PySpark — Structured Streaming Read from Sockets
Spark Structured Streaming is gaining its popularity due to many out-of-box features. It leverages the existing Spark APIs framework to enhance the power of Streaming computations.

Spark executes small micro-batches in loop to achieve the streaming use case. A background task generates the execution plan similar to batch execution and keeps on iterating over the same as micro-batches.
Still have doubts, checkout PySpark — The Basics of Structured Streaming for quick refresh on Spark Structured Streaming basics.
For beginning, we will be reading data from a socket using Spark Structured Streaming in real-time to find out the count of each word posted in string. Very basic example to start with to understand the basic concepts for Spark Streaming.
As usual we will start with creating a SparkSession
# Create the Spark Session
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Streaming Socket Word Count") \
.master("local[*]") \
.getOrCreate()
spark

Now, to read the streaming data — create a DataFrameStreamReader (streaming_df) dataframe
# Create the streaming dataframe to read from socket
# Sockets are not recommended for Production applications is only for debugging and testing applications
streaming_df = spark.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", "9999") \
.load()
Check the schema
# Check the schema
streaming_df.printSchema()

As the socket will only push string data, we have only one column value with datatype as String.
Split the string and explode to create a dataframe with words
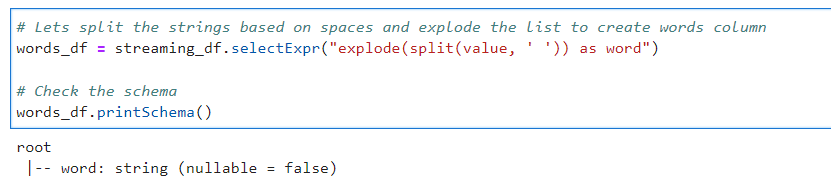
# Lets split the strings based on spaces and explode the list to create words column
words_df = streaming_df.selectExpr("explode(split(value, ' ')) as word")
# Check the schema
words_df.printSchema()
Now, we can aggregate on the words dataframe to find the count of individaul words.
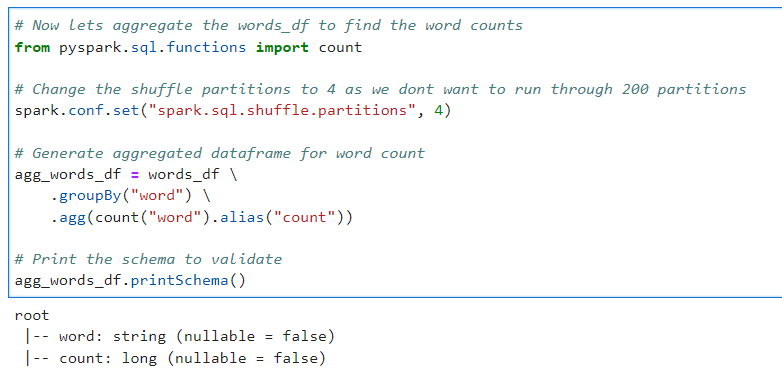
# Now lets aggregate the words_df to find the word counts
from pyspark.sql.functions import count
# Change the shuffle partitions to 4 as we dont want to run through 200 partitions
spark.conf.set("spark.sql.shuffle.partitions", 4)
# Generate aggregated dataframe for word count
agg_words_df = words_df \
.groupBy("word") \
.agg(count("word").alias("count"))
# Print the schema to validate
agg_words_df.printSchema()
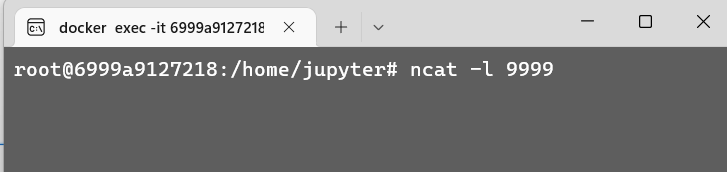
Before we start the application, open a terminal to attach port 9999 to send data.
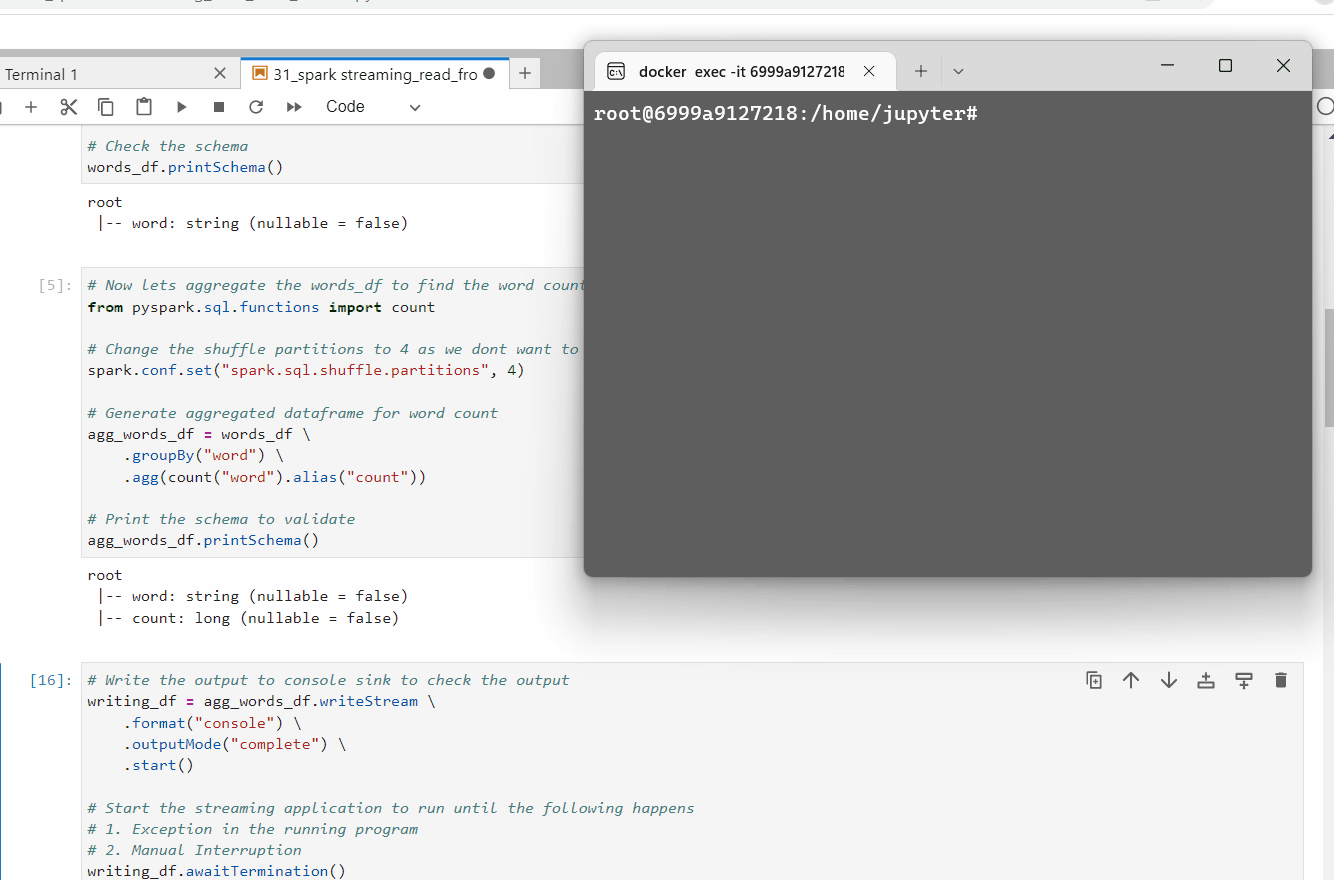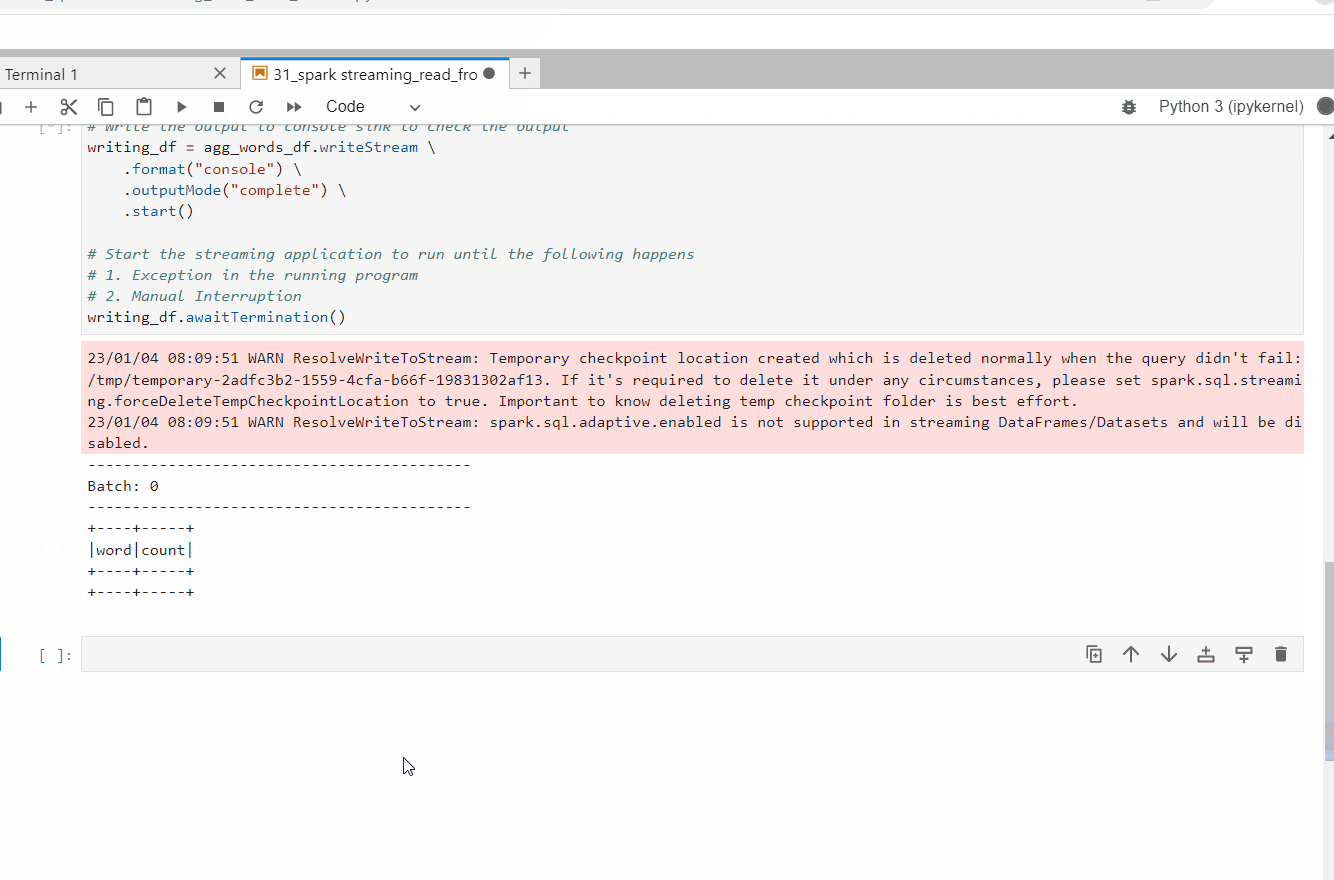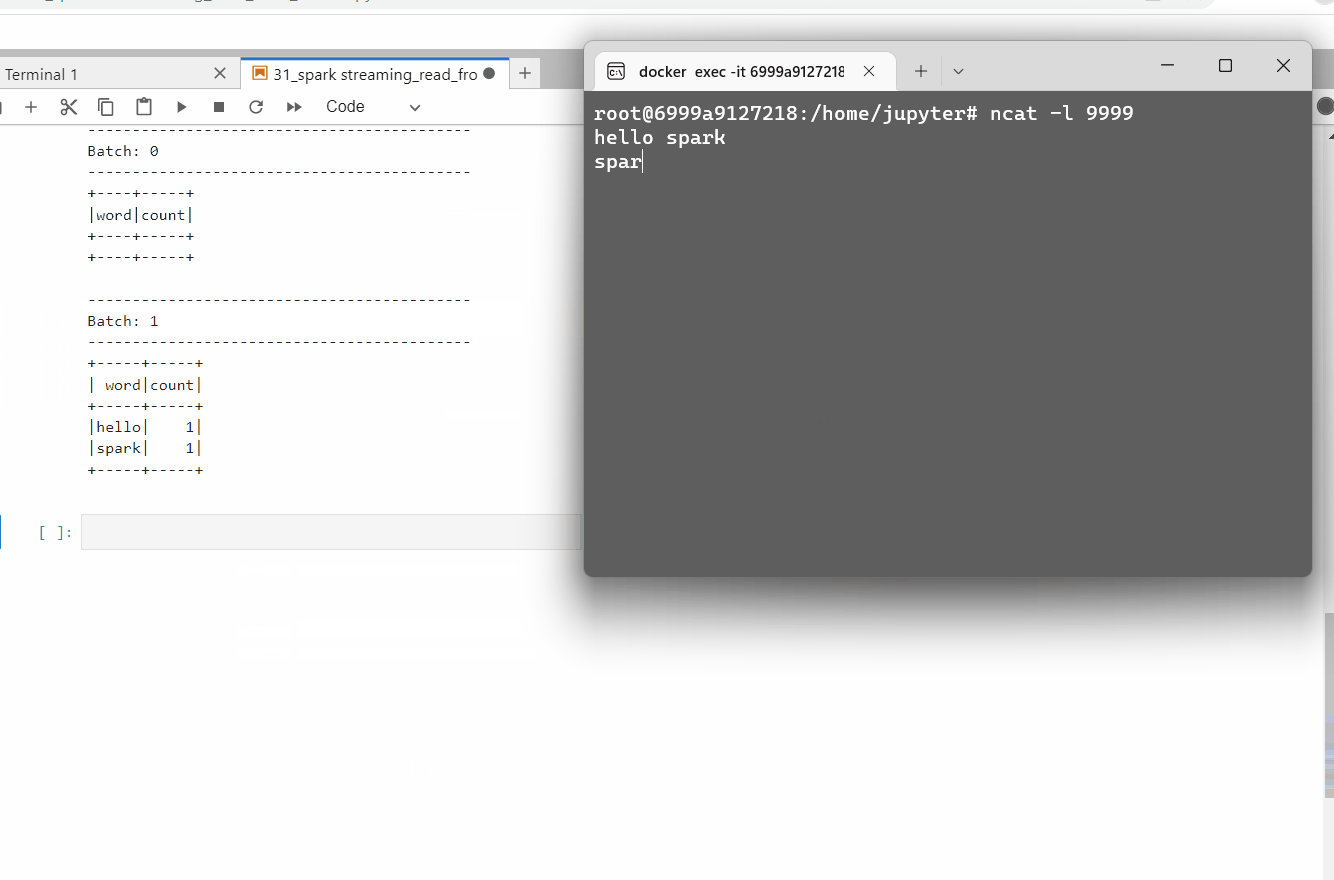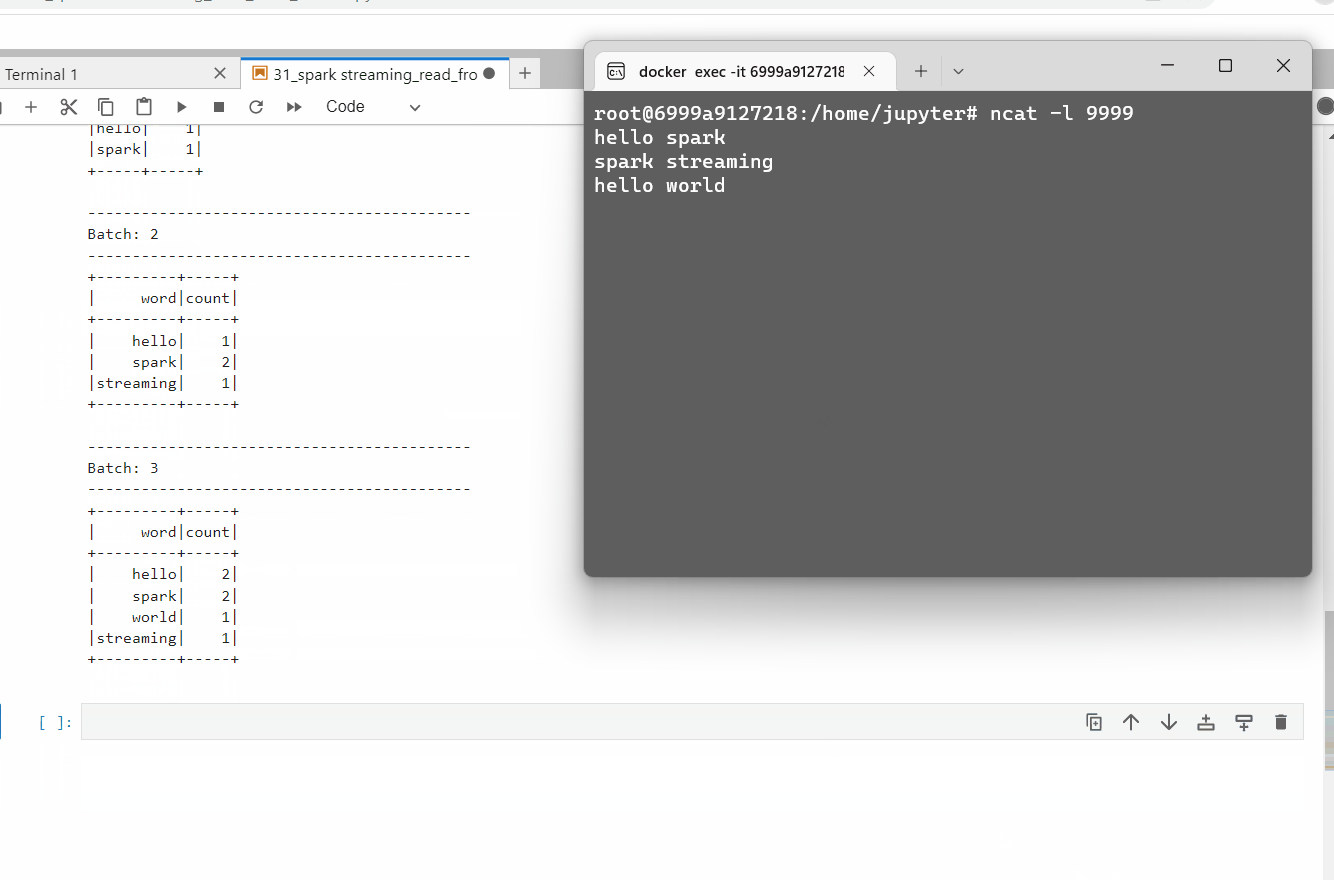
Finally we will choose the sink as console and outputMode as complete.
# Write the output to console sink to check the output
writing_df = agg_words_df.writeStream \
.format("console") \
.outputMode("update") \
.start()
# Start the streaming application to run until the following happens
# 1. Exception in the running program
# 2. Manual Interruption
writing_df.awaitTermination()
What if we chose, the outputMode as update
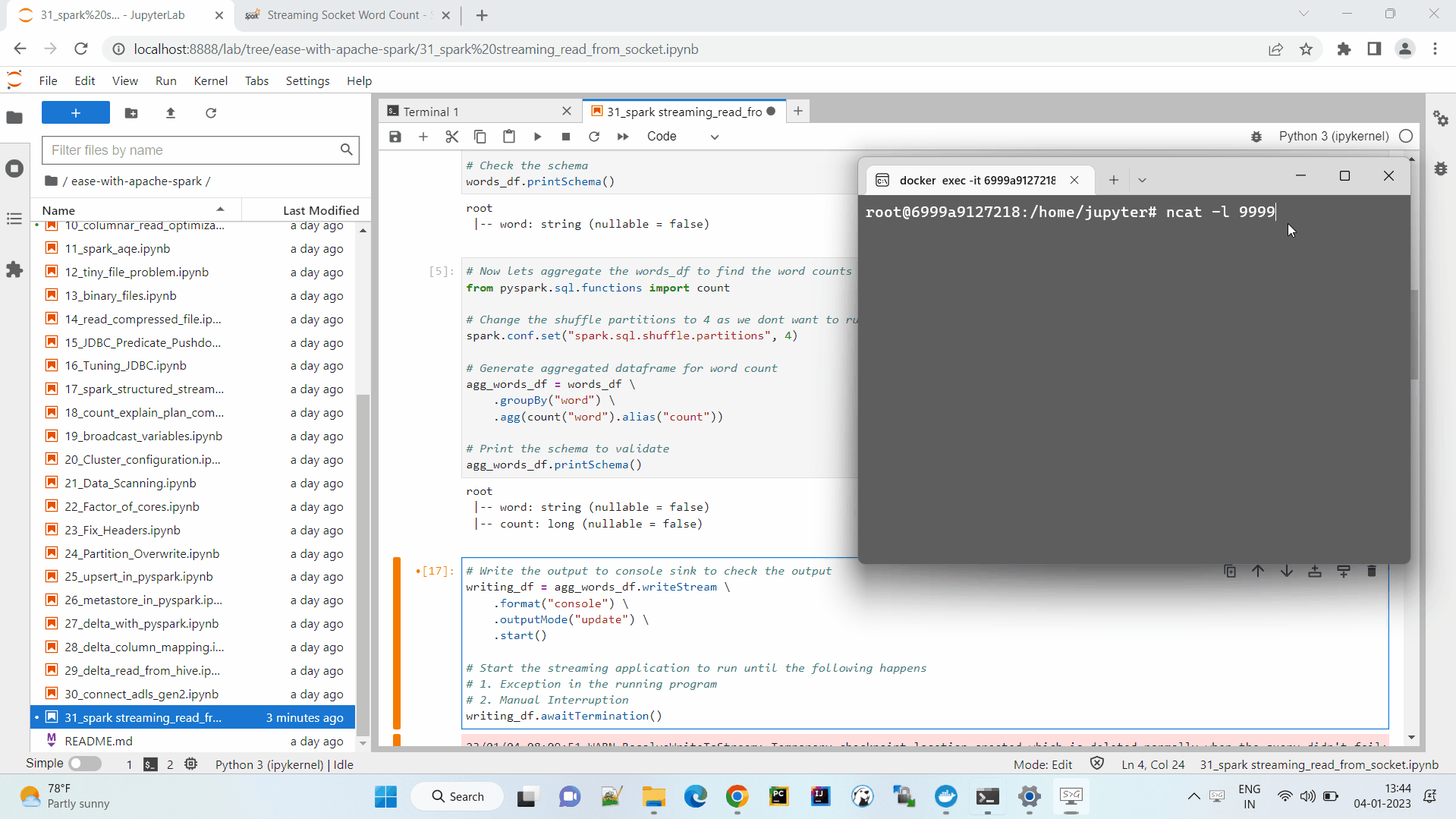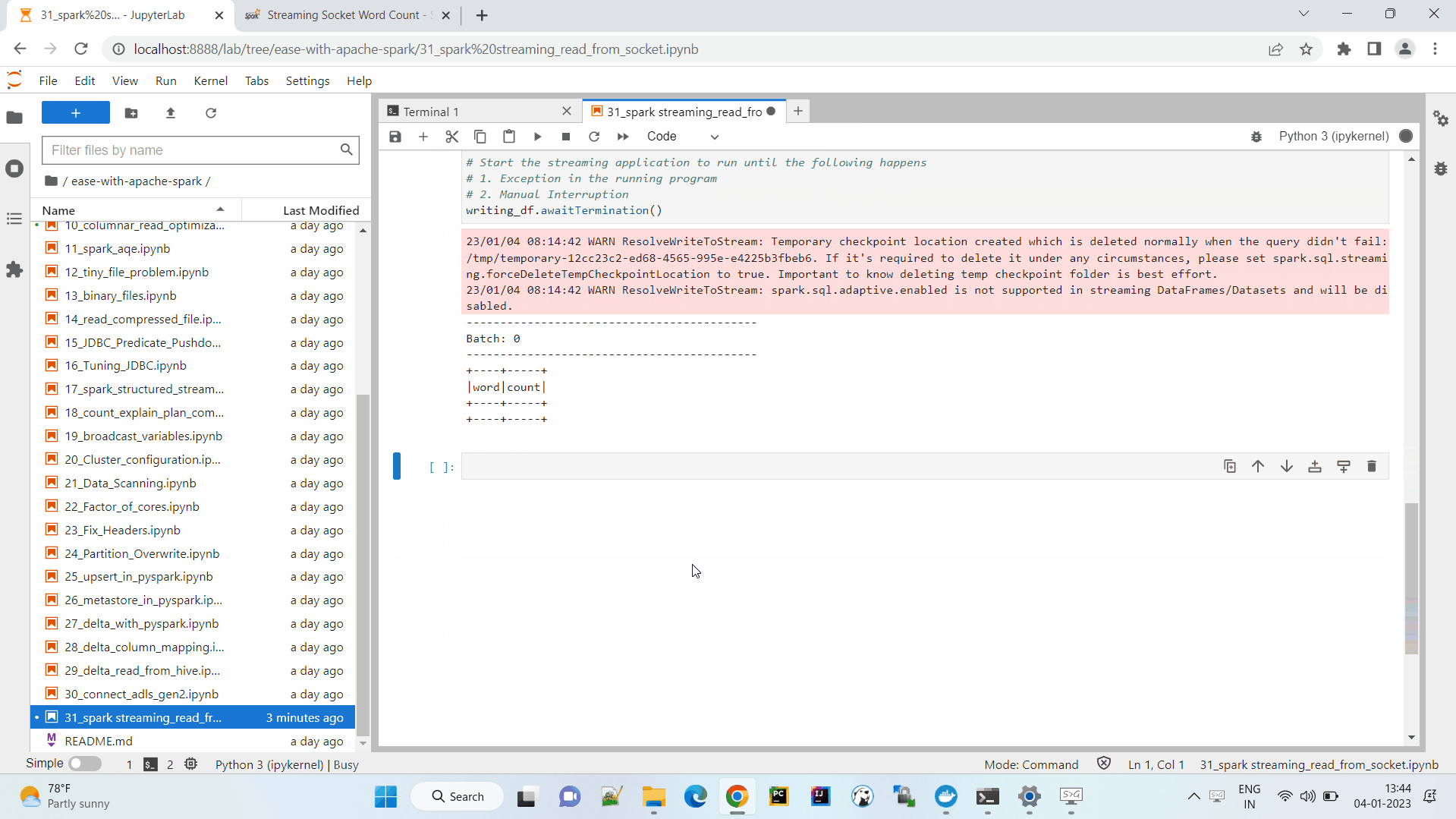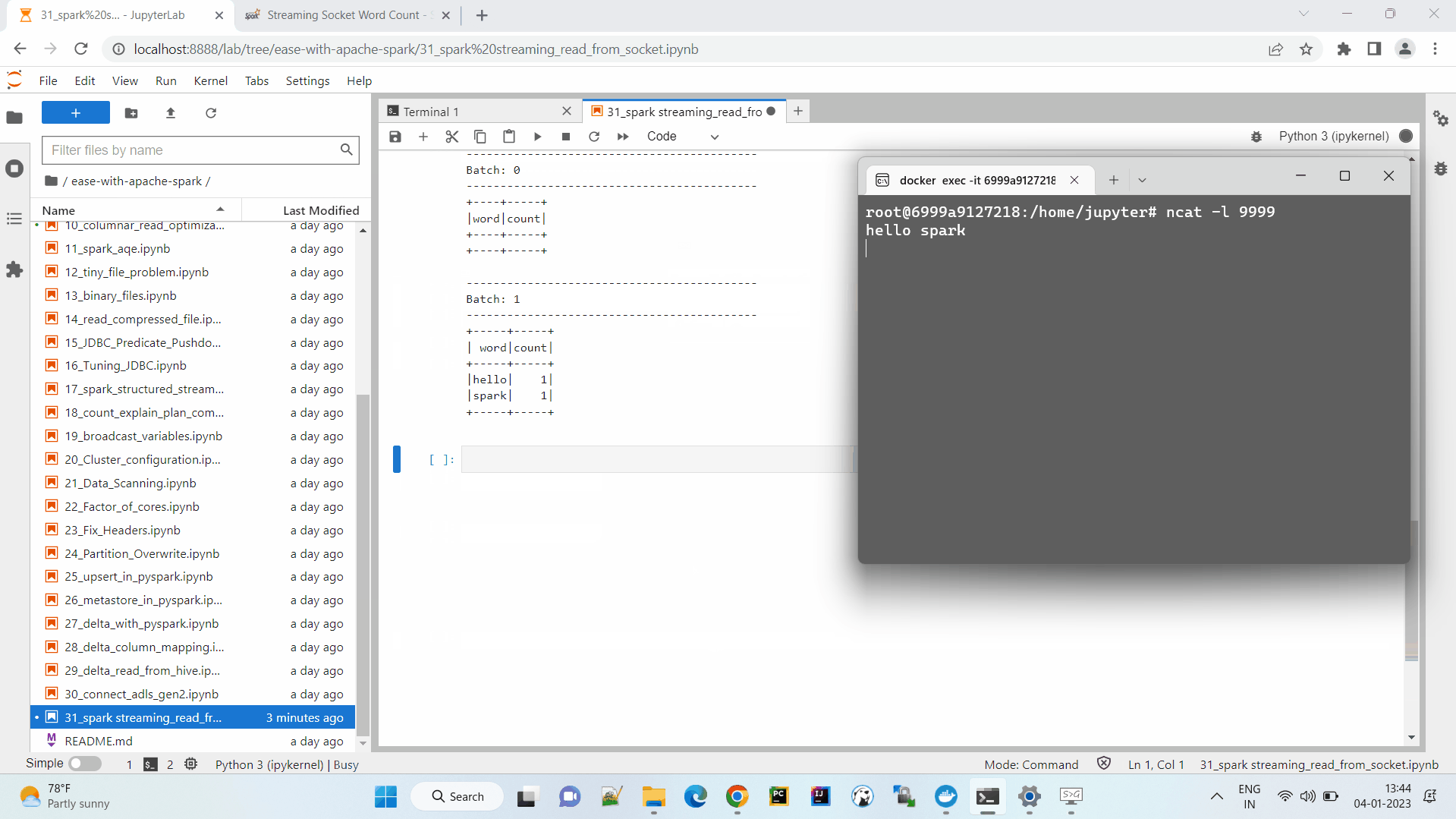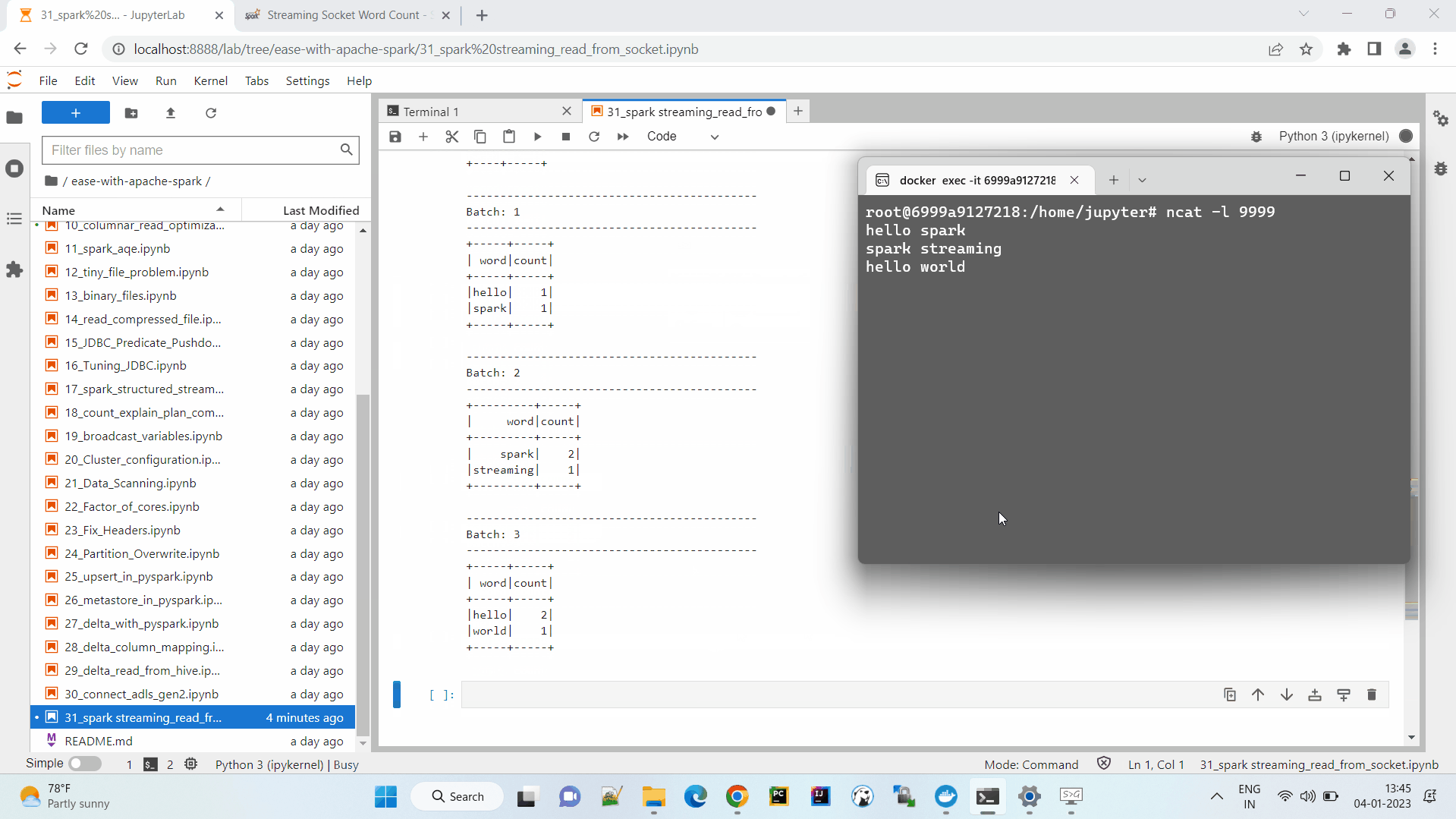
Append mode will not work. Spark will throw an error as it doesn’t allow to append results for aggregated calculation.
And to justify that in background Spark run small micro-batches, checkout the Spark UI.
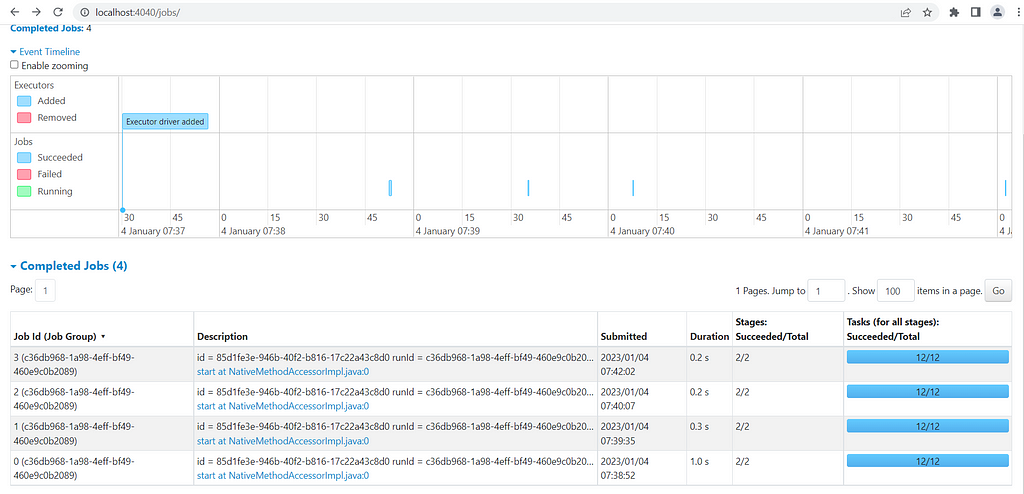
Its evident we can easily write Streaming applications with a very minor changes in batch execution code. We will cover more complex and important use-cases in coming posts.
In case ncat is not installed, run in linux — apt-get install -y ncat
Checkout Structured Streaming basics — https://urlit.me/blog/pyspark-the-basics-of-structured-streaming/
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/31_spark%20streaming_read_from_socket.ipynb
Checkout the docker images to quickly start— https://github.com/subhamkharwal/docker-images
Checkout my Personal blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://medium.com/@subhamkharwal/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal