PySpark — The Effects of Multiline
Optimizations are all around us, few of them are hidden in small parameter changes and few in the way we deal with data. Today, we will understand The effects of Multiline in files with Apache Spark.

To explore the effect, we will read same Orders JSON file with approximate 10,50,000 order line items — one in formatted Multiline
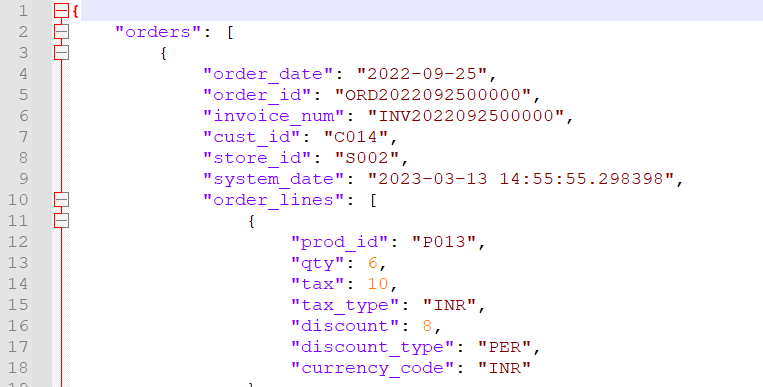
and another with compressed Single line.

Before we read and analyse lets have a quick look in file sizes as well.

For our demonstration we will read the files and explode orders data and write into parquet format.
With Multiline File
Lets read the file with multiLine option as True
# Lets read the Multiline JSON
from pyspark.sql.functions import explode
df_json_multiline = spark \
.read \
.option("multiLine", True) \
.format("json") \
.load("dataset/orders_json/orders_json_multiline.json")
df_json_multiline.printSchema()
# Lets perform explode operation
df_temp = df_json_multiline.withColumn("orders", explode("orders"))
# Write for performance benchmarking
df_temp.write.format("parquet").mode("overwrite").save("dataset/orders_json/output/parquet_1")
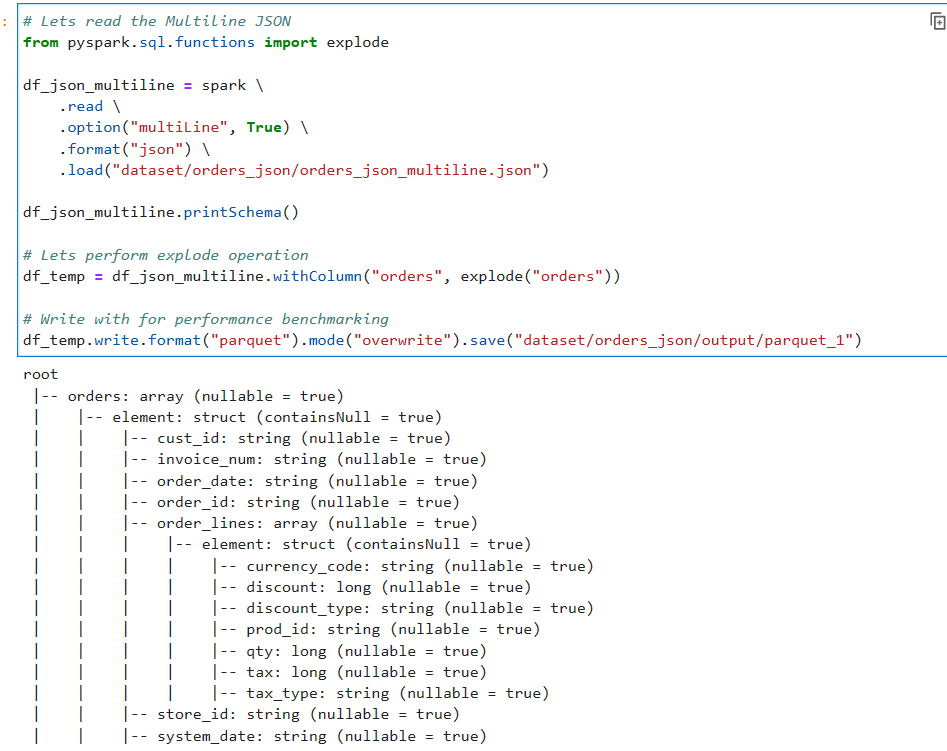
Now, if we check the partition information
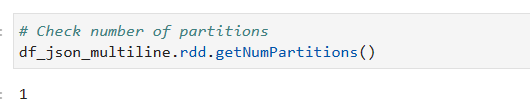
It is evident that the whole data is processed using single partition. Lets check Spark UI to understand more.


Lets repeat the same process but this time with the Single line file.
With Single Line File
Read the compressed file with multiLine set as False
# Lets read the Multiline JSON
from pyspark.sql.functions import explode
df_json_singleline = spark \
.read \
.option("multiLine", False) \
.format("json") \
.load("dataset/orders_json/orders_json_singleline.json")
df_json_singleline.printSchema()
# Lets perform explode operation
df_temp = df_json_singleline.withColumn("orders", explode("orders"))
# Write for performance benchmarking
df_temp.write.format("parquet").mode("overwrite").save("dataset/orders_json/output/parquet_2")
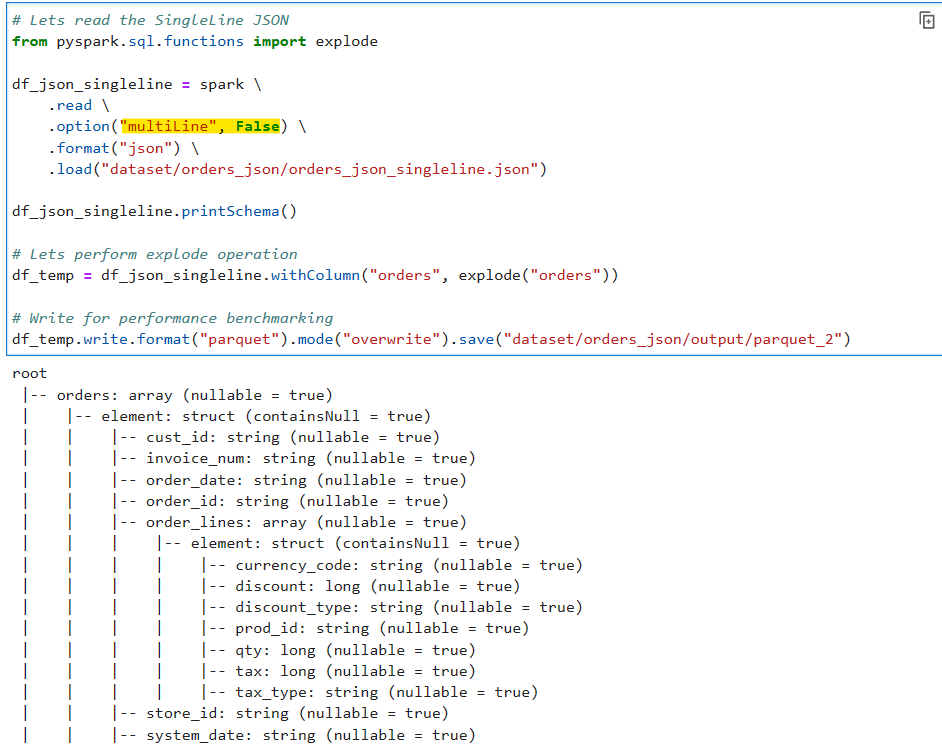
Now, if we check the partition information
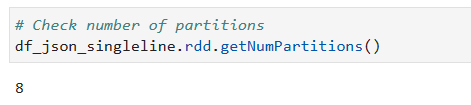
OK, we see some parallelization happening here. Lets check Spark UI to understand more.


We see Spark did some parallel processing here, reducing the overall time. So, what happened in the background ?
Spark splits the file in multiple tasks and reads them all together.

All tasks read the file parallelly, but only one of them is responsible for splitting/managing and it automatically optimizes the workload.
And this is not possible with multiline files.
Conclusion: Spark can optimize file reading automatically for non-multiline files. It is recommended to avoid multiline file as much as possible.
But, there are certain scenarios where a multiline file can be beneficial, which we will discuss in later article. Till then Keep Learning, Keep Growing and Keep Sharing❤️
Make sure to Like and Subscribe.
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Wish to connect with me: https://topmate.io/subham_khandelwal
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/37_the_effect_of_multiline.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
PySpark — The Effects of Multiline was originally published in Dev Genius on Medium, where people are continuing the conversation by highlighting and responding to this story.
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal