PySpark — Worst use of Window Functions
It is very important to understand the core of data distribution for Apache Spark. Very often we don’t realize the importance and make mistakes without even knowing. One of such mistake is to use row_number() for generating Surrogate Keys for Dimensions.

Surrogate Keys are basically synthetic/artificial keys that are generated for Slowly Changing dimensions. There is no need for this key to be sequential but it should be unique for each record in a Dimension table.
Want to understand more on Surrogate Key, checkout this link — https://www.geeksforgeeks.org/surrogate-key-in-dbms/
The REASON
Since we all evolved from DBMS systems continuously using sequence generators for Surrogate Keys, we tend to do the same with Big data as well. And to make things easier and simpler we start using row_number() window function.
The BAD EFFECT
So to understand the bad effect, lets read a dummy sales dataset for which we will be adding a key. The order for the data doesn’t matter, we just need to add a key _id which should be unique.
# Read example data set
from pyspark.sql.functions import sum, expr, monotonically_increasing_id
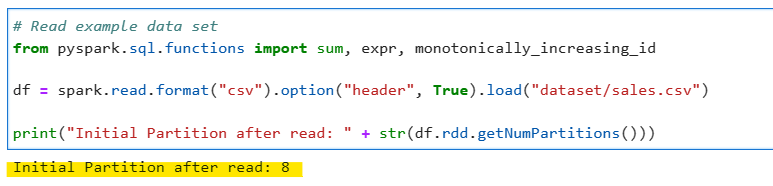
df = spark.read.format("csv").option("header", True).load("dataset/sales.csv")
print("Initial Partition after read: " + str(df.rdd.getNumPartitions()))
So without giving a second thought, lets use everyone’s favourite row_number() window function to add the key. We would be writing the data with noop for performance benchmarking.
# Use row_number() to generate ids
df_with_row_num = df.withColumn("_id", expr("row_number() over (order by null)"))
# Write the dataset in noop for performance benchmarking
df_with_row_num.write.format("noop").mode("overwrite").save()
Now, in background, it created two jobs and took 10 seconds to execute
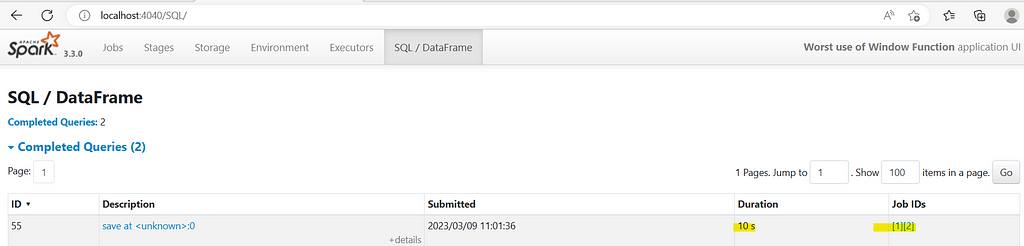
Now, if we expand the job number 2
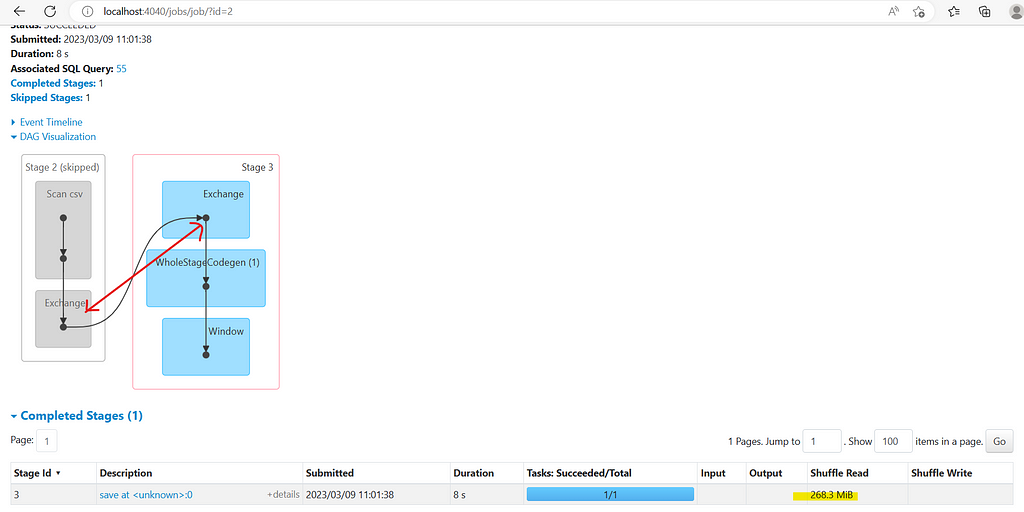
Did you notice something ? All data from 8 partitions are pulled into a single partition after Shuffle for sorting and sequencing. And by now we all know — un-necessary Shuffles are BAD.

Consider you are working on a Production System and all data for a huge SCD2 Dimension in pulled into a single partition — we will run into all sort of problems such as spillage, out of memory, GC issues, application lag etc.
So, what is the solution then ?
Possible SOLUTION
No one said the surrogate key to be sequential, the only requirement for it is to be unique. We can use distributed functions monotonically_increasing_id(), uuid() etc to create this key, they will ensure the unique feature but will not be sequential.
Lets use monotonically_increasing_id() to see the results
# Use Spark in-built monotonically_increasing_id to generate ids
df_with_incr_id = df.withColumn("_id", monotonically_increasing_id())
# Write the dataset in noop for performance benchmarking
df_with_incr_id.write.format("noop").mode("overwrite").save()
The job finished within 2 sec with only 1 job
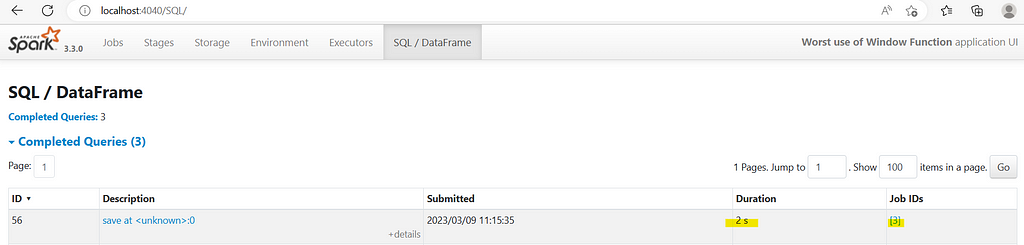
Lets expand the JOB 3
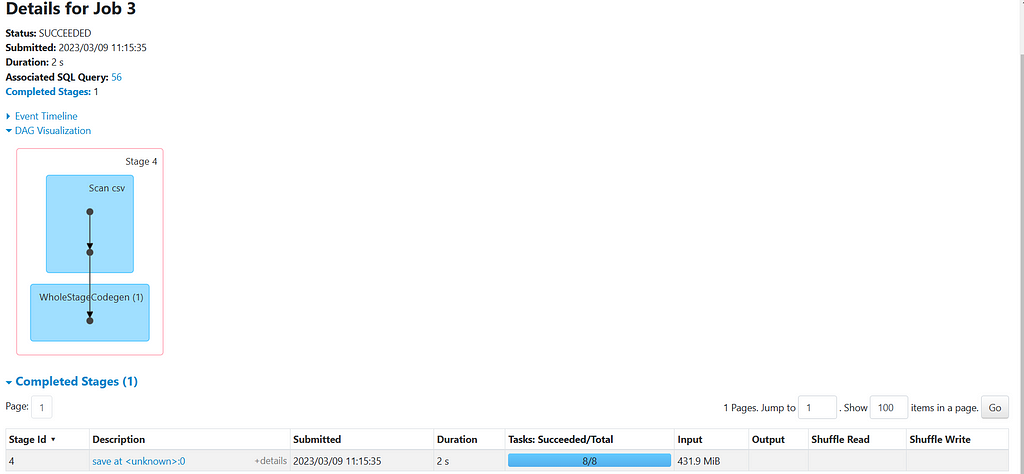
Wow, there is no shuffle and the data was process parallelly in all 8 partitions. So, if we check the partitions info.

Conclusion : We should always understand the use of functions and their background impacts. Not everything advertises it, but always “USE WITH CAUTION”
Make sure to Like and Subscribe.
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Wish to connect with me: https://topmate.io/subham_khandelwal
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/36_worst_use_of_window_func.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
PySpark — Worst use of Window Functions was originally published in Dev Genius on Medium, where people are continuing the conversation by highlighting and responding to this story.
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal