PySpark — User Defined Functions vs Higher Order Functions
In Spark Structured Data Frame manipulations, its more often for complex calculations we always look forward to UDF i.e. User Defined Functions due to more flexibility towards writing logics.
But, Python UDFs run into performance bottlenecks while dealing with huge volume of data due to serialization & de-serialization. For Spark, a Python UDF is complete black-box over which it has no control, thus it can’t implement any optimization over it on any Physical or Logical layers.
To avoid such bottlenecks, it is always recommended to use Higher Order Functions wherever possible for complex calculations.
Spark employs many popular higher order functions such as filter, transform, exists, aggregate etc. which can be chained to achieve result in an optimized way.
Lets check this is action. We will create an example data frame with city names and try to calculate the length of the city names all together.
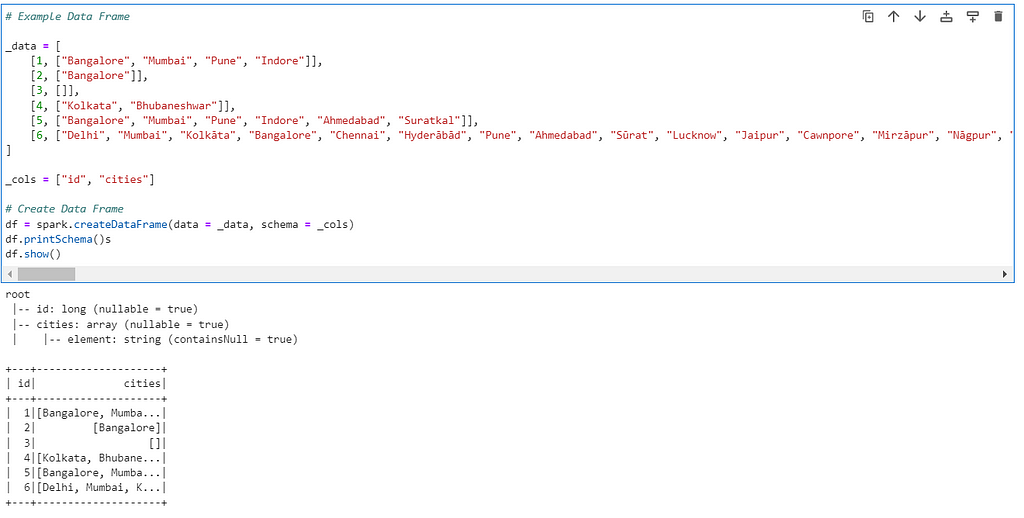
# Example Data Frame
_data = [
[1, ["Bangalore", "Mumbai", "Pune", "Indore"]],
[2, ["Bangalore"]],
[3, []],
[4, ["Kolkata", "Bhubaneshwar"]],
[5, ["Bangalore", "Mumbai", "Pune", "Indore", "Ahmedabad", "Suratkal"]],
[6, ["Delhi", "Mumbai", "Kolkāta", "Bangalore", "Chennai", "Hyderābād", "Pune", "Ahmedabad", "Sūrat", "Lucknow", "Jaipur", "Cawnpore", "Mirzāpur", "Nāgpur", "Ghāziābād", "Indore", "Vadodara", "Vishākhapatnam", "Bhopāl", "Chinchvad", "Patna", "Ludhiāna", "Āgra", "Kalyān", "Madurai", "Jamshedpur", "Nāsik", "Farīdābād", "Aurangābād", "Rājkot", "Meerut", "Jabalpur", "Thāne", "Dhanbād", "Allahābād", "Vārānasi", "Srīnagar", "Amritsar", "Alīgarh", "Bhiwandi", "Gwalior", "Bhilai", "Hāora", "Rānchi", "Bezwāda", "Chandīgarh", "Mysore", "Raipur", "Kota", "Bareilly", "Jodhpur", "Coimbatore", "Dispur", "Guwāhāti", "Solāpur", "Trichinopoly", "Hubli", "Jalandhar", "Bhubaneshwar", "Bhayandar", "Morādābād", "Kolhāpur", "Thiruvananthapuram", "Sahāranpur", "Warangal", "Salem", "Mālegaon", "Kochi", "Gorakhpur", "Shimoga", "Tiruppūr", "Guntūr", "Raurkela", "Mangalore", "Nānded", "Cuttack", "Chānda", "Dehra Dūn", "Durgāpur", "Āsansol", "Bhāvnagar", "Amrāvati", "Nellore", "Ajmer", "Tinnevelly", "Bīkaner", "Agartala", "Ujjain", "Jhānsi", "Ulhāsnagar", "Davangere", "Jammu", "Belgaum", "Gulbarga", "Jāmnagar", "Dhūlia", "Gaya", "Jalgaon", "Kurnool", "Udaipur", "Bellary", "Sāngli", "Tuticorin", "Calicut", "Akola", "Bhāgalpur", "Sīkar", "Tumkūr", "Quilon", "Muzaffarnagar", "Bhīlwāra", "Nizāmābād", "Bhātpāra", "Kākināda", "Parbhani", "Pānihāti", "Lātūr", "Rohtak", "Rājapālaiyam", "Ahmadnagar", "Cuddapah", "Rājahmundry", "Alwar", "Muzaffarpur", "Bilāspur", "Mathura", "Kāmārhāti", "Patiāla", "Saugor", "Bijāpur", "Brahmapur", "Shāhjānpur", "Trichūr", "Barddhamān", "Kulti", "Sambalpur", "Purnea", "Hisar", "Fīrozābād", "Bīdar", "Rāmpur", "Shiliguri", "Bāli", "Pānīpat", "Karīmnagar", "Bhuj", "Ichalkaranji", "Tirupati", "Hospet", "Āīzawl", "Sannai", "Bārāsat", "Ratlām", "Handwāra", "Drug", "Imphāl", "Anantapur", "Etāwah", "Rāichūr", "Ongole", "Bharatpur", "Begusarai", "Sonīpat", "Rāmgundam", "Hāpur", "Uluberiya", "Porbandar", "Pāli", "Vizianagaram", "Puducherry", "Karnāl", "Nāgercoil", "Tanjore", "Sambhal", "Naihāti", "Secunderābād", "Kharagpur", "Dindigul", "Shimla", "Ingrāj Bāzār", "Ellore", "Puri", "Haldia", "Nandyāl", "Bulandshahr", "Chakradharpur", "Bhiwāni", "Gurgaon", "Burhānpur", "Khammam", "Madhyamgram", "Ghāndīnagar", "Baharampur", "Mahbūbnagar", "Mahesāna", "Ādoni", "Rāiganj", "Bhusāval", "Bahraigh", "Shrīrāmpur", "Tonk", "Sirsa", "Jaunpur", "Madanapalle", "Hugli", "Vellore", "Alleppey", "Cuddalore", "Deo", "Chīrāla", "Machilīpatnam", "Medinīpur", "Bāramūla", "Chandannagar", "Fatehpur", "Udipi", "Tenāli", "Sitalpur", "Conjeeveram", "Proddatūr", "Navsāri", "Godhra", "Budaun", "Chittoor", "Harīpur", "Saharsa", "Vidisha", "Pathānkot", "Nalgonda", "Dibrugarh", "Bālurghāt", "Krishnanagar", "Fyzābād", "Silchar", "Shāntipur", "Hindupur"]]
]
_cols = ["id", "cities"]
# Create Data Frame
df = spark.createDataFrame(data = _data, schema = _cols)
df.printSchema()
df.show()
Lets create a Python decorator to test the performance of the queries
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())
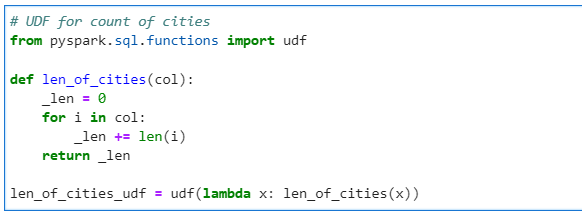
Now, the UDF to calculate the length of cities all together
# UDF for lenght of cities
from pyspark.sql.functions import udf
def len_of_cities(col):
_len = 0
for i in col:
_len += len(i)
return _len
len_of_cities_udf = udf(lambda x: len_of_cities(x))
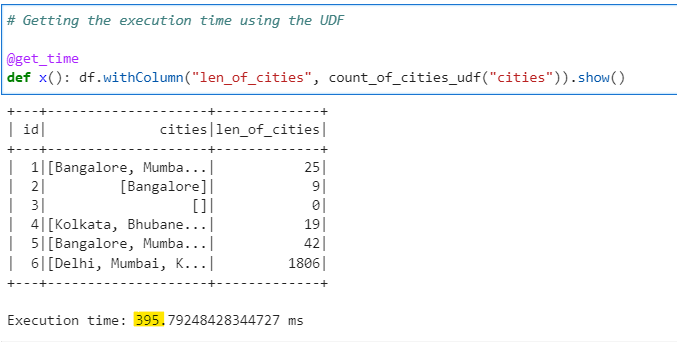
Lets measure the performance for our calculation using UDF
# Getting the execution time using the UDF
@get_time
def x(): df.withColumn("len_of_cities", count_of_cities_udf("cities")).show()
Now, we do the same calculation but with Higher Order Function aggregate()
# Using Higher Order Function
from pyspark.sql.functions import aggregate, lit, length, size
@get_time
def x(): df.withColumn("len_of_cities", aggregate("cities", lit(0), lambda x, y: x + length(y))).show()
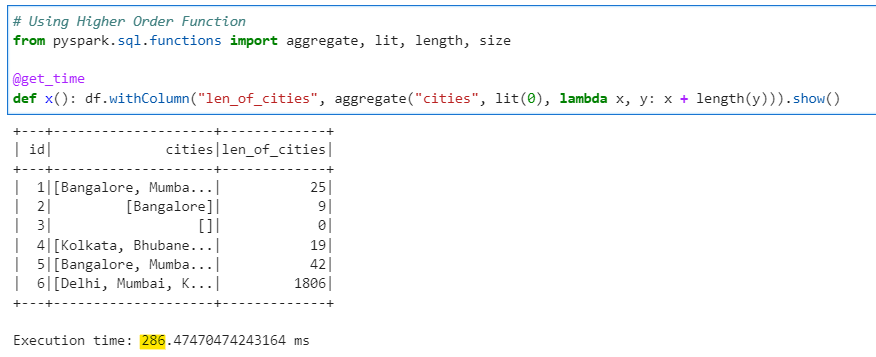
Conclusion: As it is very evident the Higher Order Functions have performance gain over Python UDF. This difference will increase with the size and complexity of the data. It is always recommended to use Higher Order Functions wherever possible over Python UDF.
Checkout the iPython Notebook on Githib — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/8_udf_vs_higher_order_functions.ipynb
Checkout the PySpark Series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal