PySpark — Read Compressed gzip files
Spark natively supports reading compressed gzip files into data frames directly. We have to specify the compression option accordingly to make it work.
But, there is a catch to it. Spark uses only a single core to read the whole gzip file, thus there is no distribution or parallelization. In case the gzip file is larger in size, there can be Out of memory errors.
Lets check that with an example. We will read the sales.csv.gz file
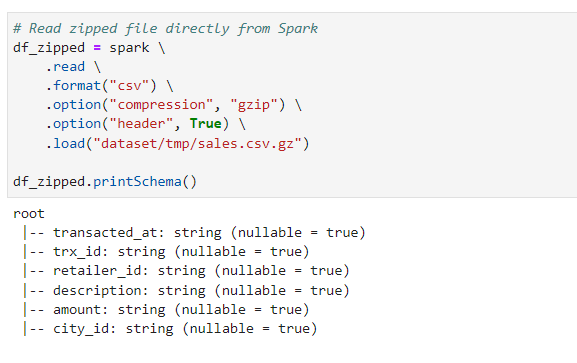
# Read zipped file directly from Spark
df_zipped = spark \
.read \
.format("csv") \
.option("compression", "gzip") \
.option("header", True) \
.load("dataset/tmp/sales.csv.gz")
df_zipped.printSchema()
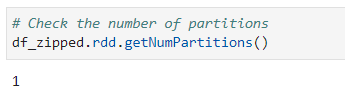
Now, if we check the distribution
# Check the number of partitions
df_zipped.rdd.getNumPartitions()
So, what is the best possible solution: The answer is simple — In case we have larger gzip/dataset which can cause memory errors, then just unzip it and then read in data frame.
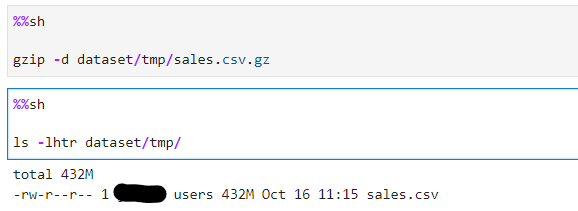
%%sh
gzip -d dataset/tmp/sales.csv.gz
ls -lhtr dataset/tmp/
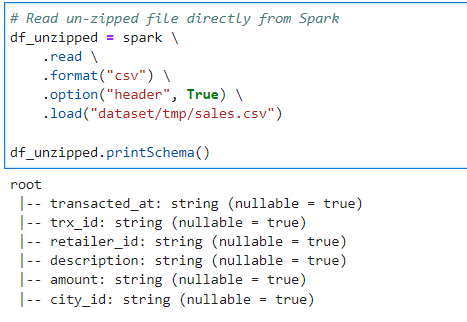
Read the un-zipped file
# Read un-zipped file directly from Spark
df_unzipped = spark \
.read \
.format("csv") \
.option("header", True) \
.load("dataset/tmp/sales.csv")
df_unzipped.printSchema()
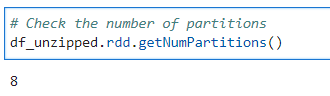
Checking the distribution
# Check the number of partitions
df_unzipped.rdd.getNumPartitions()
But, in case the file/dataset is small enough to fit and distribute without errors, just go ahead and read directly into data frame and then repartition according to requirement.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/14_read_compressed_file.ipynb
Checkout the PySpark Series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal