PySpark — Connect AWS S3
Cloud Distributed Storage spaces such as Google GCS, Amazon S3 and Azure ADLS often serves as data endpoints in many big data workloads.
Today, we are going to try and connect AWS S3 to our PySpark Cluster. And as you know to begin with we would definitely need an AWS Account and S3 bucket created.
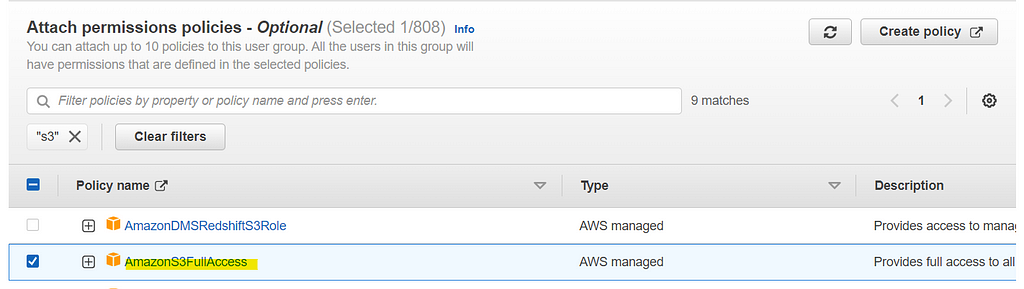
Once ready with the S3 bucket, lets created a new user group S3Group in AWS IAM > User Groups. Attach AmazonS3FullAccess policy to the user group S3Group and complete the wizard.
Once done, lets create a new user S3User and add to S3Group group. As soon the user is attached to S3Group group, go to AWS IAM > User > S3User > Security Credentials > Access Keys and generate a new pair of Access Key.
Now, as the access keys will in format as Key Description/ID and Secret Key. Keep note of both and logout of AWS Console. Our setup in AWS is now complete.
Lets move to PySpark notebook/Spark environment and edit spark-env.sh file to add generated AWS credentials.
Find the spark-env.sh file in directory: Spark Installation > conf. If the file is spark-env.sh.template then rename to spark-env.sh
Append the following lines in the bottom of spark-env.sh file
# AWS ACCESS KEYS
export AWS_ACCESS_KEY_ID=<Your AWS KEY ID>
export AWS_SECRET_ACCESS_KEY=<Your AWS Secret Key>

Now, we can go ahead and create our Spark Session
# Create Spark Session
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf() \
.setAppName("Connect AWS") \
.setMaster("local[*]") \
conf.set("spark.jars.packages","org.apache.hadoop:hadoop-aws:3.3.2")
spark = SparkSession \
.builder \
.config(conf=conf) \
.getOrCreate()
spark
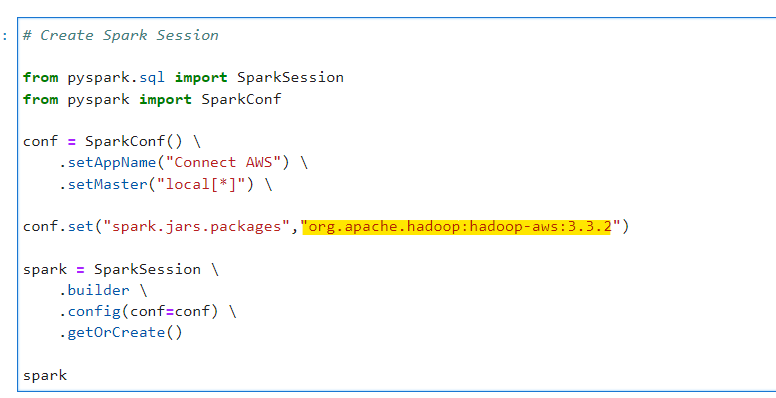
Make sure to add package: org.apache.hadoop:hadoop-aws:3.3.2 to support S3 and AWS access. Spark will automatically download the rest relevant dependent JAR files.
Lets read a file uploaded in S3 bucket
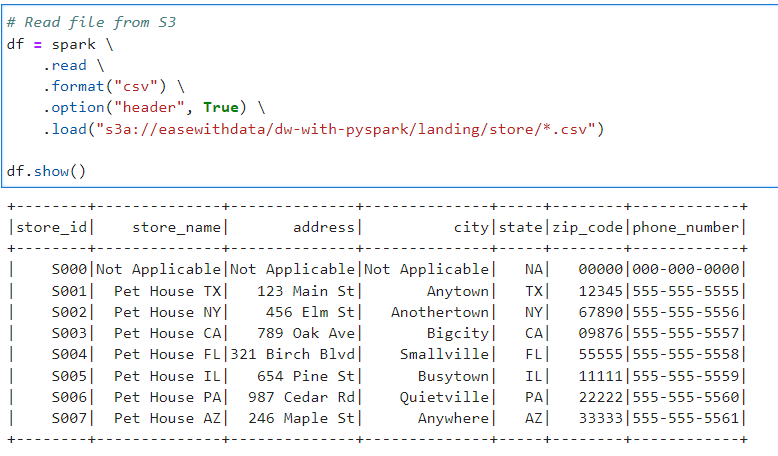
# Read file from S3
df = spark \
.read \
.format("csv") \
.option("header", True) \
.load("s3a://easewithdata/dw-with-pyspark/landing/store/*.csv")
df.show()
Now, lets write the dataframe in parquet format to S3
# Write the data to AWS S3
df.coalesce(1) \
.write \
.format("parquet") \
.save("s3a://easewithdata/dw-with-pyspark/target/demo/store_parquet")
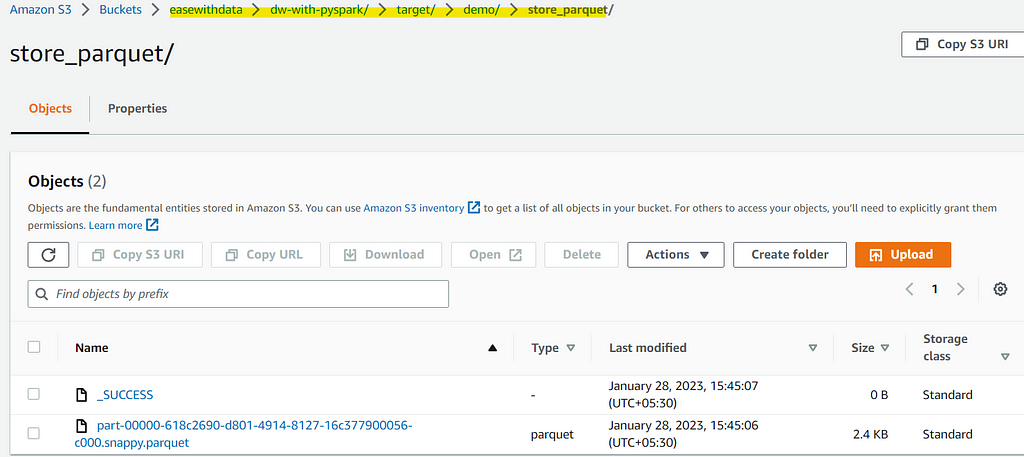
Awesome, we can now easily connect to S3 to read/write data.
Note: For security reasons we are storing the AWS credentials in spark-env.sh file. spark-env.sh will trigger and load the credentials automatically to OS environment and will be available for Spark’s access.
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/34_connect_aws_pyspark.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal