PySpark — The Basics of Structured Streaming
Spark Structured Streaming is a streaming framework built up on Spark SQL Engine. It leverages the existing APIs framework to enhance the power of Streaming Computation.
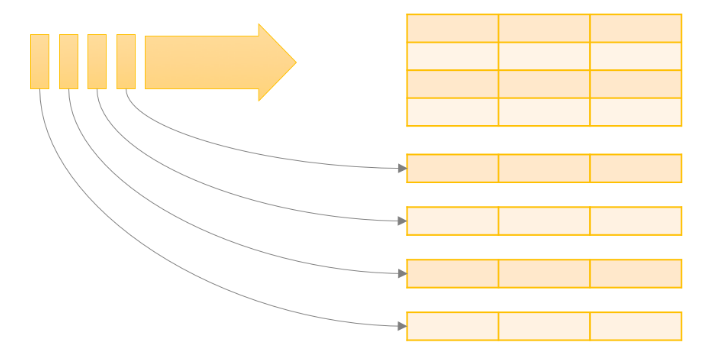
So, if you are familiar with DataFrame, Dataset and SQL on Spark, this one will be easy. The Structured Streaming framework can be assumed as micro batch framework which appends data in the end of the table continuously. However, with a small twist to it.
To start and keep it simple, we can break the Structured Streaming into 4 parts — What, How, When and Where ? If you have answer for all 4 then the job is done.
Lets understand all 4, one by one.
What: simply means what is your Input Source? Spark supports the following as Input Sources:
- Streaming Input sources such as Kafka, Azure EventHub, Kinesis etc.
- Files systems such as HDFS, S3 etc.
- Sockets
How: simply means how are you processing the data. It involves the transformations(same as batch but with few restrictions) and the Output mode for the sink. Spark supports the following Output modes:
- Append: Adds new records
- Update: Updates changed records
- Complete: Overwrite all records
Not all output sinks supports all Output methods. We will discuss all these when we run our examples.
When: basically refers to the triggers for the streaming pipeline. It defines how the pipeline will trigger.
- Processing Time: will wait for the time given before trigger
- Once: will trigger only one time processing all data
Where: defines the output sink where the data will be displayed/stored. Few supported sinks:
- Streaming Sources such as Kafka
- Almost all file formats
- Memory Sink — holds the output in memory
- Console Sink — displays the output in console
- ForEach Sink — run computation for each record.
Currently all this might sound a bit new or weird, but in upcoming posts we will go through all of them with examples.
For more details checkout the Spark documentation — https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Checkout my personal blog — https://urlit.me/blog/
Checkout PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal