PySpark — Create Spark Data Frame from API
We all have been in situations where we have to read data from API and load the same in Spark Data Frames for further operations.
Following is a small snippet of code which reads data from API and generates a Spark Data Frame.
Lets create a Python function to read API data.
# Create Python function to read data from API
import requests, json
def read_api(url: str):
normalized_data = dict()
data = requests.get(api_url).json()
normalized_data["_data"] = data # Normalize payload to handle array situtations
return json.dumps(normalized_data)
Following code generates Spark Data Frame from the json payload of the API response
api_url = r"https://api.coindesk.com/v1/bpi/currentprice.json"
# api_url = "https://api.wazirx.com/sapi/v1/tickers/24hr"
# Read data into Data Frame
# Create payload rdd
payload = json.loads(read_api(api_url))
payload_rdd = spark.sparkContext.parallelize([payload])
# Read from JSON
df = spark.read.json(payload_rdd)
df.select("_data").printSchema()
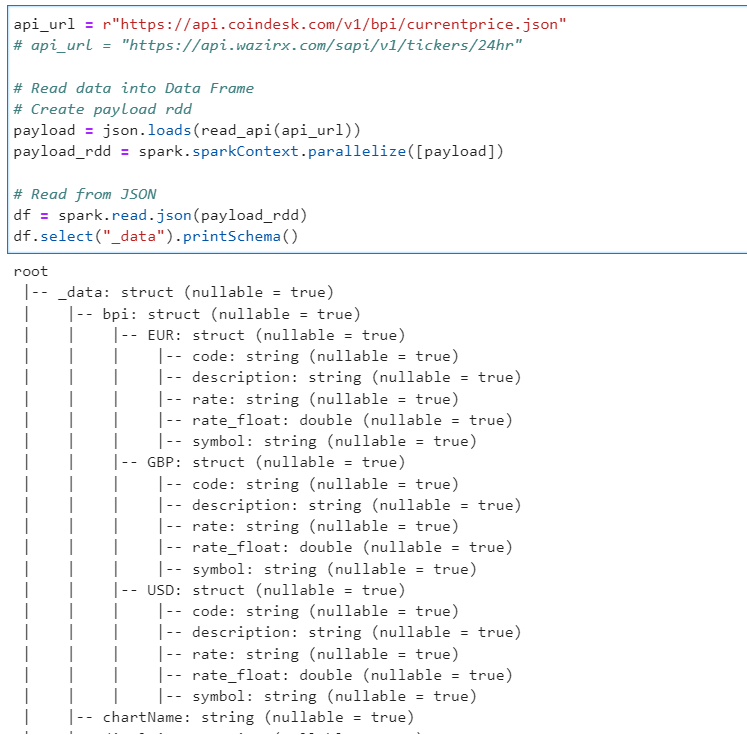
Now in case you want to expand the root element of the data frame
# Expand root element to read Struct Data
df.select("_data.*").show(truncate=False)
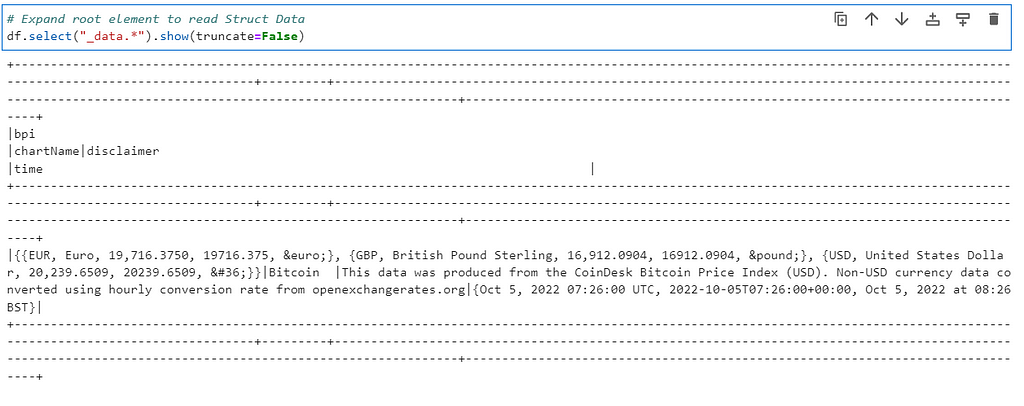
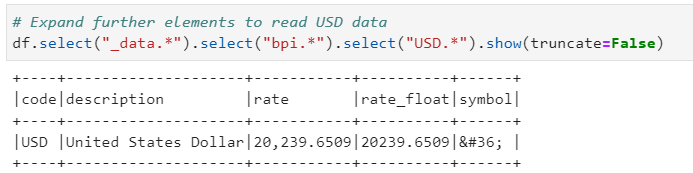
If you want to expand further to reach to particular element(in our case say USD)
# Expand further elements to read USD data
df.select("_data.*").select("bpi.*").select("USD.*").show(truncate=False)
We will see to expand such data dynamically(flatten json data) in further posts.
Checkout the iPython notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/3_create_df_from_api.ipynb
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal