PySpark — Optimize Data Scanning exponentially
More often in Data Warehouse the data is partitioned on multiple levels such as Year > Month > Day, and the number of partitioned folders increase exponentially. To read data every time, Spark takes a lot of time and the reason behind this is scanning of data.
So, is there a way to minimize this scanning and increase the performance? Yes, there is a simple and very effective solution.

Lets consider our sales partitioned dataset, which is partitioned based on trx_year, trx_month and trx_date.
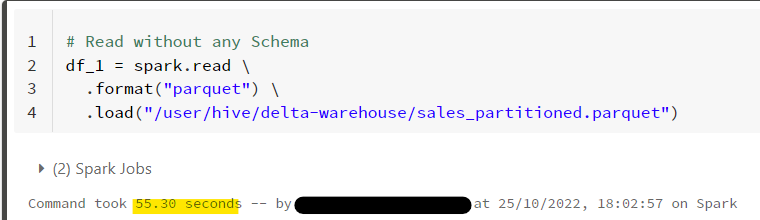
Test 1: Read data directly without specifying any schema. Keep a note on the timings
# Read without any Schema
df_1 = spark.read \
.format("parquet") \
.load("/user/hive/delta-warehouse/sales_partitioned.parquet")
Test 2: Read data specifying the Schema
# Read with Schema
_schema = "transacted_at timestamp, trx_id int, retailer_id int, description string, amount decimal(38,18), city_id int, trx_year int, trx_month int, trx_date int"
df_2 = spark.read \
.format("parquet") \
.schema(_schema) \
.load("/user/hive/delta-warehouse/sales_partitioned.parquet")

OK, So with schema it takes a little less time for scanning.
Test 3: We define the dataset as table for the first time and then we read from it.
# Register the data as table
_create_sql = """
CREATE TABLE default.sales_partitioned USING PARQUET LOCATION '/user/hive/delta-warehouse/sales_partitioned.parquet'
"""
_refresh_sql = """
MSCK repair table default.sales_partitioned
"""
# Run the SQL commands
spark.sql(_create_sql)
spark.sql(_refresh_sql)
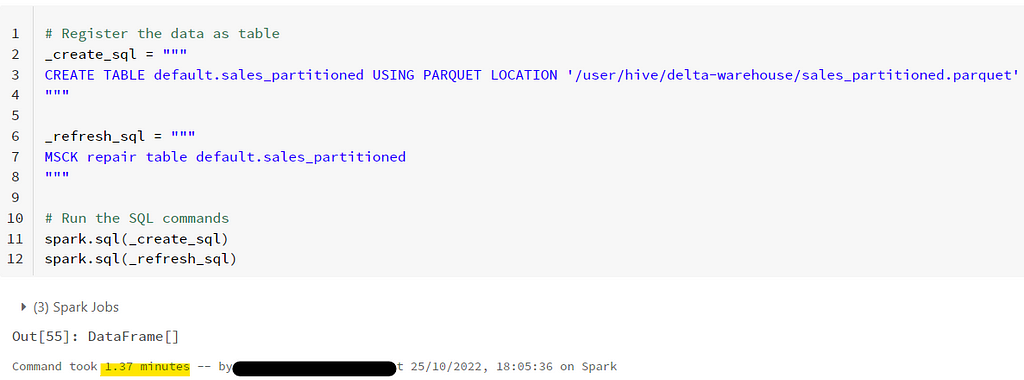
Registering the tables took time, as the data is scanned for all partitions and datatype. We can reduce this time as well specifying the schema in Create table command.
Now, lets read the data
# Read using the table schema
df_3 = spark.read.table("default.sales_partitioned")

Did you see the time? It decreased exponentially like Magic. Now, you can read any number of time from the table, the time for scanning would always remain negligible.
In case table data changes with background tasks and you need to read the updated data, then the MSCK REPAIR TABLE command must be ran to refresh the table.
Conclusion: We can reduce and optimize the scanning exponentially by registering the dataset as table for reads. In case that is not possible then always try to specify the schema beforehand.
Checkout my personal blog: https://urlit.me/blog/
Checkout the PySpark Medium Series: https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal