PySpark — Optimize Parquet Files
Understand How Parquet files can be compacted efficiently utilizing RLE (Run Length Encoding)

Parquet files are one of the most popular choice for data storage in Data & Analytics world for various reasons. Few of them lists as:
- Write once read Many paradigm
- Columnar storage
- Preserve Schema
- Optimization with Encoding etc.
Today we will understand how efficiently we can utilize the default encodings techniques Parquet implements. We will discuss over RLE (Run Length Encoding), which is a form of lossless data compression in which runs of data (sequences in which the same data value occurs in many consecutive data elements) are stored as a single data value and count, rather than as the original run (Ref. Wikipedia).
Checkout the Apache Parquet documentation — https://parquet.apache.org/docs/file-format/data-pages/encodings/
But, we don’t believe on text until we test it right? 😋
Lets quickly run through an example to see this in action. We will generate random 10 Million numbers between 0 to 10 and write those in Parquet files.
Now if you are new to Spark, PySpark or want to learn more — I teach Big Data, Spark, Data Engineering & Data Warehousing on my YouTube Channel — Ease With Data
The Example 🪛
Generate the required SparkSession
# Create Spark Session
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Optimize Parquet Files") \
.master("local[*]") \
.getOrCreate()
spark
Create a simple Python Function to generate a list of numbers
# Function to generate random data between 0-7
import random
def generate_data(cnt):
_lst = []
for i in range(0, cnt):
num = random.choice(range(0,11))
_lst.append([num])
return _lst
Our time measuring Python decorator to test performance
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())Lets generate 10 Million random numbers and create our DataFrame.
# Genearte dataframe with 10M random numbers
_data = generate_data(10000000)
_schema = "values int"
# Create dataframe
df = spark.createDataFrame(data = _data, schema=_schema)
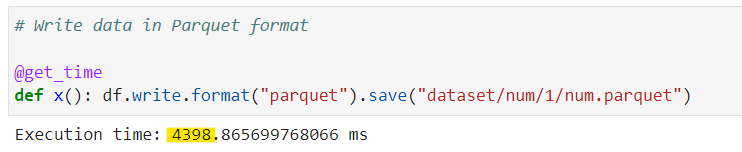
Test 1: Now, lets write it at first location in Parquet format as-is
# Write data in Parquet format
@get_time
def x(): df.write.format("parquet").save("dataset/num/1/num.parquet")
Test 2: OK, Now for second test lets sort the data in Ascending order and write it at second location in Parquet format
# Sort the data
from pyspark.sql.functions import col, asc
df_fixed = df.orderBy(col("values").asc())
# Write in Parquet format
@get_time
def x(): df_fixed.write.format("parquet").save("dataset/num/2/num.parquet")
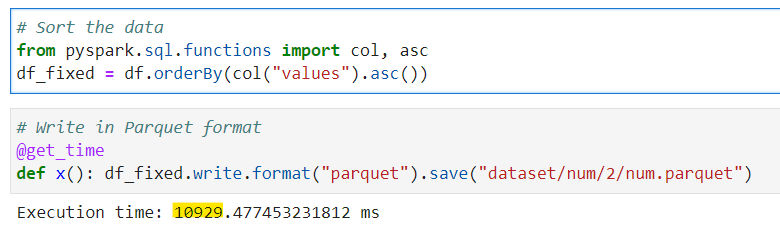
Great, but we see some performance loss here. The Second run took almost 6 extra seconds.
So, where is the benefit ? Lets check the storage.
For first run, it created 8 Parquet files with 618K each.
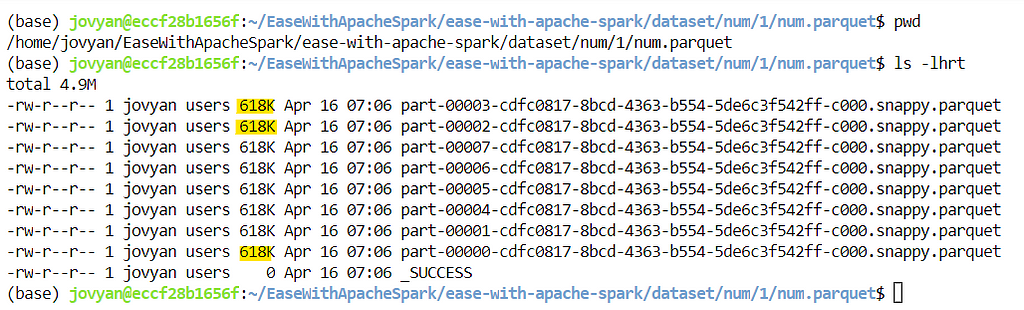
For second run (sorted run), it created only 1 Parquet file of 32K size

Oh my god 🤯it required almost ( 618 X 8 / 32 = 154.5) ~155 times less storage space for sorted data in second run.
So, What changed ? In Second run Parquet was able to utilize RLE and compress and encode the data efficiently.
Background Working ⚒️
Lets understand it with simple example, consider for a column data is

RLE will encode and store it as

where the grey block is number of repetition and white block is actual data, which actually takes more space now (data is random and not sorted).
But what if we just sort our previous data as

Now, the RLE can encode this more efficiently as (grey block is number of repetition and white block is actual data)

which will be more optimized if we have more repetitions in data (as data grows).
Note ⚠️

Conclusion ✌️
So, its evident now how Parquet files can optimize the data storage, but to achieve the same we might need to trade off performance (sort the data before storage). Thus, it solely depends on the implementation of individuals and use cases.
Now if you are new to Spark, PySpark or want to learn more — I teach Big Data, Spark, Data Engineering & Data Warehousing on my YouTube Channel — Ease With Data
Make sure to Like and Subscribe ❤️
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Wish to connect with me: https://topmate.io/subham_khandelwal
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/40_optimize_parquet_files.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal