PySpark — Data Frame Joins on Multiple conditions
We often run into situations where we have to join two Spark Data Frames on multiple conditions and those conditions can be complex and may change as per requirement. We will work on a simple hack that will make our join conditions way much more effective and simpler to use.

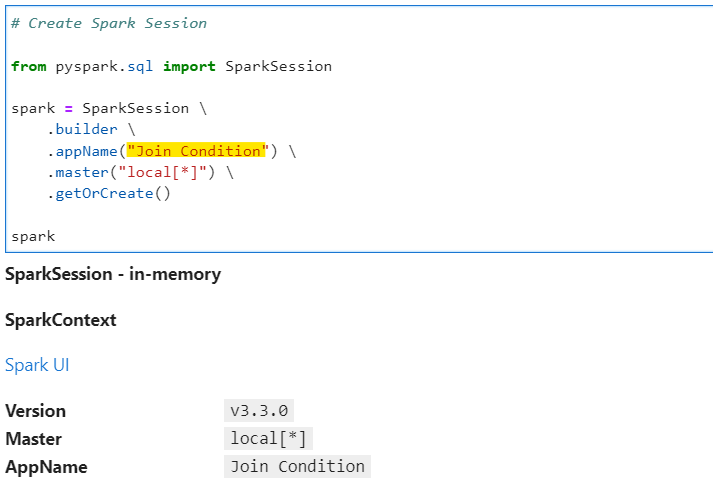
Generate a SparkSession to start.
# Create Spark Session
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Join Condition") \
.master("local[*]") \
.getOrCreate()
spark
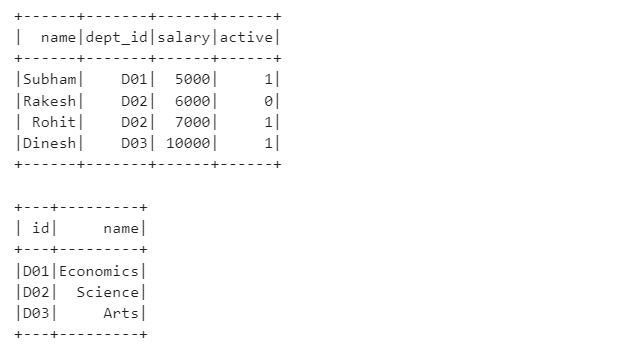
Now, lets create our employee and department data frames for explanation. Both data frames has department ids as common joining column.
# Create dataset
# Employee dataset
_emp_data = [
["Subham", "D01", 5000, 1],
["Rakesh", "D02", 6000, 0],
["Rohit", "D02", 7000, 1],
["Dinesh", "D03", 10000, 1]
]
# Employee schema
_emp_schema = ["name", "dept_id", "salary", "active"]
# Department dataset
_dept_data = [
["D01", "Economics"],
["D02", "Science"],
["D03", "Arts"]
]
# Department schema
_dept_schema = ["id", "name"]
# Create Employee and Department dataframes
# Employee Dataframe
df_emp = spark.createDataFrame(data = _emp_data, schema= _emp_schema)
df_emp.show()
# Department Dataframe
df_dept = spark.createDataFrame(data = _dept_data, schema= _dept_schema)
df_dept.show()
So to make things simpler we will consider few joining scenarios.
Condition 1: Join Employee and Department based on dept id and active record = 1
We will create a list with all joining condition and use the same while joining datasets.
# Create a list of conditions
join_cond = [df_emp.dept_id == df_dept.id, df_emp.active == 1]
df_join_1 = df_emp.join(df_dept, how="left_outer", on=join_cond)
df_join_1.show()
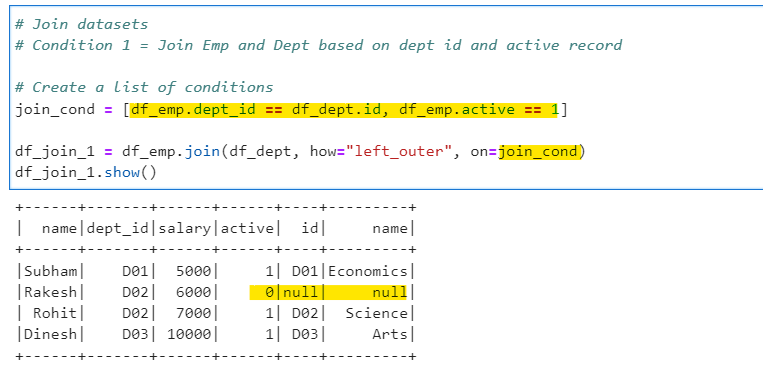
Note: All conditions mentioned in list automatically are treated as logical AND. So, the joining condition will transform in SQL to: df_emp.dept_id = df_dept.id and df_emp.active = 1
Looks cleaner and easy, Right ? Lets see some complex example now.
Condition 2: Join Employee and Department based on dept id and active record = 1 or salary > 5000
We will create a new list with join conditions specified.
# Create a list of conditions
join_cond = [df_emp.dept_id == df_dept.id, ((df_emp.active == 1) | (df_emp.salary > 5000))]
df_join_3 = df_emp.join(df_dept, how="left_outer", on=join_cond)
df_join_3.show()
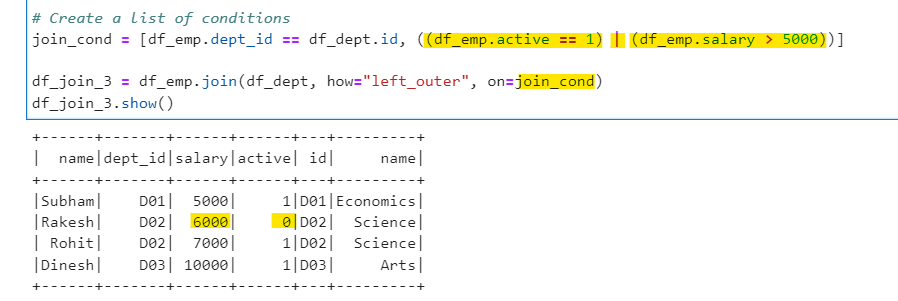
The logical OR (|) operator is mentioned in the condition. So, if we transform this to SQL: df_emp.dept_id = df_dept.id and ((df_emp.active = 1) or (df_emp.salary > 5000))
Note: The brackets “()”are very important if you are specifying more the one condition.
What if, we only need the first condition from the condition list (join_cond) ? See the next example.
Condition 3: Join Emp and Dept based on dept id and active record = 1
We can re-use the above join condition and list and use index of the list to specify the join conditions. And for first condition we use the index as 0 (i.e. df_emp.dept_id == df_dept.id)
df_join_2 = df_emp.join(df_dept, how="left_outer", on=join_cond[0])
df_join_2.show()
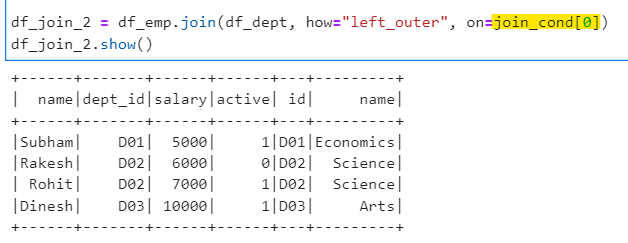
Since we ignored any other condition and joined based on dept id only, we have all four records from employee.
Is it possible to take first 2 from the condition list? Yes.
Condition 4: Join both datasets based of first 2 conditions — id and active = 1
# Joining condition
join_cond = [df_emp.dept_id == df_dept.id, df_emp.active == 1, df_emp.salary > 5000]
df_join_5 = df_emp.join(df_dept, how="left_outer", on=join_cond[:2])
df_join_5.show()
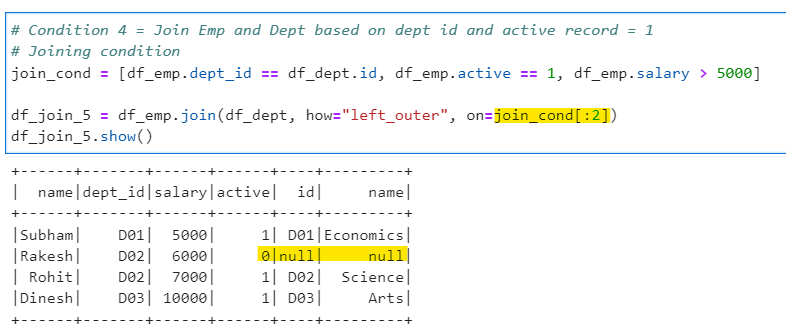
We are using Python indices to play with the required conditions for the joining the tables.
Conclusion: If we start using Python list to specify our join conditions, it becomes way lot simpler to maintain and understand our code. The code also becomes much more flexible to use.
Make sure to Like and Subscribe.
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/35_join_on_multiple_conditions.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal