PySpark — Optimize Huge File Read
How to read huge/big files effectively in Spark
We all have been in scenario, where we have to deal with huge file sizes with limited compute or resources. More often we need to find ways to optimize such file read/processing to make our data pipelines efficient.
Today we are going to discuss about one such configuration of Spark, which will help us to deal with the problem in efficient way.

The Configuration
Files Partition Size is a well known configuration which is configured through — spark.sql.files.maxPartitionBytes. The default value is set to 128 MB since Spark Version ≥ 2.0.0. The definition for the setting is as follows.
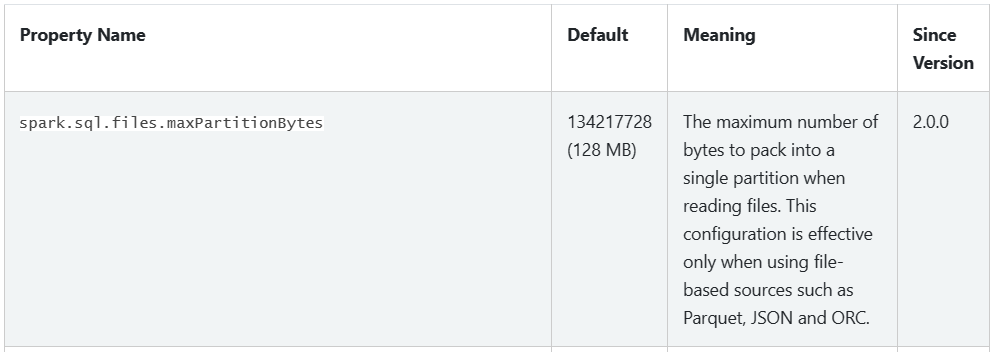
Spark Documentation — Performance Tuning — Spark 3.3.2 Documentation (apache.org)
The Importance
To understand the importance of this configuration and demonstration, we will be reading single 2.46 GB CSV Sales file in our local environment with 8 cores.
Lets generate our SparkSession and validate the default setting in our environment.
Now if you are new to Spark, PySpark or want to learn more — I teach Big Data, Spark, Data Engineering & Data Warehousing on my YouTube Channel — Ease With Datahttps://medium.com/media/07e6160ad852f2373b736a9a026237b3/href
# Check the default partition size
partition_size = spark.conf.get("spark.sql.files.maxPartitionBytes").replace("b","")
print(f"Partition Size: {partition_size} in bytes and {int(partition_size) / 1024 / 1024} in MB")

Check the default parallelism
# Check the default parallelism available
print(f"Parallelism : {spark.sparkContext.defaultParallelism}")

Validate the file size
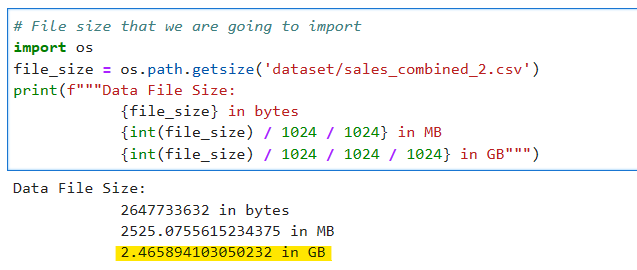
# File size that we are going to import
import os
file_size = os.path.getsize('dataset/sales_combined_2.csv')
print(f"""Data File Size:
{file_size} in bytes
{int(file_size) / 1024 / 1024} in MB
{int(file_size) / 1024 / 1024 / 1024} in GB""")
To benchmark our performance we will be writing the dataset with noop format and will be using following python decorator for timings.
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):n t
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
print("-"*80)
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())
print("-"*80)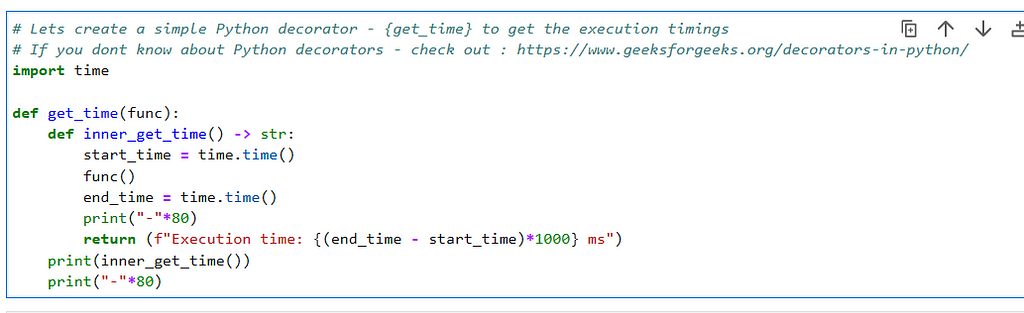
Execution 1: Read the dataset and write with noop format using the default settings.
# Lets read the file and write in noop format for Performance Benchmarking
@get_time
def x():
df = spark.read.format("csv").option("header", True).load("dataset/sales_combined_2.csv")
print(f"Number of Partition -> {df.rdd.getNumPartitions()}")
df.write.format("noop").mode("overwrite").save()
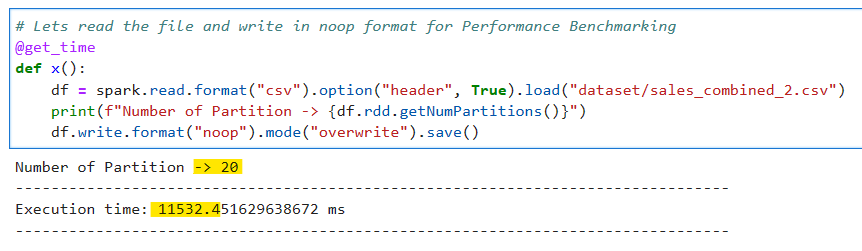
The data was divided into 20 partitions (which is not factor of cores) and took around 11.5 seconds to complete the execution.
Why 20 partitions not more? There is a calculation involved to determine the number of partitions, we will discuss about the same in further articles.
Execution 2: Increase the Partition Size to 3 times i.e. 384 MB
Lets increase the partition size to 3 times in order to see the effect.
# Change the default partition size to 3 times to decrease the number of partitions
spark.conf.set("spark.sql.files.maxPartitionBytes", str(128 * 3 * 1024 * 1024)+"b")
# Verify the partition size
partition_size = spark.conf.get("spark.sql.files.maxPartitionBytes").replace("b","")
print(f"Partition Size: {partition_size} in bytes and {int(partition_size) / 1024 / 1024} in MB")

Execute the job again
# Lets read the file again with new partition size and write in noop format for Performance Benchmarking
@get_time
def x():
df = spark.read.format("csv").option("header", True).load("dataset/sales_combined_2.csv")
print(f"Number of Partition -> {df.rdd.getNumPartitions()}")
df.write.format("noop").mode("overwrite").save()
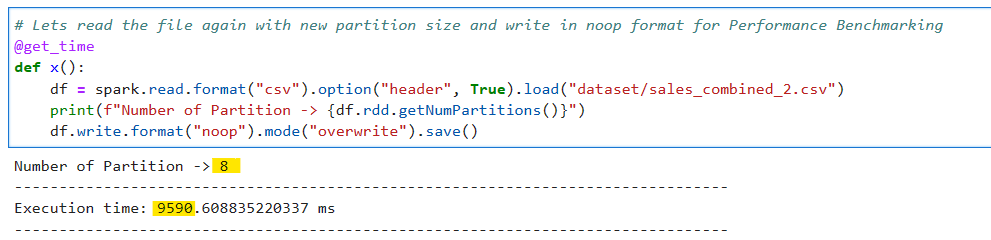
OK, it seems the number of partitions now decreased to 8 (factor of cores) and the time reduced to 9.5 seconds.
Lets do one more test.
Execution 3: Set the partition size to 160 MB
Set the partition size to 160MB somewhere in between the default and previous setting.
# Change the default partition size to 160 MB to decrease the number of partitions
spark.conf.set("spark.sql.files.maxPartitionBytes", str(160 * 1024 * 1024)+"b")
# Verify the partition size
partition_size = spark.conf.get("spark.sql.files.maxPartitionBytes").replace("b","")
print(f"Partition Size: {partition_size} in bytes and {int(partition_size) / 1024 / 1024} in MB")

Effect on Job execution
# Lets read the file again with new partition size and write in noop format for Performance Benchmarking
@get_time
def x():
df = spark.read.format("csv").option("header", True).load("dataset/sales_combined_2.csv")
print(f"Number of Partition -> {df.rdd.getNumPartitions()}")
df.write.format("noop").mode("overwrite").save()
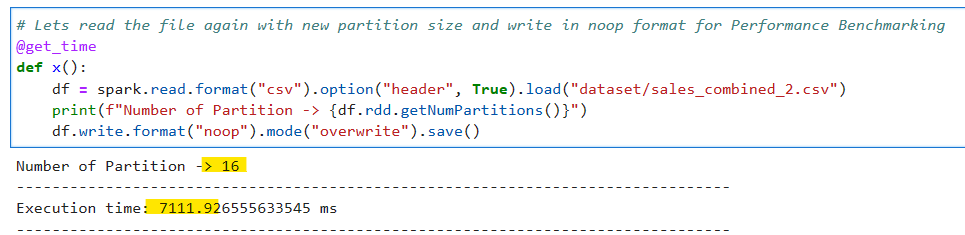
Awesome, the job timing further reduced to 7 seconds and the partition is increased to 16 which is factor of cores.
What is factor of cores? Checkout this article — https://subhamkharwal.medium.com/pyspark-the-factor-of-cores-e884b2d5af6c
Conclusion: Its very evident that tuning maxPartitionBytes configuration for file ingestions to a perfect value can make the jobs more faster and efficient.
But currently we are tuning this manually, Is there any automated which can pin-point to a correct size? Yes, we can design an utility which can tell us the approximate maxPartitionBytes size very efficiently for various file sizes.
We will discuss about the calculations involved and the utility in later articles. Till then Keep Learning, Keep Growing and Keep Sharing❤️
Make sure to Like and Subscribe.
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Wish to connect with me: https://topmate.io/subham_khandelwal
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/38_optimize_huge_file_read.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal