PySpark — Distributed Broadcast Variable
Spark enables distributed immutable variables which can be shared across cluster efficiently without any function encapsulation and Broadcast variable is the best example of it.
The simplest way of using a variable is to mention it in a function/code and pass it along to task with the code, but it can be inefficient in case of large variables such as tables when those needs to be deserialized on worker nodes multiple times. Thus to remedy comes “Broadcast variables”.
Broadcast variables are shared and cached on every node instead of sending them with each tasks, which avoids serialization issue avoiding performance hits in case of large systems.
How can we use this functionality, lets checkout with a simple example.
For our use case we are supplying two broadcast variables — Department name and establishment year, which will be used in our Students data.
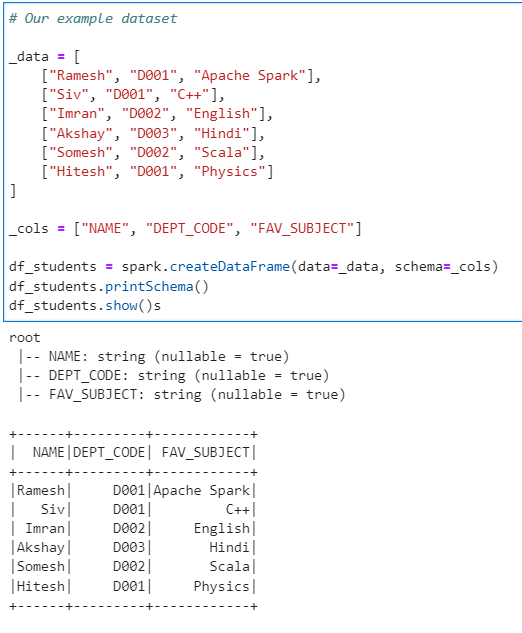
Lets generate our example dataset
# Our example dataset
_data = [
["Ramesh", "D001", "Apache Spark"],
["Siv", "D001", "C++"],
["Imran", "D002", "English"],
["Akshay", "D003", "Hindi"],
["Somesh", "D002", "Scala"],
["Hitesh", "D001", "Physics"]
]
_cols = ["NAME", "DEPT_CODE", "FAV_SUBJECT"]
df_students = spark.createDataFrame(data=_data, schema=_cols)
df_students.printSchema()
df_students.show()
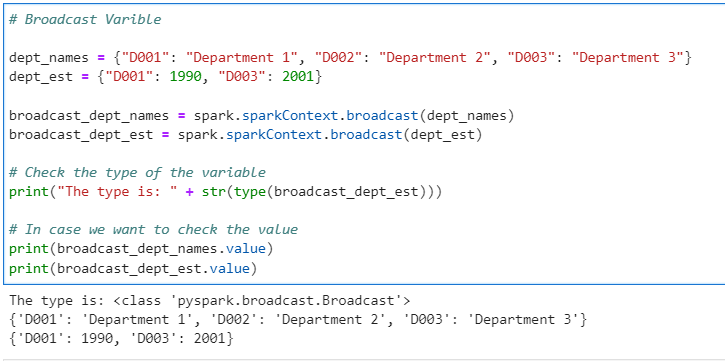
Our Broadcast variables
# Broadcast Variable
dept_names = {"D001": "Department 1", "D002": "Department 2", "D003": "Department 3"}
dept_est = {"D001": 1990, "D003": 2001}
broadcast_dept_names = spark.sparkContext.broadcast(dept_names)
broadcast_dept_est = spark.sparkContext.broadcast(dept_est)
# Check the type of the variable
print("The type is: " + str(type(broadcast_dept_est)))
# In case we want to check the value
print(broadcast_dept_names.value)
print(broadcast_dept_est.value)
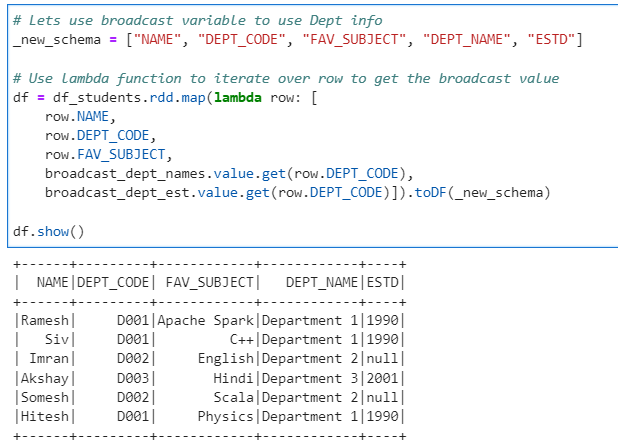
Now, lets use the broadcast variable to get data for out Student’s data frame
# Lets use broadcast variable to use Dept info
_new_schema = ["NAME", "DEPT_CODE", "FAV_SUBJECT", "DEPT_NAME", "ESTD"]
# Use lambda function to iterate over row to get the broadcast value
df = df_students.rdd.map(lambda row: [
row.NAME,
row.DEPT_CODE,
row.FAV_SUBJECT,
broadcast_dept_names.value.get(row.DEPT_CODE),
broadcast_dept_est.value.get(row.DEPT_CODE)]).toDF(_new_schema)
df.show()
Default size for Broadcast variable is 4M which can be controlled through spark.broadcast.blockSize parameter.
Current example might not justify the use case of the Broadcast variable, but consider you are dealing with a big machine learning model that needs to be distributed for performance benefit.
This example very well gives you an idea of how to use it.
Checkout iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/19_broadcast_variables.ipynb
Checkout my personal blog — https://urlit.me/blog/
Checkout PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal