PySpark — Flatten JSON/Struct Data Frame dynamically
We always have use cases where we have to flatten the complex JSON/Struct Data Frame into flattened simple Data Frame just like the example below:
example.this.that => example_this_that

Following code snippet does the exact job dynamically. No manual effort required to expand the data structure or to determine the schema.
Lets first create an example Data Frame for the job
# Lets create an Example Data Frame to hold JSON data
# Example Data Frame with column having JSON data
_data = [
['EMP001', '{"dept" : "account", "fname": "Ramesh", "lname": "Singh", "skills": ["excel", "tally", "word"]}'],
['EMP002', '{"dept" : "sales", "fname": "Siv", "lname": "Kumar", "skills": ["biking", "sales"]}'],
['EMP003', '{"dept" : "hr", "fname": "MS Raghvan", "skills": ["communication", "soft-skills"], "hobbies" : {"cycling": "expert", "computers":"basic"}}']
]
# Columns for the data
_cols = ['emp_no', 'raw_data']
# Lets create the raw Data Frame
df_raw = spark.createDataFrame(data = _data, schema = _cols)
# Determine the schema of the JSON payload from the column
json_schema_df = spark.read.json(df_raw.rdd.map(lambda row: row.raw_data))
json_schema = json_schema_df.schema
# Apply the schema to payload to read the data
from pyspark.sql.functions import from_json
df_details = df_raw.withColumn("emp_details", from_json(df_raw["raw_data"], json_schema)).drop("raw_data")
df_details.show(10, False)
df_details.printSchema()

Create Python function to do the magic
# Python function to flatten the data dynamically
from pyspark.sql import DataFrame
# Create outer method to return the flattened Data Frame
def flatten_json_df(_df: DataFrame) -> DataFrame:
# List to hold the dynamically generated column names
flattened_col_list = []
# Inner method to iterate over Data Frame to generate the column list
def get_flattened_cols(df: DataFrame, struct_col: str = None) -> None:
for col in df.columns:
if df.schema[col].dataType.typeName() != 'struct':
if struct_col is None:
flattened_col_list.append(f"{col} as {col.replace('.','_')}")
else:
t = struct_col + "." + col
flattened_col_list.append(f"{t} as {t.replace('.','_')}")
else:
chained_col = struct_col +"."+ col if struct_col is not None else col
get_flattened_cols(df.select(col+".*"), chained_col)
# Call the inner Method
get_flattened_cols(_df)
# Return the flattened Data Frame
return _df.selectExpr(flattened_col_list)
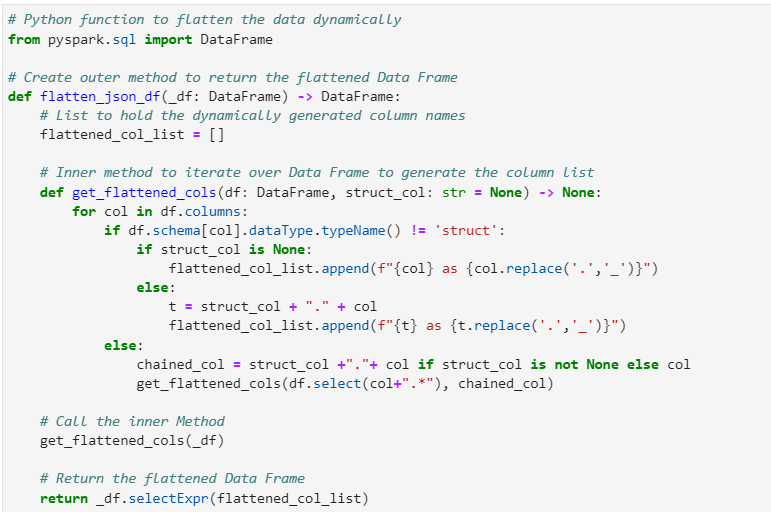
Now, lets run our example Data Frame against the Python Method to get the flattened Data Frame
# Generate the flattened DF
flattened_df = flatten_json_df(df_details)
flattened_df.show(10)
# Print Schema
flattened_df.printSchema()
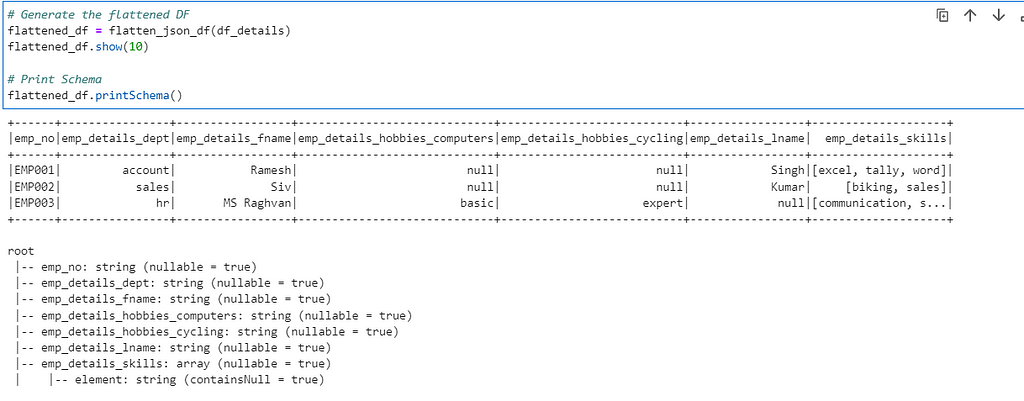
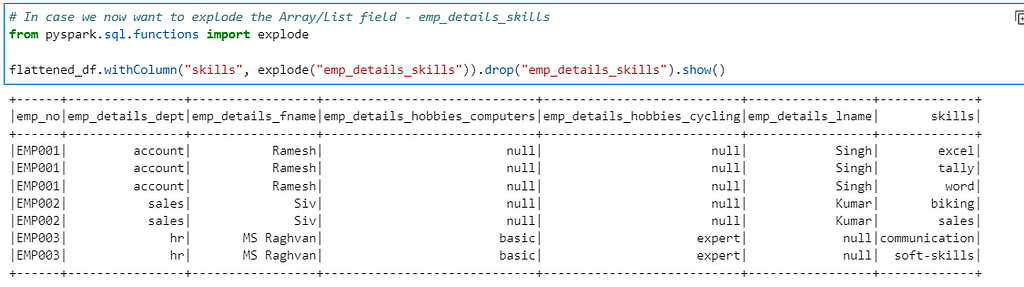
In case we want to explode the Array data further
# In case we now want to explode the Array/List field - emp_details_skills
from pyspark.sql.functions import explode
flattened_df.withColumn("skills", explode("emp_details_skills")).drop("emp_details_skills").show()
Checkout the complete iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/5_flatten_json_data_dynamically.ipynb
Checkout the EaseWithApacheSpark series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal