PySpark enables certain popular methods to create data frames on the fly from rdd, iterables such as Python List, RDD etc.
Method 1 — SparkSession range() method
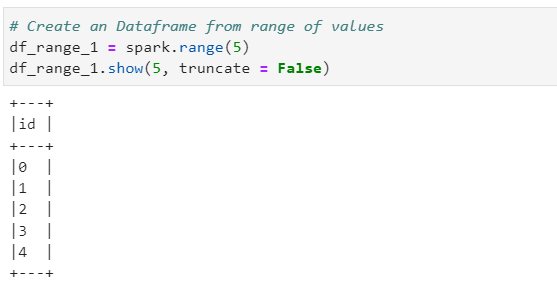
# Create an Dataframe from range of values
df_range_1 = spark.range(5)
df_range_1.show(5, truncate = False)
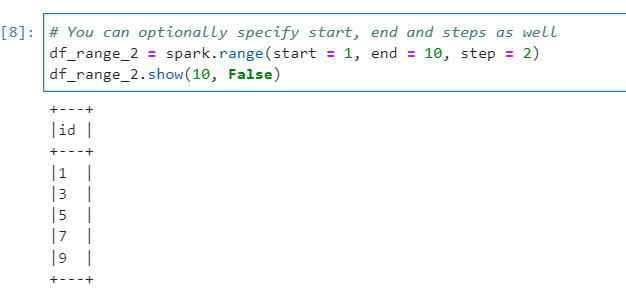
# You can optionally specify start, end and steps as well
df_range_2 = spark.range(start = 1, end = 10, step = 2)
df_range_2.show(10, False)
Method 2 — Spark createDataFrame() method
# Create Python Native List of Data
_data = [
["1", "Ram"],
["2", "Shyam"],
["3", "Asraf"],
["4", None]
]
# Create the list of column names
_cols = ["id", "name"]
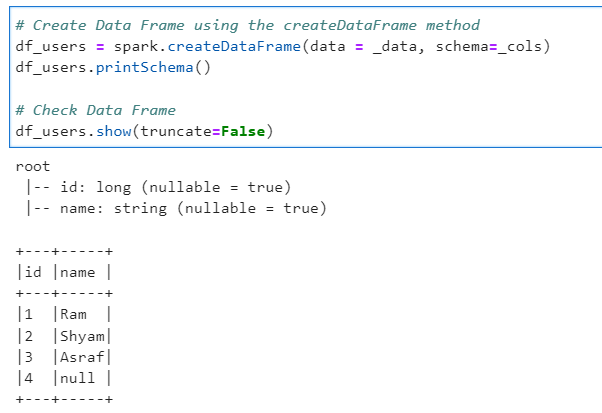
# Create Data Frame using the createDataFrame method
df_users = spark.createDataFrame(data = _data, schema=_cols)
df_users.printSchema()
# Check Data Frame
df_users.show(truncate=False)
Method 3 — Spark toDF() method
# From the same data list we create new RDD
_data_rdd = spark.sparkContext.parallelize(_data)
_data_rdd.collect()
# To check number of partitions of the data
_data_rdd.getNumPartitions()

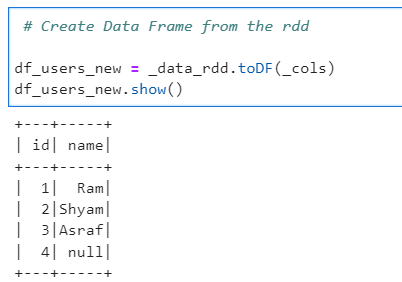
# Create Data Frame from the rdd
df_users_new = _data_rdd.toDF(_cols)
df_users_new.show()
Link to iPython notebook on GitHub — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/1_create_df_on_fly.ipynb
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal