PySpark — Implementing Persisting Metastore
Metastore is a central repository that is used to manage relational objects such as database, tables, views etc. Apache Hive, Impala, Spark, Presto etc. implements the same in order to maintain the metadata.
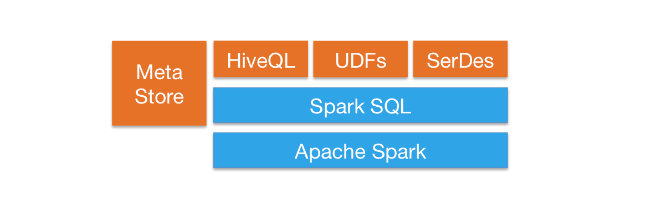
Spark basically allows only two type of catalog Implementation “in-memory” and “hive”. This can be verified with the following configuration parameter.
spark.sql.catalogImplementation
In-memory implementation only persists for the session, once the session is stopped metadata is remove along with it. In-order to persist our relational metadata, we have to change our catalog implementation to hive.
But, what if we don’t have Hive Metastore implemented? Can’t we implement persisting relational entities? The answer is — Yes we can. In order to achieve the same, Spark uses default Apache Derby to create a metastore_db in the current working directory.
Now, how to we enable the same? Lets check that out with an example.
Default spark catalog Implementation.
# Validate CatalogImplementation
spark.conf.get("spark.sql.catalogImplementation")

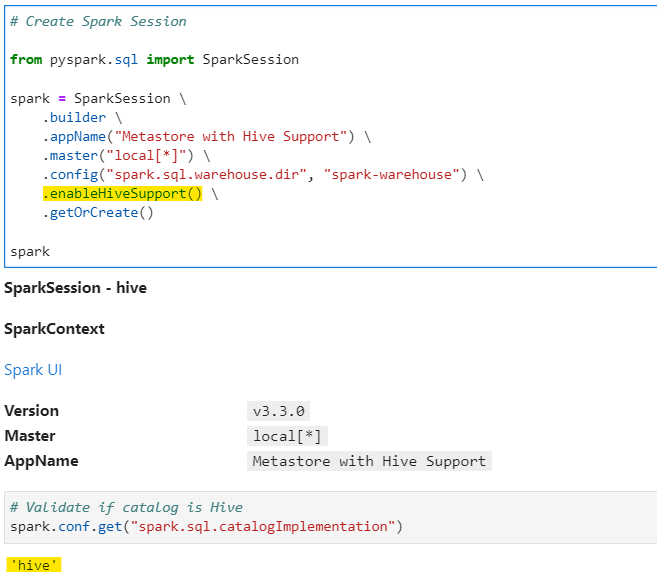
Lets create a new SparkSession with Hive catalog implementation and to achieve that we add enablehivesupport() while creating SparkSession object.
# Create Spark Session
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Metastore with Hive Support") \
.master("local[*]") \
.config("spark.sql.warehouse.dir", "spark-warehouse") \
.enableHiveSupport() \
.getOrCreate()
spark
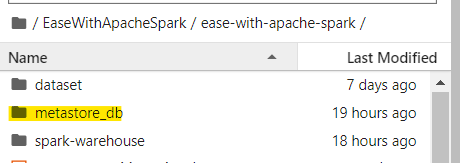
Once the SparkSession object is created we can find a metastore_db folder created in default working directory to persist the metadata information. This folder stores all the required metadata.
By default path specified to spark.sql.warehouse.dir is used to store data for the in-house managed tables. For external tables location needs to specified while creating the same.
Now, lets quickly create a table to checkout our metastore.
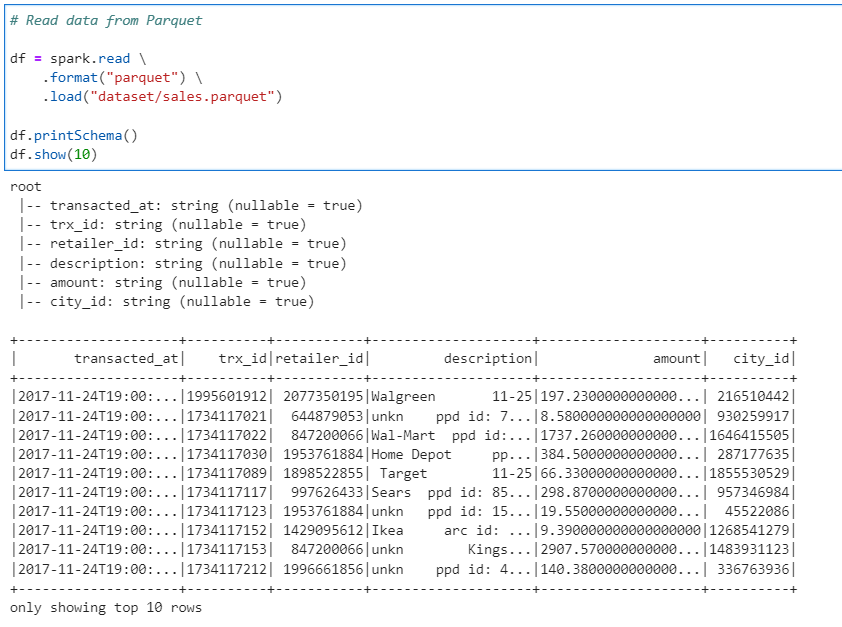
# Read data from Parquet
df = spark.read \
.format("parquet") \
.load("dataset/sales.parquet")
df.printSchema()
df.show(10)
Write the dataset as managed table
# Write dataframe as table
df.write.saveAsTable("sales_managed")
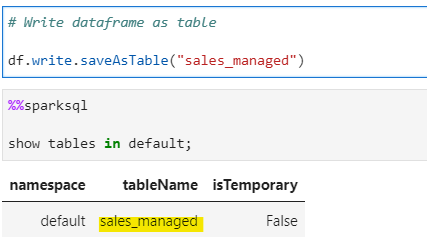
Now, if we stop and create a new SparkSession with same default working directory, we will still be able to access all table metadata, since it is permanent/persisted.
%%sparksql
select * from sales_managed limit 10;
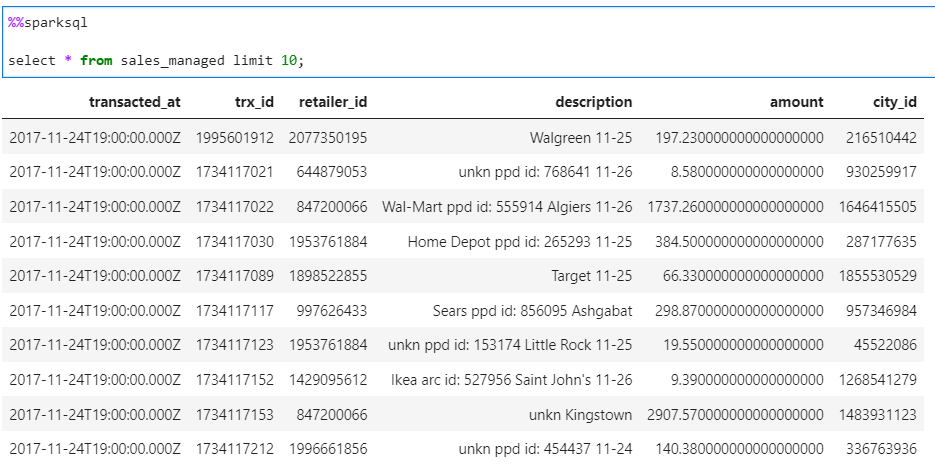
Conclusion: The benefit for metastore implementation comes into play when we have to read the a dataset and we have performance hits due to data scanning.
Checkout this article to understand more on data scanning — https://urlit.me/blog/pyspark-optimize-data-scanning-exponentially/
And now we can directly read data directly — as metastore will store the table name, metadata/schema and path of the table.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/26_metastore_in_pyspark.ipynb
Checkout my Personal blog — https://urlit.me/blog/
Checkout the PySpark Series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal