PySpark — Connect Azure ADLS Gen 2
Cloud Distributed Storage spaces such as Google GCS, Amazon S3 and Azure ADLS often serves as data endpoints in many big data workloads.

Today, we are going to try and connect Azure ADLS to our PySpark Cluster. And as you know to begin with we would definitely need an Azure Account and Storage Account created.
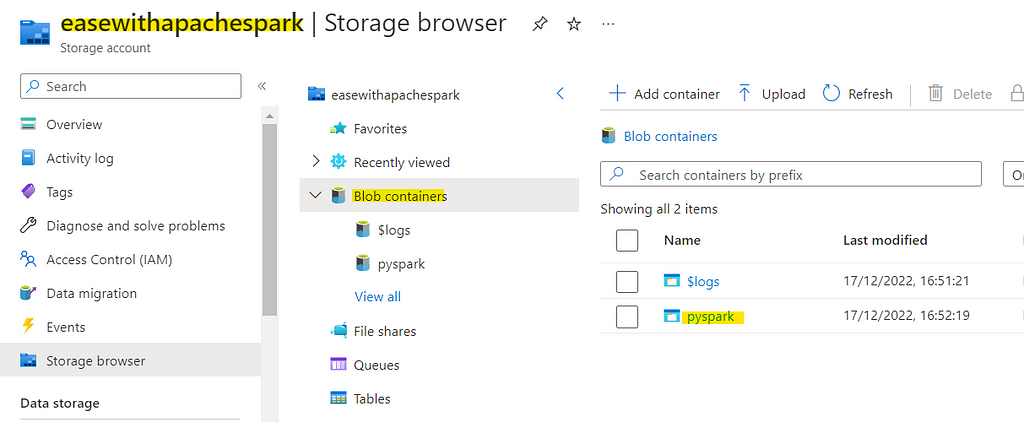
Once you have Storage Account and Blob contained deployed, like in our case.
Checkout Azure Documentation to create a ADLS Gen 2 Container — https://learn.microsoft.com/en-us/azure/storage/blobs/create-data-lake-storage-account
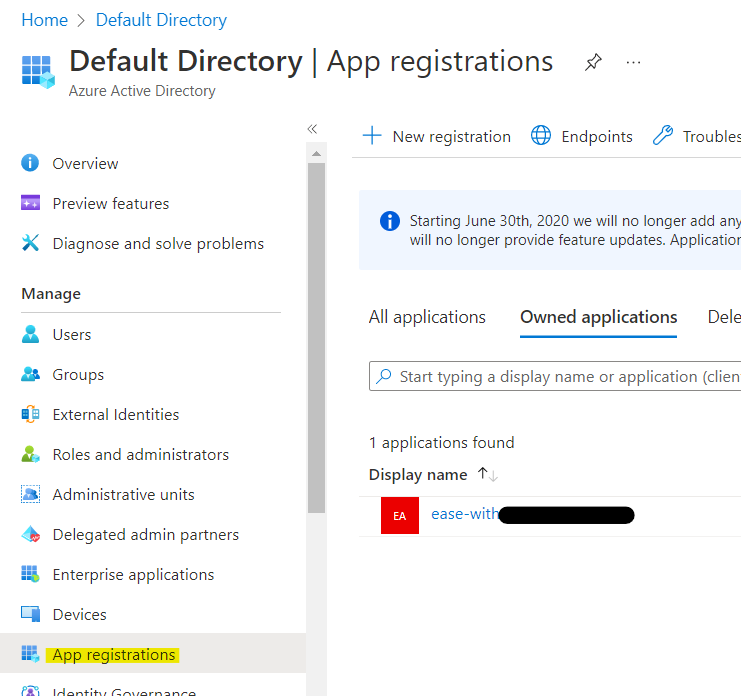
Create the Service Principle (SP) required to access the same. Move to Home > Azure Active Directory > App Registrations > New Registration
Once the Service Principle is created, lets assign the correct roles to access the ADLS. Move to Home > Storage Accounts > {Your Account} >Access Control (IAM) > Add > Add role assignment
Select the role as Storage Blob Data Contributor and move to Next tab. In next tab select the Service Principle we created recently and finally Review + Create.
Now our Service Principle is ready with access to Storage account. One last step is to generate a client-secret for the SP we created. Move to Home > Azure Active Directory > App Registrations > {Your SP}
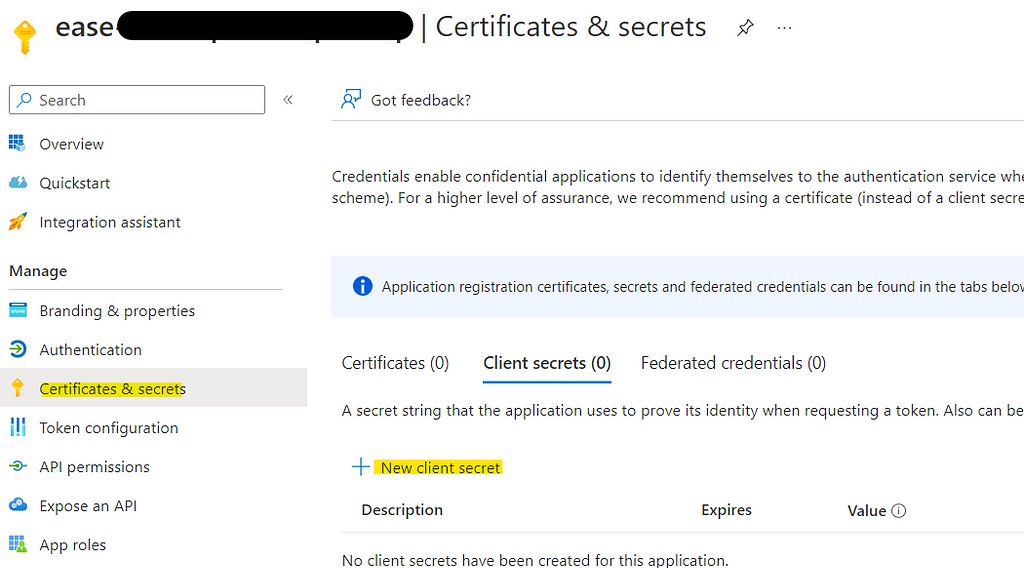
Make sure to note the client-secret value, as this is one time. All configurations are done now in Azure.
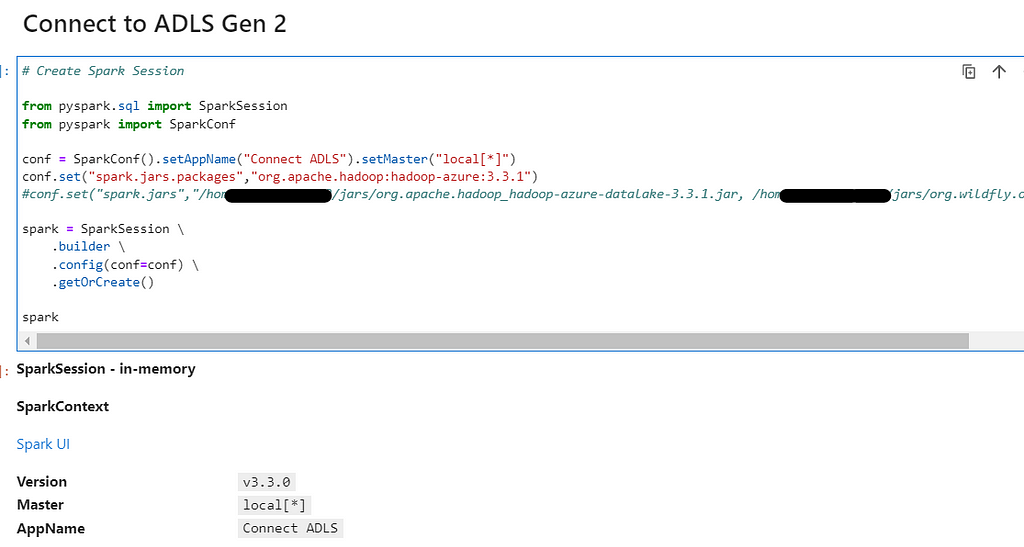
Lets move to our PySpark Cluster to add the final configurations. Create the Spark Session with required dependencies
# Create Spark Session
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf().setAppName("Connect ADLS").setMaster("local[*]")
conf.set("spark.jars.packages","org.apache.hadoop:hadoop-azure:3.3.1")
spark = SparkSession \
.builder \
.config(conf=conf) \
.getOrCreate()
spark
Add all the required configuration information as follows
spark.conf.set("fs.azure.account.auth.type.<storage-account-name>.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account-name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account-name>.dfs.core.windows.net", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account-name>.dfs.core.windows.net","<password>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account-name>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")Which in current case would look like the below (few info is redacted due to privacy):
spark.conf.set("fs.azure.account.auth.type.easewithapachespark.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.easewithapachespark.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.easewithapachespark.dfs.core.windows.net", "f5ad39b3-3223-4eb6-af73-***********")
spark.conf.set("fs.azure.account.oauth2.client.secret.easewithapachespark.dfs.core.windows.net","SC58Q~xZxmXQ4VQgUDuHbJ~YZr0QCz*********")
spark.conf.set("fs.azure.account.oauth2.client.endpoint.easewithapachespark.dfs.core.windows.net", "https://login.microsoftonline.com/d7d52289-b2f8-4c21-99e5-ea5*******/oauth2/token")<storage-account-name> is the name of the Storage Account Created
<application-id> is the Application ID of the SP.
<directory-id> is the Directory ID of the SP.
<password> is the Client Secret of the SP.
Now, lets try to read our dataset
# Read the dataset
df = spark \
.read \
.format("csv") \
.option("header", True) \
.load("abfss://pyspark@easewithapachespark.dfs.core.windows.net/datasets/students.csv")
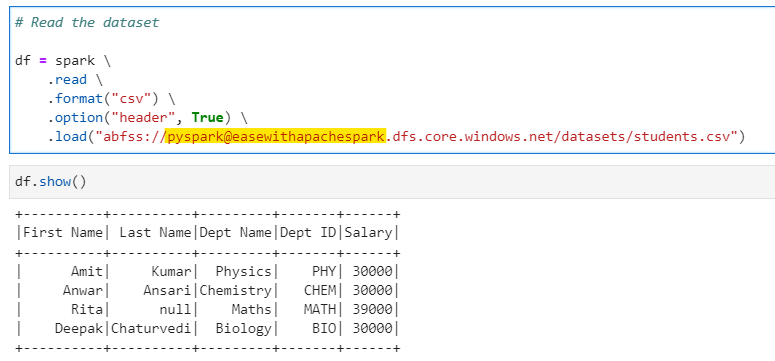
We can easily read the data. The location specified is of the following format
abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/<path-to-dataset>
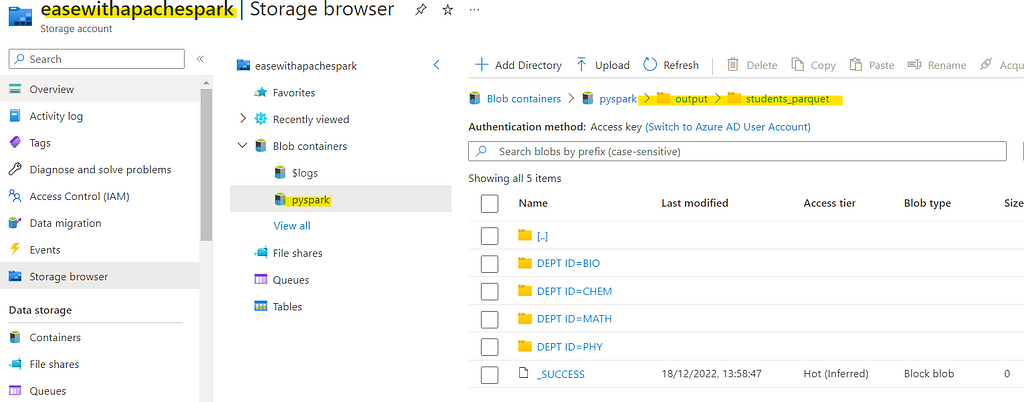
Lets try to write the same dataset into ADLS in form of Parquet
# Lets compute and write back to ADLS
df \
.write \
.format("parquet") \
.partitionBy("DEPT ID") \
.save("abfss://pyspark@easewithapachespark.dfs.core.windows.net/output/students_parquet/")
Note: For security reasons the credentials are never supplied into the code file/notebook. The credentials are stored in core-site.xml or other specification/configuration files with required parameters.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/30_connect_adls_gen2.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal