PySpark — Upsert or SCD1 with Dynamic Overwrite
Upsert or Incremental Update or Slowly Changing Dimension 1 aka SCD1 is basically a concept in data modelling, that allows to update existing records and insert new records based on identified keys from an incremental/delta feed.
To implement the same in PySpark on a partitioned dataset, we would take help of Dynamic Partition Overwrite. Lets jump into action.
To know more on Dynamic Partition Overwrite, checkout my previous article — http://urlit.me/75B6B
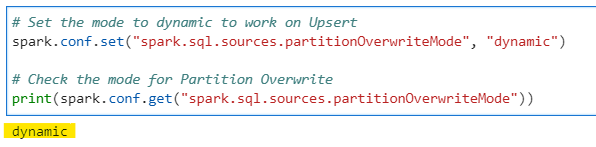
First we will change the Partition Overwrite configuration to DYNAMIC.
# Set the mode to dynamic to work on Upsert
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
# Check the mode for Partition Overwrite
print(spark.conf.get("spark.sql.sources.partitionOverwriteMode"))
Create Orders History Dataset
# Create the Full history dataset
from pyspark.sql.functions import to_date
_data = [
["ORD1001", "P003", 70, "01-21-2022", "01-30-2022"],
["ORD1004", "P033", 12, "01-24-2022", "01-30-2022"],
["ORD1005", "P036", 10, "01-20-2022", "01-30-2022"],
["ORD1002", "P016", 2, "01-10-2022", "01-30-2022"],
["ORD1003", "P012", 6, "01-10-2022", "01-30-2022"],
]
_cols = ["order_id", "prod_id", "qty", "order_date", "insert_date"]
# Create the dataframe
df = spark.createDataFrame(data=_data, schema=_cols)
# Cast the Order date from String to Date
df = df.withColumn("order_date", to_date("order_date" ,"MM-dd-yyyy")).withColumn("insert_date", to_date("insert_date" ,"MM-dd-yyyy"))
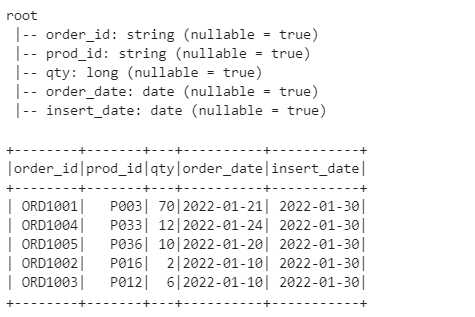
df.printSchema()
df.show()
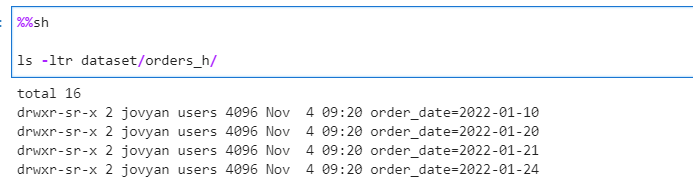
Lets write Orders History data, partitioned on order_date and validate the same
# Write the history data in as partitioned output partitioned by order_date
df.repartition("order_date") \
.write \
.format("parquet") \
.partitionBy("order_date") \
.mode("overwrite") \
.save("dataset/orders_h")
Validate the Orders History dataset
# Validate data
from pyspark.sql.functions import count, lit
spark.read.parquet("dataset/orders_h/").groupBy("order_date").agg(count(lit(1))).show()
df = spark.read.parquet("dataset/orders_h")
df.printSchema()
df.show()

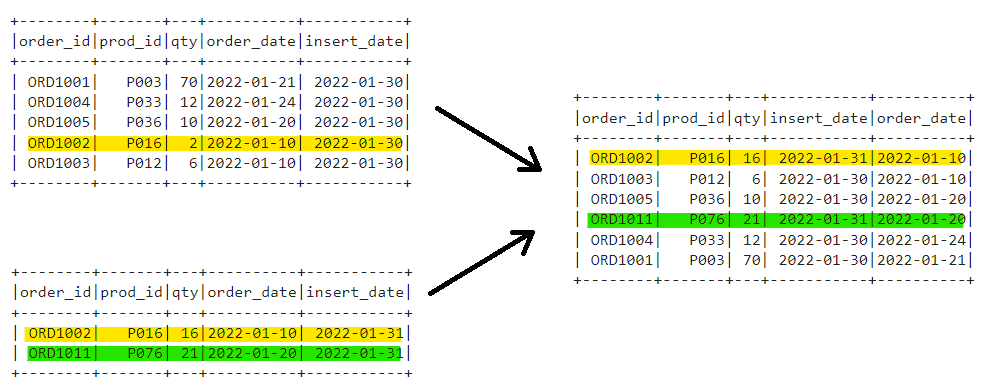
Lets generate our Incremental/Delta feed with following changes:
- Existing Order ORD1002, qty is updated to 16 for same order_date
- New Order ORD1011 created with order_date 01–20–2022
# Lets create our delta dataset for Upsert
# Consider the Order ORD1002 the qty is update to 16 and new order ORD1011 is added on 01-20-2022
_data = [
["ORD1002", "P016", 16, "01-10-2022", "01-31-2022"],
["ORD1011", "P076", 21, "01-20-2022", "01-31-2022"],
]
_cols = ["order_id", "prod_id", "qty", "order_date", "insert_date"]
# Create the delta dataframe
delta_df = spark.createDataFrame(data=_data, schema=_cols)
# Cast the Order date from String to Date
delta_df = delta_df.withColumn("order_date", to_date("order_date" ,"MM-dd-yyyy")).withColumn("insert_date", to_date("insert_date" ,"MM-dd-yyyy"))
delta_df.printSchema()
delta_df.show()
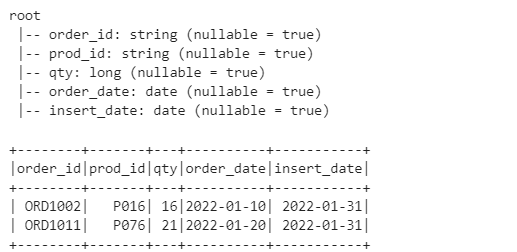
Now, to make things simpler, We will break the whole Incremental Update process in few Steps.
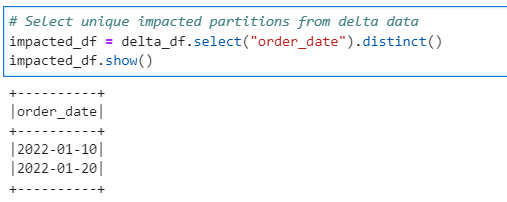
Step 1: Identify the impacted partitions from History dataset using Delta feed.
# Select unique impacted partitions from delta data
impacted_df = delta_df.select("order_date").distinct()
impacted_df.show()
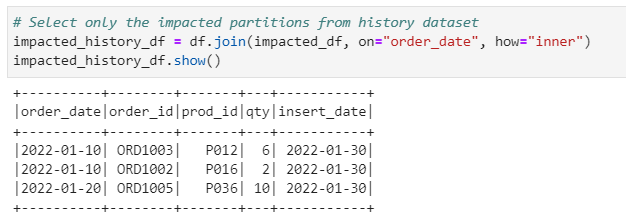
# Select only the impacted partitions from history dataset
impacted_history_df = df.join(impacted_df, on="order_date", how="inner")
impacted_history_df.show()
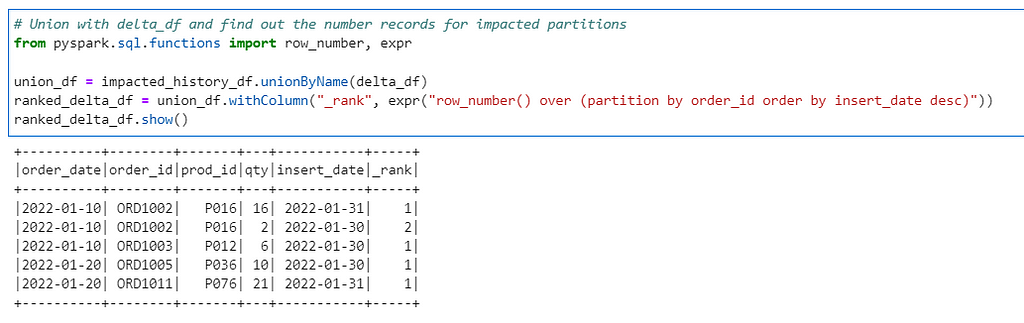
Step 2: Union and Select the latest records based on insert_date and create a final delta dataset (latest impacted history + delta records)
# Union with delta_df and find out the number records for impacted partitions
from pyspark.sql.functions import row_number, expr
union_df = impacted_history_df.unionByName(delta_df)
ranked_delta_df = union_df.withColumn("_rank", expr("row_number() over (partition by order_id order by insert_date desc)"))
ranked_delta_df.show()
# Select the records based rank to upsert
final_delta_df = ranked_delta_df.where("_rank = 1")
final_delta_df.show()

Step 3: Write the Final Delta dataset with Partition Overwrite mode as dynamic after dropping rank column
# Lets drop the rank column write the data into the history now
final_delta_df.drop("_rank").repartition("order_date") \
.write \
.format("parquet") \
.partitionBy("order_date") \
.mode("overwrite") \
.save("dataset/orders_h")
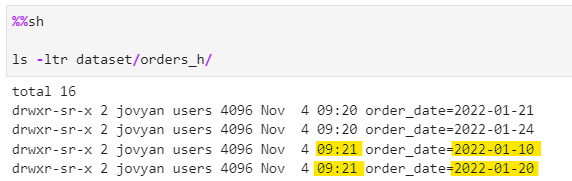
As its evident, only the impacted partitions are overwritten with the final delta feed.
Lets validate the final data in Orders History dataset
# Validate data
from pyspark.sql.functions import count, lit
spark.read.parquet("dataset/orders_h/").groupBy("order_date").agg(count(lit(1))).show()
df = spark.read.parquet("dataset/orders_h")
df.show()
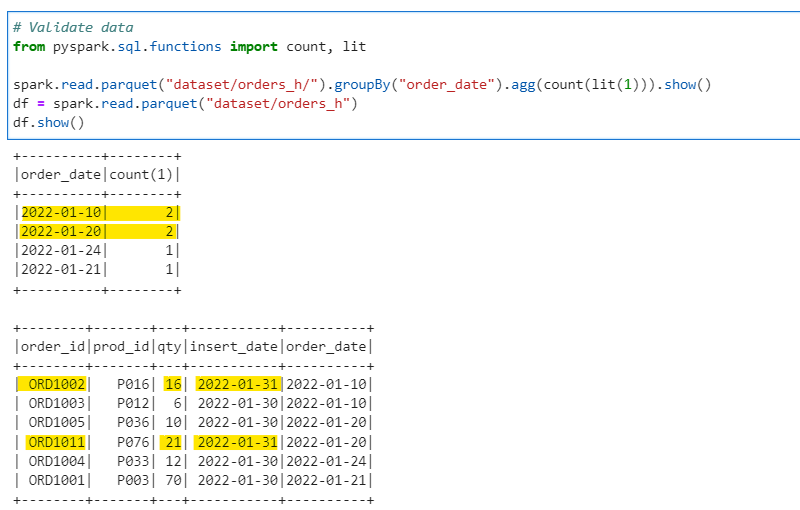
Note: For the above use case we have used only order_id as key for history dataset. In general Production scenario there can be more than one key to identify the change, thus - the rank logic to select the latest data will change accordingly.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/25_upsert_in_pyspark.ipynb
Checkout my personal blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal