PySpark — Setup Delta Lake
Delta Lake is one of the hot topics surrounding the big data space right now. It brings in a lot of improvements in terms reliability on data lake. But why is it gaining so much attention?
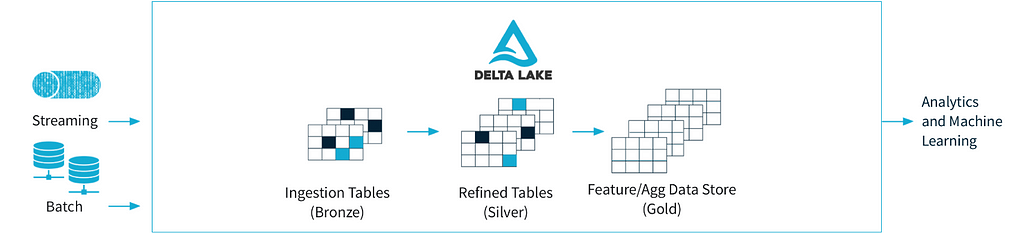
As per Delta IO documentation — “Delta Lake is an open source project that enables building a Lakehouse Architecture on top of data lakes. Delta Lake provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing on top of existing data lakes, such as S3, ADLS, GCS, and HDFS”.
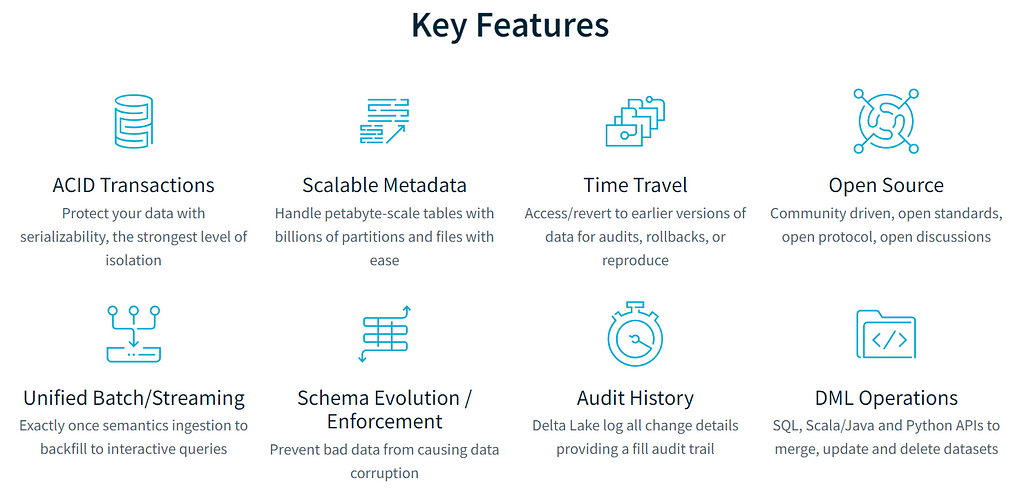
There are so many Key features associated with delta lake, checkout below image
Today, we are going to setup delta lake using PySpark and enable our metastore for the same.
In order to make PySpark support Delta Lake, we need to import the delta-core jar into SparkSession and set the configs right.
# Create Spark Session with Delta JARS and conf
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Delta with PySpark") \
.config('spark.jars.packages', 'io.delta:delta-core_2.12:2.1.1') \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config(
"spark.sql.catalog.spark_catalog",
"org.apache.spark.sql.delta.catalog.DeltaCatalog",
) \
.config("spark.sql.warehouse.dir", "spark-warehouse") \
.master("local[*]") \
.enableHiveSupport() \
.getOrCreate()
spark
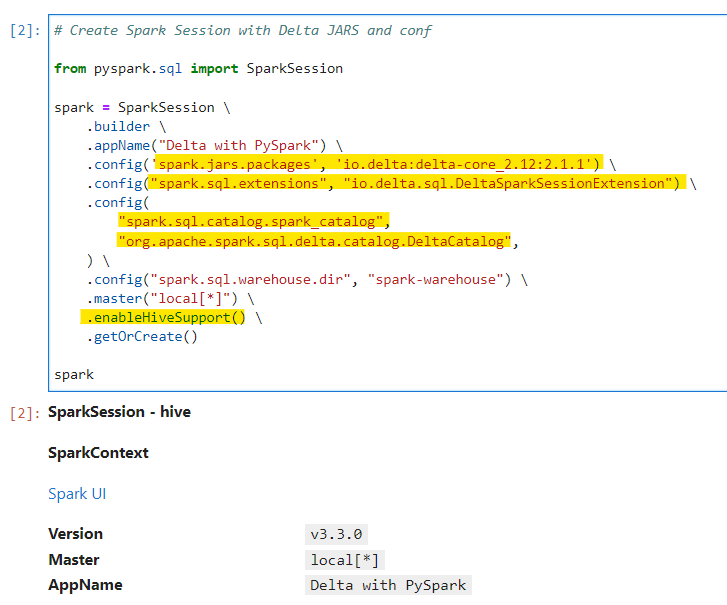
Make sure to enable persisting metastore. Checkout my previous blog on the same — https://urlit.me/blog/pyspark-implementing-persisting-metastore/
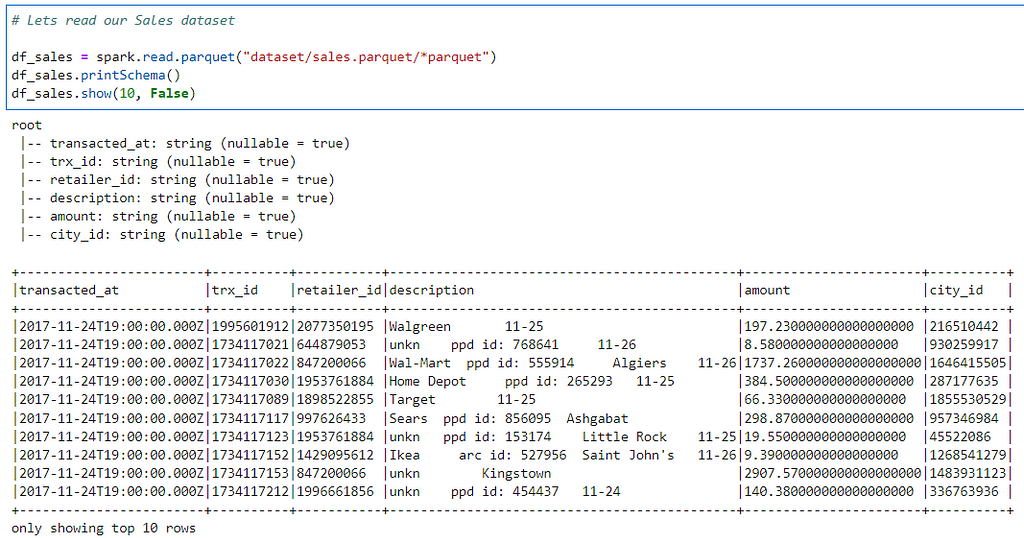
Now, we are ready to work with Delta Lake. To create our first Delta table, lets read the Sales Parquet data.
# Lets read our Sales dataset
df_sales = spark.read.parquet("dataset/sales.parquet/*parquet")
df_sales.printSchema()
df_sales.show(10, False)
Now, we transform and write this data as delta table.
# Lets create a sales managed delta table
from pyspark.sql.functions import to_timestamp, expr
df_formatted = (
df_sales
.withColumn("transacted_at", to_timestamp("transacted_at"))
.withColumn("amount", expr("CAST(amount as decimal(14,2))"))
)
df_formatted.write \
.format("delta") \
.mode("overwrite") \
.option("mergeSchema", True) \
.saveAsTable("sales_delta_managed")
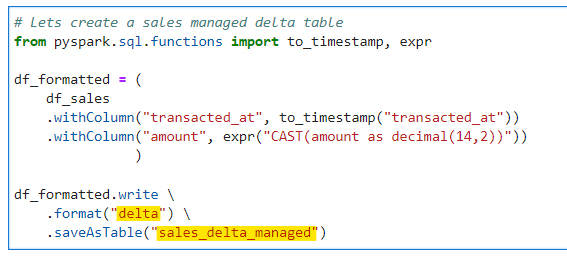
Since we didn’t specify any external location, by default it would be a in-house managed delta table.
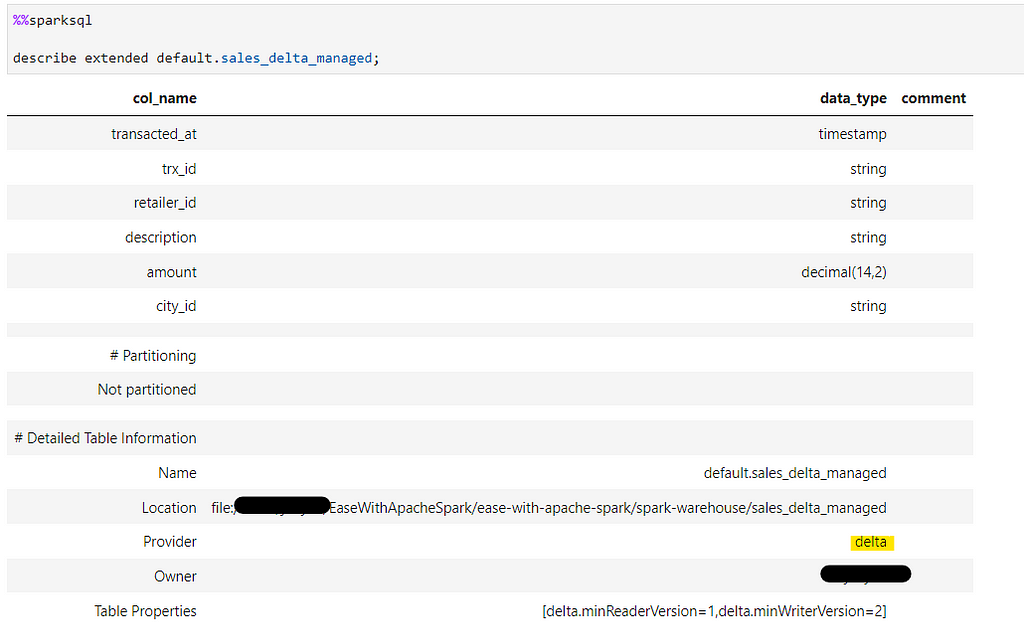
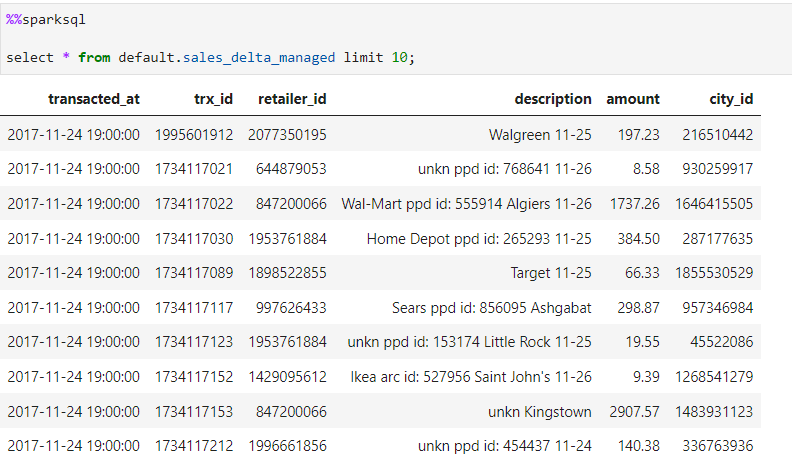
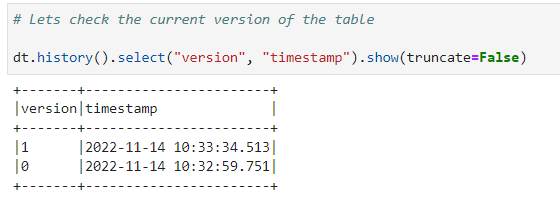
Since, delta tables supports versioning
# Lets check the current version of the table
from delta import DeltaTable
dt = DeltaTable.forName(spark, "sales_delta_managed")
dt.history().select("version", "timestamp").show(truncate=False)
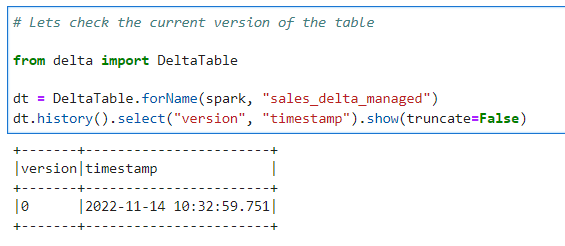
Lets update a record to see the changes in versioning
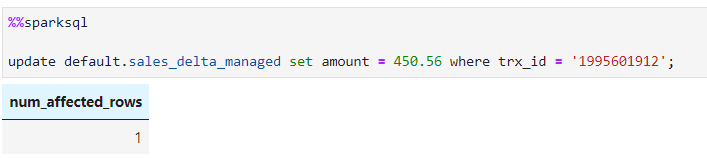
Record got updated without any hassle (delta lake supports DML operations)
Changes in versioning
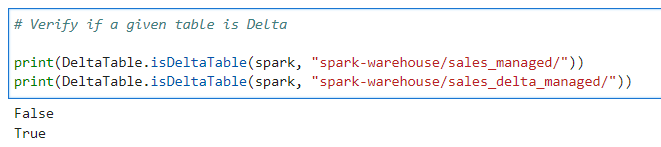
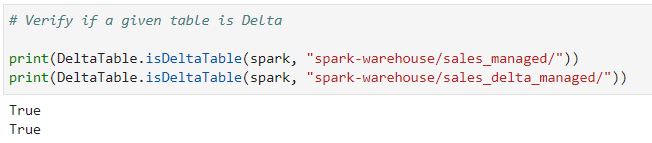
Lets validate if a given table location is Delta Table
# Verify if a given table is Delta
print(DeltaTable.isDeltaTable(spark, "spark-warehouse/sales_managed/"))
print(DeltaTable.isDeltaTable(spark, "spark-warehouse/sales_delta_managed/"))
Bonus : Shortcut to convert Parquet data to delta
# Shortcut to create a Parquet location to delta table
# We will convert the sales_managed table to delta
DeltaTable.convertToDelta(spark, "parquet.`spark-warehouse/sales_managed`")
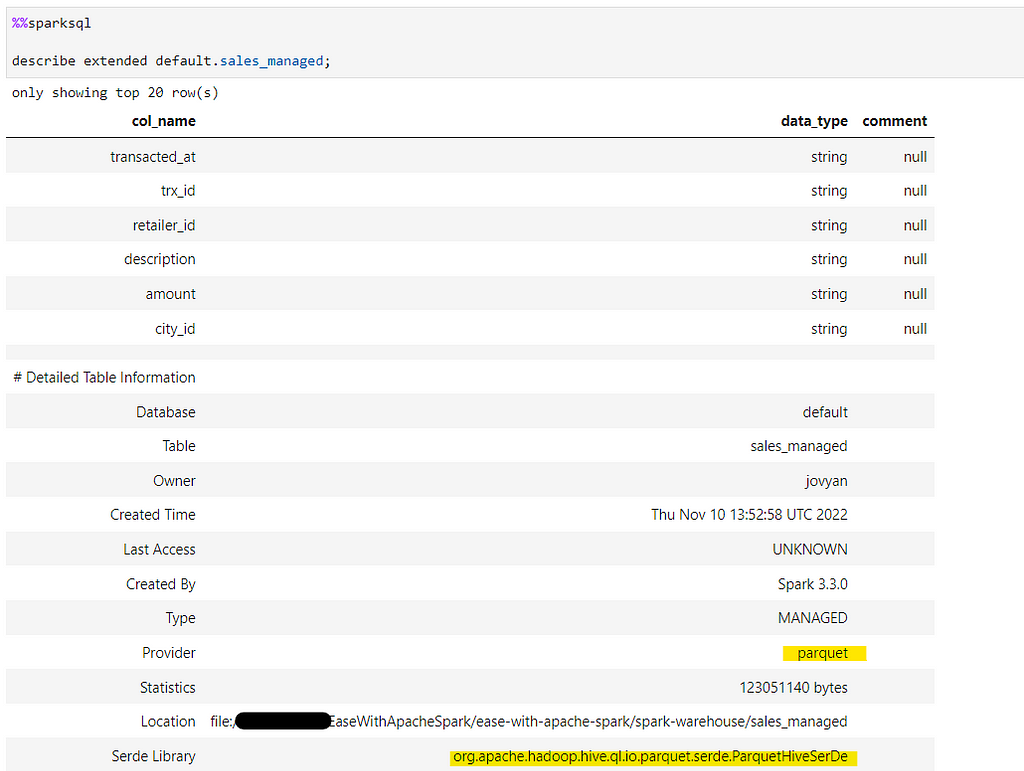
Verify if the location is converted into delta
But, if we check the metadata from Catalog, its still a hive table.
So, to convert the metadata as well
%%sparksql
CONVERT TO DELTA default.sales_managed;
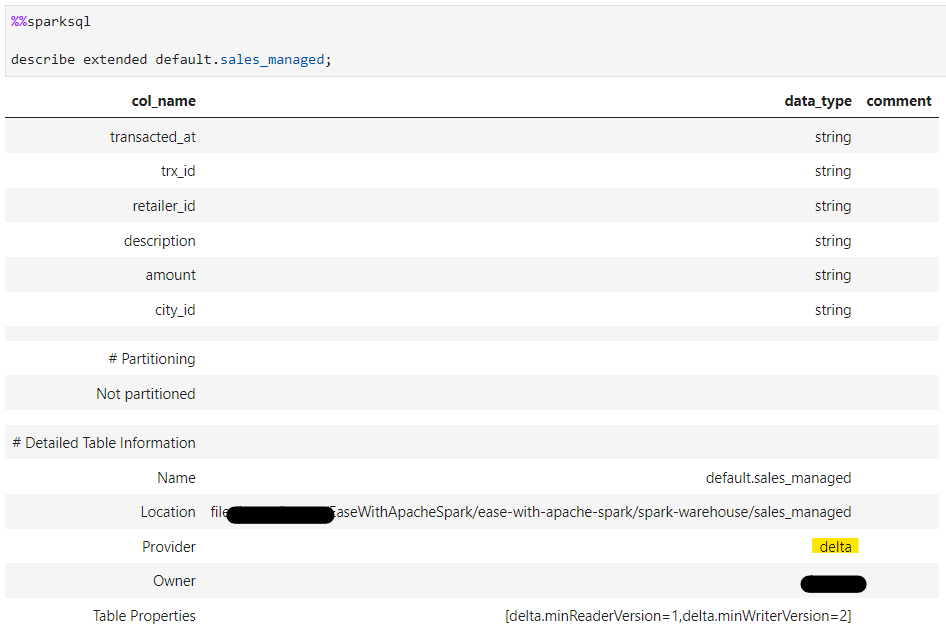
We are going to cover many more Delta Lake concepts in upcoming blogs.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/27_delta_with_pyspark.ipynb
Checkout my Personal blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal