 | Medium |
| PySpark — Unit Test Cases using PyTest | Subham Khandelwal | 2023-09-30 17:48:30 | 2023-09-30 17:48:30 | Medium |
| PySpark — Unit Test Cases using PyTest | Subham Khandelwal | 2023-09-30 17:48:30 | 2023-12-12 07:08:35 | Medium |
| PySpark — Optimize Parquet Files | Subham Khandelwal | 2023-04-16 08:20:58 | 2023-04-16 08:20:58 | Medium |
| PySpark — Estimate Partition Count for File Read | Subham Khandelwal | 2023-03-21 12:58:58 | 2023-03-22 03:18:15 | Medium |
| PySpark — Estimate Partition Count for File Read | Subham Khandelwal | 2023-03-21 12:58:58 | 2023-12-12 07:24:01 | Medium |
| PySpark — Optimize Huge File Read | Subham Khandelwal | 2023-03-18 12:06:59 | 2023-12-16 07:05:36 | Medium |
| PySpark — The Effects of Multiline | Subham Khandelwal | 2023-03-13 11:29:04 | 2023-03-13 12:59:16 | Medium |
| PySpark — Worst use of Window Functions | Subham Khandelwal | 2023-03-09 11:34:46 | 2023-03-12 09:55:32 | Medium |
| PySpark —Data Frame Joins on Multiple conditions | Subham Khandelwal | 2023-03-03 12:11:01 | 2023-03-03 12:11:01 | Medium |
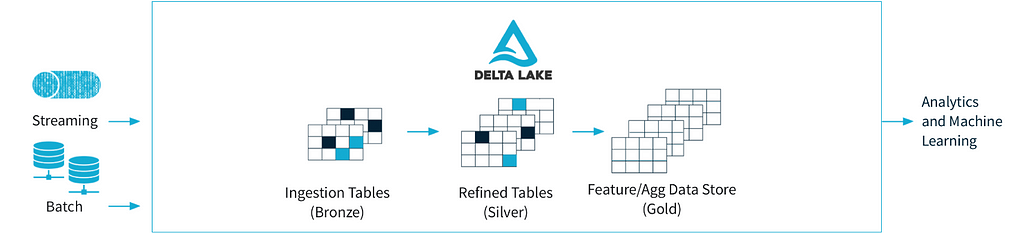
| Data Lakehouse with PySpark — Batch Loading Strategy | Subham Khandelwal | 2023-02-25 11:19:59 | 2023-02-25 11:19:59 | Medium |
| Data Lakehouse with PySpark — Setup Delta Lake Warehouse on S3 and Boto3 with AWS | Subham Khandelwal | 2023-02-21 06:41:07 | 2023-02-26 05:47:35 | Medium |
| Data Lakehouse with PySpark — Setup PySpark Docker Jupyter Lab env | Subham Khandelwal | 2023-02-10 15:43:30 | 2023-02-10 15:43:30 | Medium |
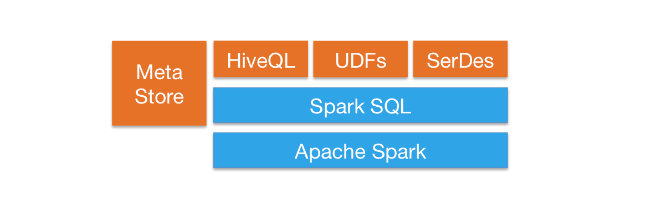
| Data Lakehouse with PySpark — High Level Architecture & DW Model | Subham Khandelwal | 2023-02-08 12:10:52 | 2023-02-08 12:10:52 | Medium |
| Data Lakehouse with PySpark — Introduction & Agenda | Subham Khandelwal | 2023-02-06 09:36:01 | 2023-02-06 09:36:01 | Medium |
| Data Warehouse Series — Measures & Attributes Part II | Subham Khandelwal | 2023-01-30 15:30:09 | 2023-01-30 15:30:09 | Medium |
| Data Warehouse Series — Measures & Attributes Part I | Subham Khandelwal | 2023-01-30 15:27:07 | 2023-01-30 15:27:07 | Medium |
| PySpark — Connect AWS S3 | Subham Khandelwal | 2023-01-28 10:52:25 | 2023-01-28 10:52:25 | Medium |
| Data Warehouse Series — ETL vs ELT and Data Loading Strategies | Subham Khandelwal | 2023-01-28 05:30:23 | 2023-01-28 05:30:23 | Medium |
| Data Warehouse Series — OLAP Systems | Subham Khandelwal | 2023-01-28 05:25:17 | 2023-01-28 05:25:17 | Medium |
| Data Warehouse Series — Data Lake vs DW and OLTP Systems | Subham Khandelwal | 2023-01-23 18:41:02 | 2023-01-23 18:41:02 | Medium |
| EaseWithData — Data Warehouse Series | Subham Khandelwal | 2023-01-18 07:03:39 | 2023-02-06 09:41:33 | Medium |
| Data Warehouse Series — Introduction to Data Warehouse | Subham Khandelwal | 2023-01-18 07:02:16 | 2023-01-18 07:06:56 | Medium |
| PySpark — Structured Streaming Read from Kafka | Subham Khandelwal | 2023-01-09 14:36:13 | 2023-01-09 14:36:13 | Medium |
| PySpark — Structured Streaming Read from Files | Subham Khandelwal | 2023-01-05 09:35:32 | 2023-01-05 09:35:32 | Medium |
| PySpark — Structured Streaming Read from Sockets | Subham Khandelwal | 2023-01-04 09:21:00 | 2023-01-04 09:21:00 | Medium |
| PySpark — Connect Azure ADLS Gen 2 | Subham Khandelwal | 2022-12-18 09:20:13 | 2022-12-18 09:20:13 | Medium |
| PySpark — Delta Lake Integration using Manifest | Subham Khandelwal | 2022-11-27 14:33:42 | 2022-11-27 14:33:42 | Medium |
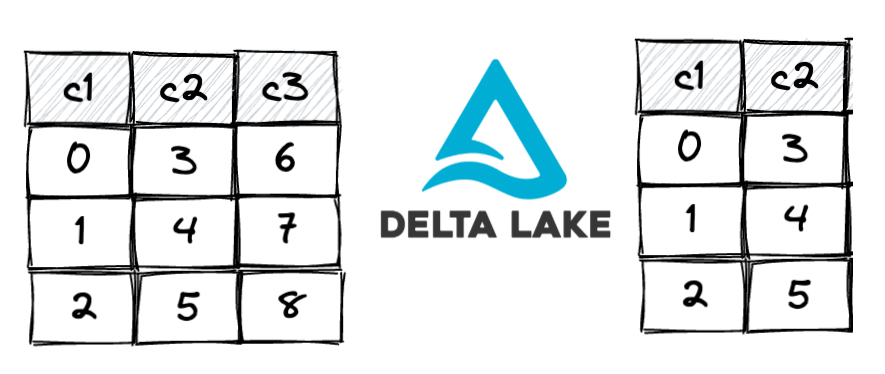
| PySpark — Delta Lake Column Mapping | Subham Khandelwal | 2022-11-19 07:47:52 | 2022-11-19 07:47:52 | Medium |
| PySpark — Setup Delta Lake | Subham Khandelwal | 2022-11-14 11:26:36 | 2022-11-14 11:26:36 | Medium |
| PySpark — Implementing Persisting Metastore | Subham Khandelwal | 2022-11-11 08:54:34 | 2022-11-11 08:54:34 | Medium |
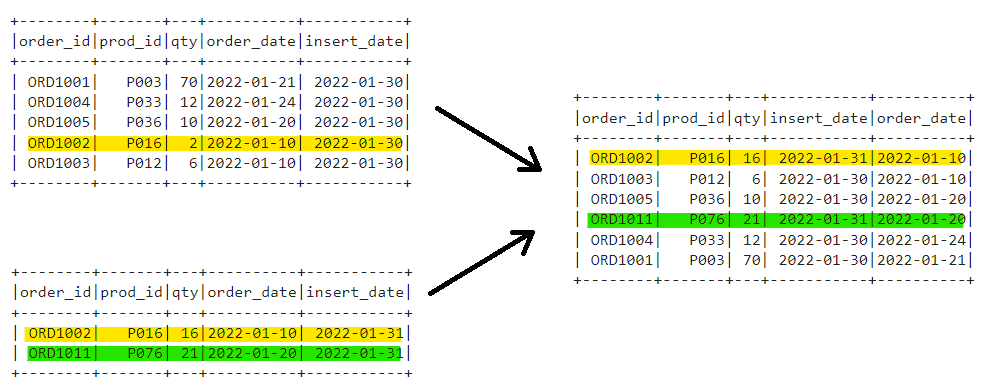
| PySpark — Upsert or SCD1 with Dynamic Overwrite | Subham Khandelwal | 2022-11-04 10:46:59 | 2022-11-04 10:46:59 | Medium |
| PySpark — Dynamic Partition Overwrite | Subham Khandelwal | 2022-11-02 10:46:47 | 2022-11-02 10:46:47 | Medium |
| PySpark - Fix Column Header with Spaces | Subham Khandelwal | 2022-10-31 11:24:31 | 2022-10-31 11:24:31 | Medium |
| PySpark - The Factor of Cores | Subham Khandelwal | 2022-10-28 10:00:51 | 2022-10-28 10:00:51 | Medium |
| PySpark - Optimize Data Scanning exponentially | Subham Khandelwal | 2022-10-25 13:00:28 | 2022-10-25 13:00:28 | Medium |
| PySpark — The Cluster Configuration | Subham Khandelwal | 2022-10-22 11:08:54 | 2022-10-25 11:16:02 | Medium |
| PySpark - Distributed Broadcast Variable | Subham Khandelwal | 2022-10-21 13:16:56 | 2022-10-25 11:16:53 | Medium |
| PySpark - Count(1) vs Count(*) vs Count(col_name) | Subham Khandelwal | 2022-10-20 07:54:25 | 2022-10-25 11:17:27 | Medium |
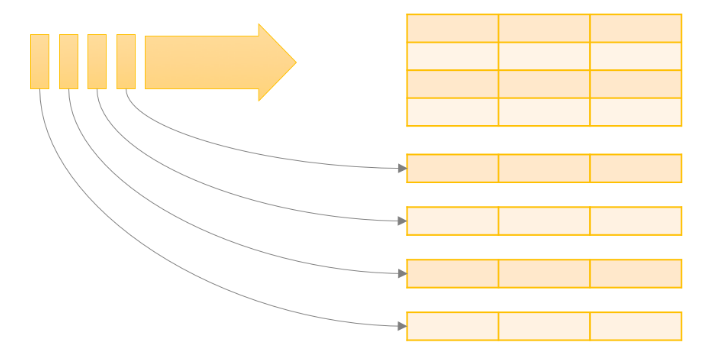
| PySpark - The Basics of Structured Streaming | Subham Khandelwal | 2022-10-19 11:33:55 | 2022-10-25 11:18:34 | Medium |
| PySpark - Tune JDBC for Parallel effect | Subham Khandelwal | 2022-10-18 11:46:43 | 2022-10-25 11:18:02 | Medium |
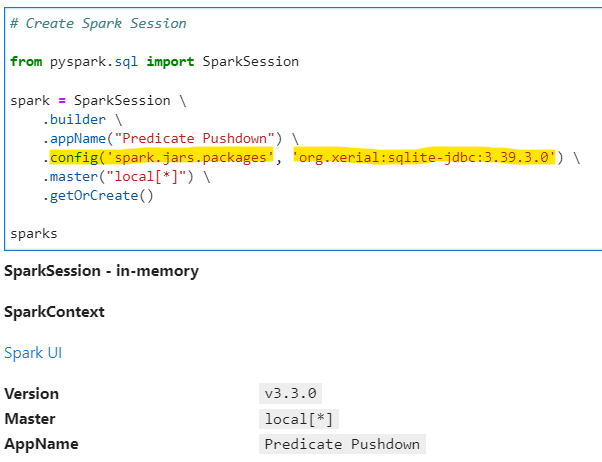
| PySpark - JDBC Predicate Pushdown | Subham Khandelwal | 2022-10-17 10:32:39 | 2022-10-25 10:19:10 | Medium |
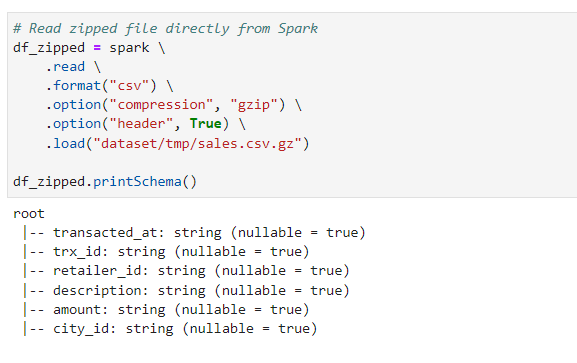
| PySpark - Read Compressed gzip files | Subham Khandelwal | 2022-10-16 11:40:14 | 2022-10-25 11:23:41 | Medium |
| PySpark - Read Binary Files like PNG or PDF | Subham Khandelwal | 2022-10-15 12:47:04 | 2022-10-15 11:47:04 | Medium |
| PySpark - The Tiny File Problem | Subham Khandelwal | 2022-10-14 12:09:19 | 2022-10-25 11:19:58 | Medium |
| PySpark - The Magic of AQE Coalesce | Subham Khandelwal | 2022-10-13 12:16:57 | 2022-10-25 11:22:28 | Medium |
| PySpark - Columnar Read Optimization | Subham Khandelwal | 2022-10-12 13:14:09 | 2022-10-12 16:27:04 | Medium |
| PySpark - The Famous Salting Technique | Subham Khandelwal | 2022-10-11 09:52:48 | 2022-10-11 09:52:48 | Medium |
| PySpark - User Defined Functions vs Higher Order Functions | Subham Khandelwal | 2022-10-10 12:41:46 | 2022-10-10 12:48:16 | Medium |
| PySpark - Optimize Pivot Data Frames like a PRO | Subham Khandelwal | 2022-10-09 08:51:24 | 2022-10-09 08:51:24 | Medium |
| PySpark - Merge Data Frames with different columns | Subham Khandelwal | 2022-10-08 14:41:07 | 2022-10-08 14:45:39 | Medium |
| PySpark - Flatten JSON/Struct Data Frame dynamically | Subham Khandelwal | 2022-10-07 08:23:49 | 2022-10-07 08:23:49 | Medium |
| PySpark - Read/Parse JSON column from another Data Frame | Subham Khandelwal | 2022-10-06 11:18:31 | 2022-10-06 11:18:31 | Medium |
| PySpark - Create Spark Data Frame from API | Subham Khandelwal | 2022-10-05 07:40:35 | 2022-10-05 07:40:35 | Medium |
| PySpark - Create Spark Datatype Schema from String | Subham Khandelwal | 2022-10-04 10:36:05 | 2022-10-05 08:02:59 | Medium |
| PySpark - Create Data Frame from List or RDD on the fly | Subham Khandelwal | 2022-10-04 10:00:52 | 2022-10-04 10:03:17 | Medium |
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal