PySpark — Optimize Joins in Spark
Shuffle Hash Join, Sort Merge Join, Broadcast joins and Bucketing for better Join Performance.
Mastering the art of Optimizing Joins in Spark is still one of the most crucial and transformative skills for a data engineer. Today we are going to sharpen this skill to increase our data processing capabilities.
Now, this article is going to be a bit lengthy so please hang on till the end, its definitely worth your time !

Now if you are new to Spark, PySpark or want to learn more — I teach Big Data, Spark, Data Engineering & Data Warehousing on my YouTube Channel — Ease With Data. Improve your PySpark Skill with this Playlist.
Before we begin
For any JOIN to happen, Spark need to have the same keys for the joining Column from both table on the same executor (now if you unfamiliar of executor — Checkout this YouTube video). And if the keys are not present on same executor, Spark uses Shuffle(Exchange) steps in order to achieve it.
Now, we all know that Shuffle leads to Disk IO operations and Network data movement which is bad for Spark. Thus its very important for us to optimize or remove this Step as much as possible.
For today’s experiment we are going to use two sets of data with volume mentioned below:
- Employee (10M records) and Department (10 records) — joining column department_id.
- Sales (7.2M records) and Cities(2.2M records) — joining column city_id.
We will explore three famous joining strategies that Spark offers — ShuffleHash Join, SortMerge Join and Broadcast Joins. And before we experiment with these joining strategies, lets set up some ground.
Shuffle Hash Join
Shuffle Hash join encompasses the following sequential steps:
- Both datasets (tables) will be shuffled among the executors based on the key column.
- The Smaller shuffled dataset (table) will be hashed in each executor in order to match with the hashed key of the bigger dataset.
- Once the hashed key matches, the joining works.
Points to Note:
- It majorly supports equi joins (=), except for Full outer join.
- There is NO Sort step involved, thus keys are not sorted.
- It is suitable for Joins where we have at least one Smaller dataset which can fit in memory.
- To make sure Spark uses Shuffle Hash Join, we need to set: spark.sql.join.preferSortMergeJoin=false
Sort Merge Join
Sort Merge is another famous joining Strategies that follows the below steps:
- Both datasets (tables) will be shuffled among the executors based on the key column.
- The joining keys from both datasets will be sorted in same order.
- Once the joining key are sorted the Merging happens (thus its Sort Merge).
Points to Note:
- It supports all join types including full outer joins.
- Since there is a Sort step, it can be an expensive join if not optimized properly.
- Preferred when we have two Big dataset (tables) to join.
- We can set — spark.sql.join.preferSortMergeJoin=true to use Sort Merge Join.
Broadcast Hash Join (Broadcast Join)
Its a famous joining technique that involves broadcasting (complete copy) the smaller dataset to all executors to avoid Shuffle step. Steps are as follows:
- Driver gets the Smaller dataset (table) from executor and broadcast it all the executors.
- Once the broadcasted dataset is present in all executors, the larger dataset partitions present are hashed and joined based on Key column.
Points to Note:
- NO Sorting and NO Shuffle step is involved.
- The smaller dataset which will be broadcasted, should not exceed 10MB (default size), but can be increased to 8G with spark.sql.autoBroadcastJoinThreshold configuration.
- The Dataset to be broadcasted should fit in both executor and driver memory, else it will run out of memory errors.
- Majorly supports equi joins, except full outer.
- It preferred, when we have one Big and one Small datasets to join.
With the groundwork established, let’s commence.
1️⃣ Big and Small table (Employee and Department) with Sort Merge Join
Lets begin with Joining our Employee data with department on department_id key column.
Read the datasets:
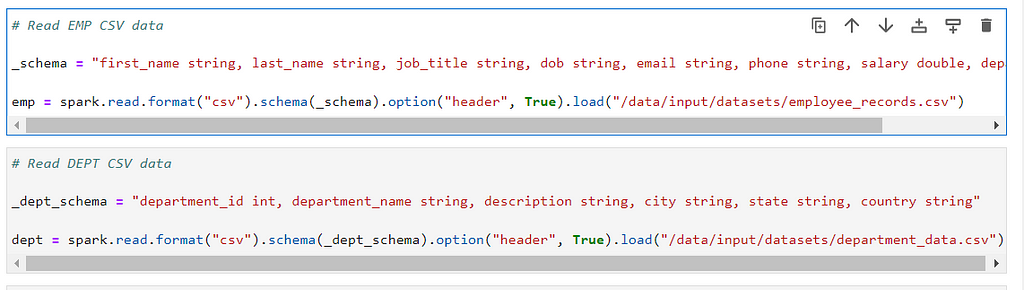
# Read EMP CSV data
_schema = "first_name string, last_name string, job_title string, dob string, email string, phone string, salary double, department_id int"
emp = spark.read.format("csv").schema(_schema).option("header", True).load("/data/input/datasets/employee_records.csv")
# Read DEPT CSV data
_dept_schema = "department_id int, department_name string, description string, city string, state string, country string"
dept = spark.read.format("csv").schema(_dept_schema).option("header", True).load("/data/input/datasets/department_data.csv")
Lets join them and write in noop format for performance benchmarking
# Join both datasets
df_joined = emp.join(dept, on=emp.department_id==dept.department_id, how="left_outer")
# Write data in noop format for performance beachmarking
df_joined.write.format("noop").mode("overwrite").save()

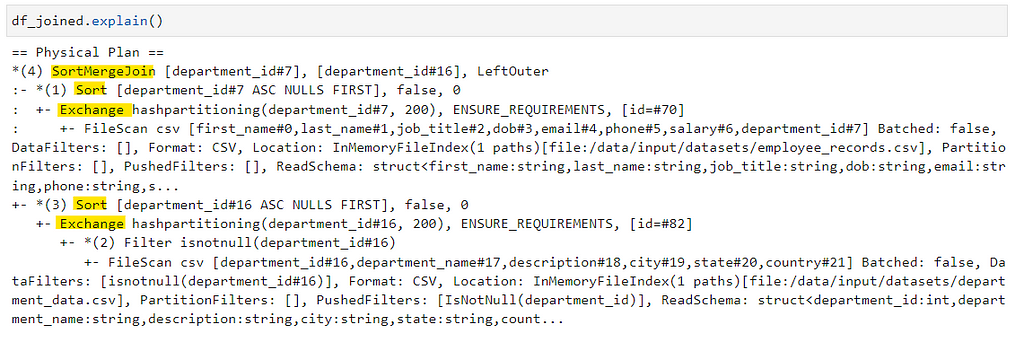
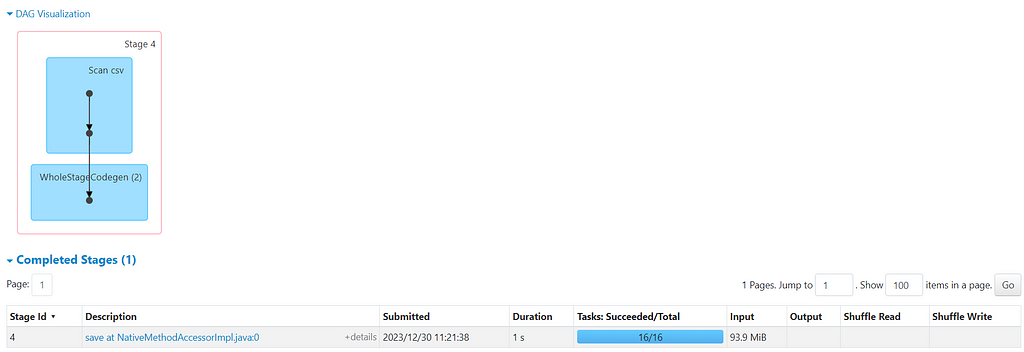
Lets view the explain plan and the DAGs generated.
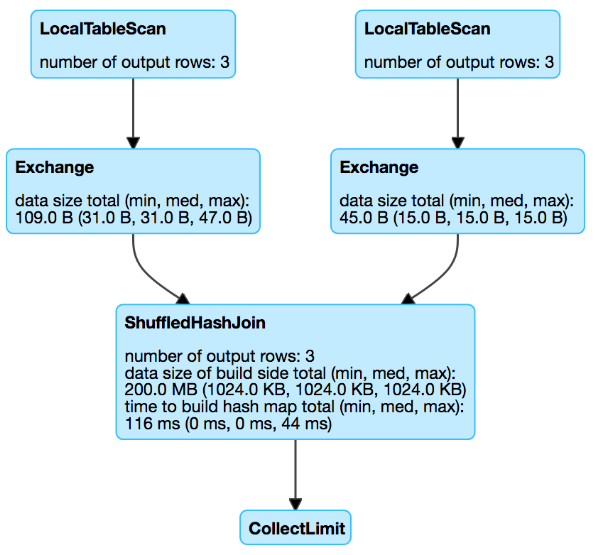
Full DAG
DAG from the JOB
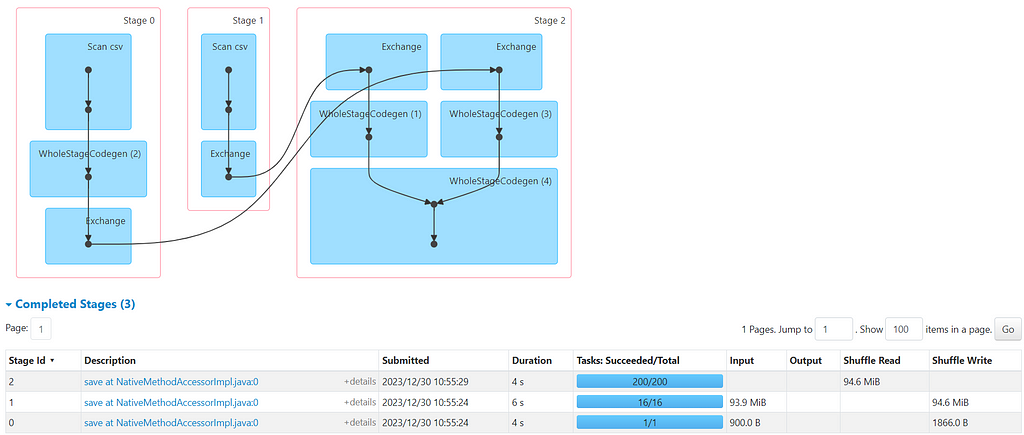
Now, if you have noticed from the DAG and Explain Plan, job took around 11 seconds by Shuffling and Sorting the keys for both datasets before joining. (Unsure of reading DAG and Explain Plan — Checkout this YouTube video)
Lets perform the same join now, but with BroadCastHash Strategy.
2️⃣ Big and Small table (Employee and Department) with BroadCast Hash Join
All steps for reading the datasets from the above remains same, we will now broadcast the Department dataframe (smaller dataset).
# Join Datasets
from pyspark.sql.functions import broadcast
df_joined = emp.join(broadcast(dept), on=emp.department_id==dept.department_id, how="left_outer")
# Write data in noop format for performance beachmarking
df_joined.write.format("noop").mode("overwrite").save()

Explain Plan
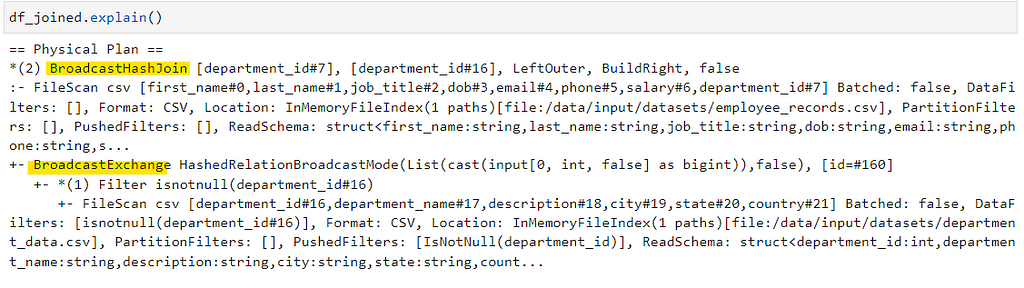
Full DAG
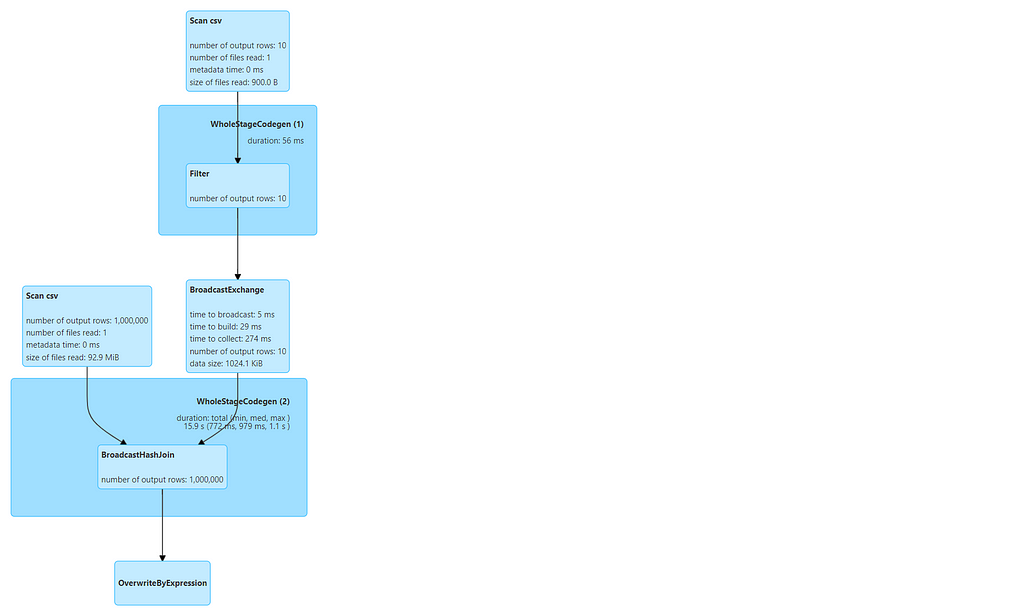
DAG from JOB (Two jobs will be created one for broadcasting the dataset and the other one for joining)
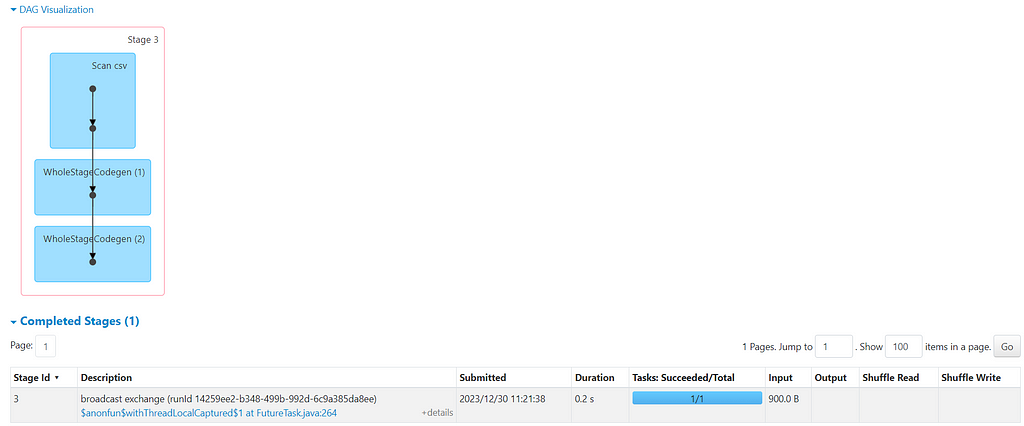
Did you notice something ? — there is no Sort or Shuffle step involved this time. And the job completed insanely FAST, check the timing for both jobs below.

Now, that we are good with Big and Small table joins, lets checkout Big vs Big table join.
3️⃣Big and Big table (Sales and Cities) with SortMerge Join
Since both datasets are big we can’t use Broadcast join here, as we will run out of memory if we try to fit a big dataset in memory. So, let first join them normally.
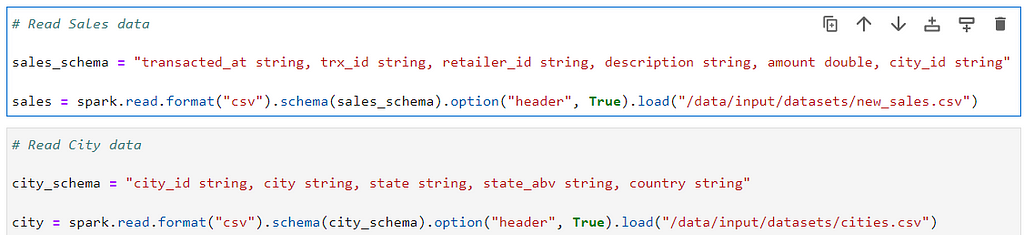
Lets read our Sales and Cities datasets with joining key as city_id
# Read Sales data
sales_schema = "transacted_at string, trx_id string, retailer_id string, description string, amount double, city_id string"
sales = spark.read.format("csv").schema(sales_schema).option("header", True).load("/data/input/datasets/new_sales.csv")
# Read City data
city_schema = "city_id string, city string, state string, state_abv string, country string"
city = spark.read.format("csv").schema(city_schema).option("header", True).load("/data/input/datasets/cities.csv")
Lets join them and write in noop format for performance benchmarking
# Join Data
df_sales_joined = sales.join(city, on=sales.city_id==city.city_id, how="left_outer")
# Write Joined data
df_sales_joined.write.format("noop").mode("overwrite").save()

Explain Plan
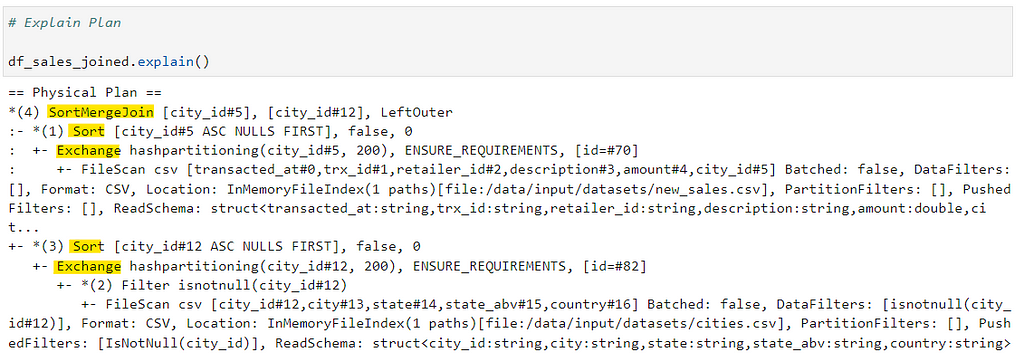
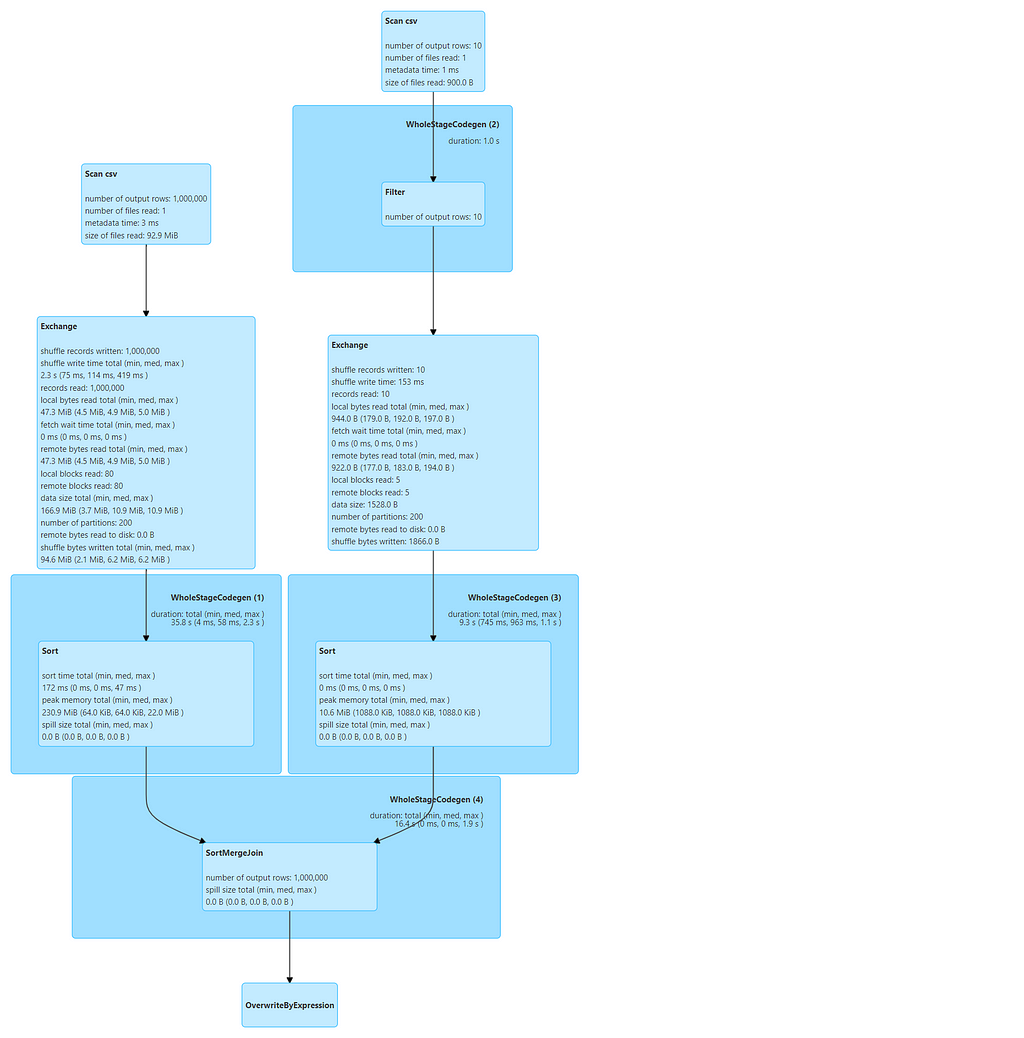
Full DAG
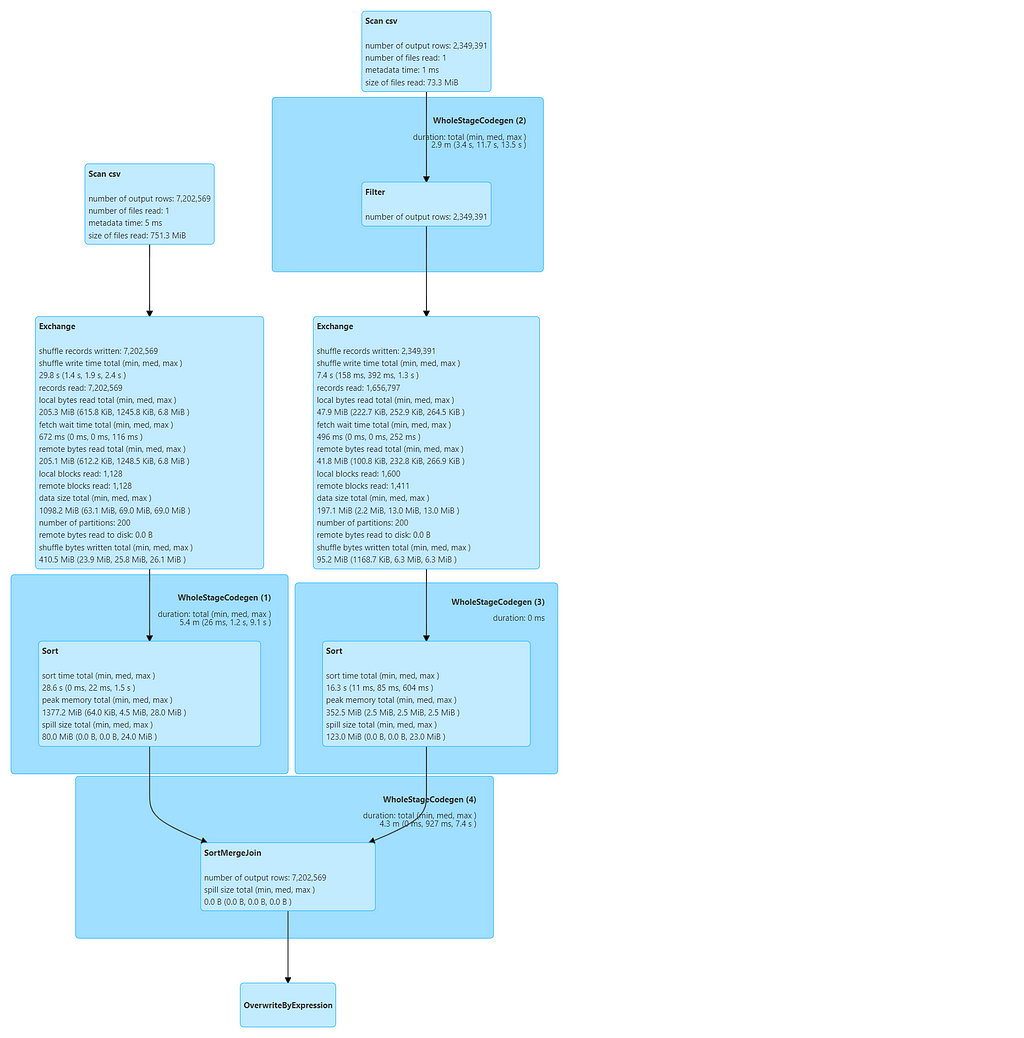
DAG from the JOB
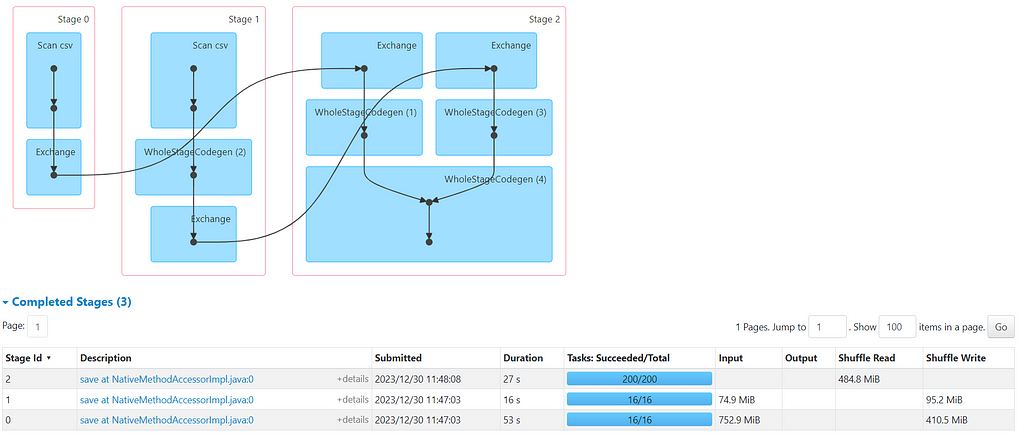
The job took around 1.5min involving Shuffling and Sorting of data. It can be more disastrous if the dataset volume will start increasing.
So, it there a way to improve its performance? The answer is Yes, We can utilize bucketing to improve big table joins.
4️⃣Big and Big table (Sales and Cities) with Bucketing
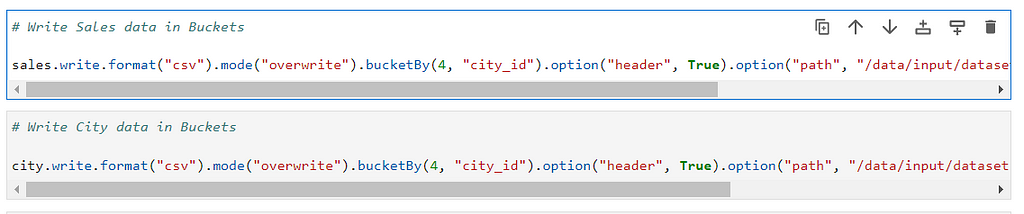
Lets divide the same Sales and City data in 4 buckets with city_id as bucketing column same as joining column (Unsure of Bucketing in Spark — Checkout).
# Write Sales data in Buckets
sales.write.format("csv").mode("overwrite").bucketBy(4, "city_id").option("header", True).option("path", "/data/input/datasets/sales_bucket.csv").saveAsTable("sales_bucket")
# Write City data in Buckets
city.write.format("csv").mode("overwrite").bucketBy(4, "city_id").option("header", True).option("path", "/data/input/datasets/city_bucket.csv").saveAsTable("city_bucket")
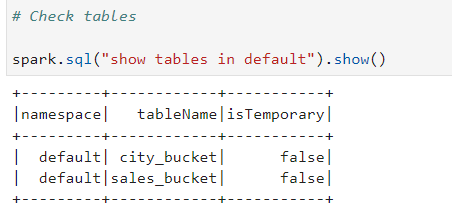
Now lets read the bucketed tables
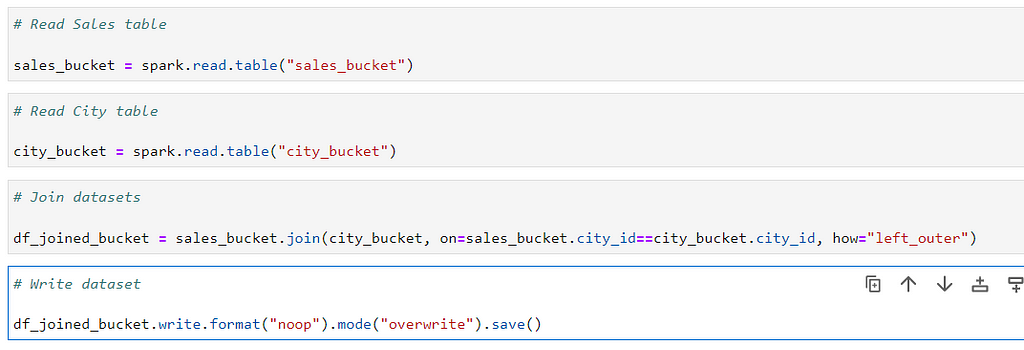
# Read Sales table
sales_bucket = spark.read.table("sales_bucket")
# Read City table
city_bucket = spark.read.table("city_bucket")
Join the tables
# Join datasets
df_joined_bucket = sales_bucket.join(city_bucket, on=sales_bucket.city_id==city_bucket.city_id, how="left_outer")
# Write dataset
df_joined_bucket.write.format("noop").mode("overwrite").save()
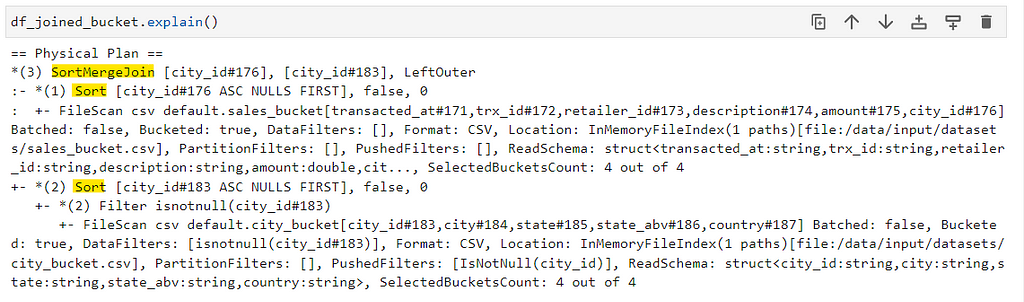
Full DAG
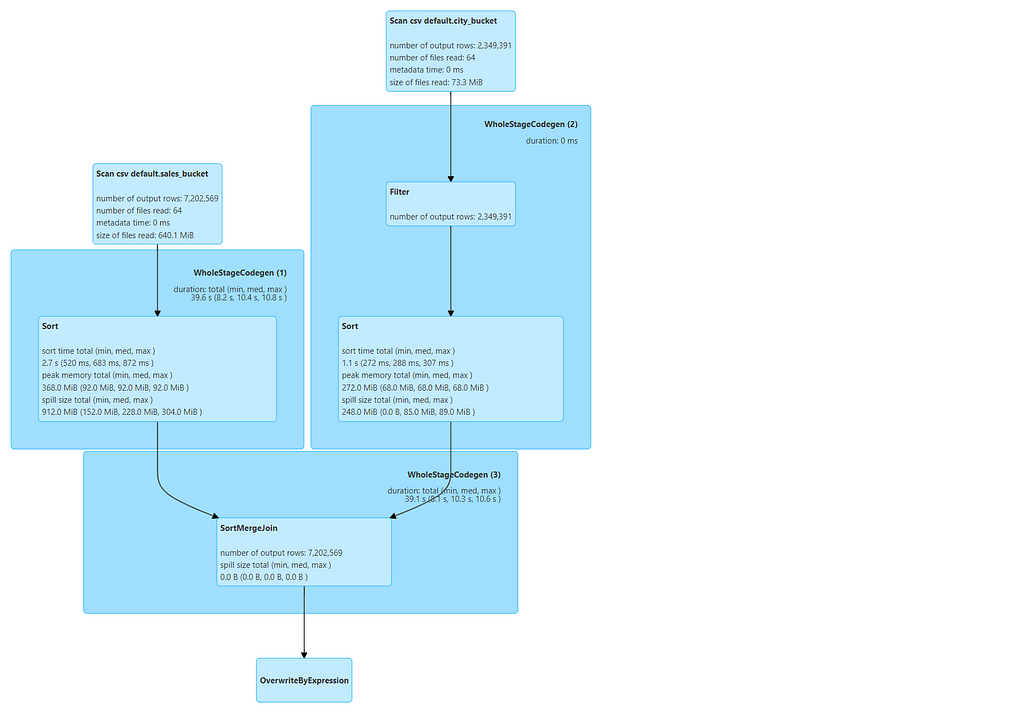
DAG from the JOB
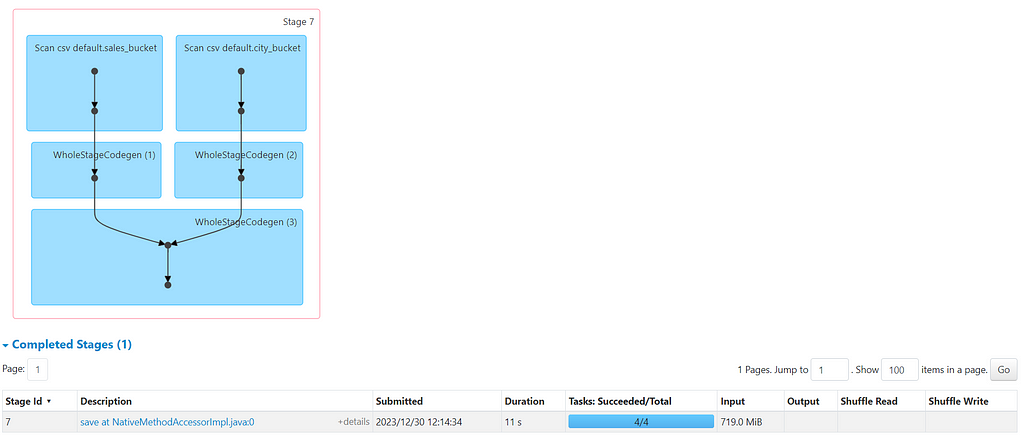
Now, if you checked the explain plan and DAG, its quite evident that we avoided shuffle/exchange in bucket join and the job completed in 11 sec. We have total of 4 tasks as both datasets are divided in 4 buckets. The job can further be optimized by changing the bucket size.

So, there is significant amount of performance benefit if our Big datasets are bucketed. But, keep a note of following points:
- Joining Column different than Bucket Column, Same Bucket Size — Shuffle on Both table
- Joining & Bucketing Column Same, One table in Bucket — Shuffle on non Bucket table
- Joining & Bucketing Column Same, Different Bucket Size — Shuffle on Smaller Bucket table
- Joining & Bucketing Column Same, Same Bucket Size — No Shuffle (Faster Join)
If you still in doubt, check out this YouTube video if you want to understand the same with more clarity.
https://medium.com/media/3264d23338cdd635ae4daf4defd35f93/hrefNote 📝
So its very important to choose correct Bucket column and Bucket Size. Decide effectively on number of Buckets, as too many buckets with not enough data can lead to Small file issue and we have discussed small file issue in this article.
Now if you are new to Spark, PySpark or want to learn more — I teach Big Data, Spark, Data Engineering & Data Warehousing on my YouTube Channel — Ease With Data. Improve your PySpark Skill with this Playlist.
Make sure to Like, Subscribe and Share with your network❤️
PySpark Zero to Hero Series on YouTube: https://youtube.com/playlist?list=PL2IsFZBGM_IHCl9zhRVC1EXTomkEp_1zm&si=Q664l-TFXf4wj1We
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Wish to connect with me: https://topmate.io/subham_khandelwal
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/pyspark-zero-to-hero/blob/master/18_optimizing_joins.ipynb
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
PySpark — Optimize Joins in Spark was originally published in Dev Genius on Medium, where people are continuing the conversation by highlighting and responding to this story.
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal