PySpark — Structured Streaming Read from Files
Often Streaming use case needs to read data from files/folders and process for downstream requirements. And to elaborate this, lets consider the following use case.
A popular thermostat company takes reading from their customer devices to understand device usage. The device data JSON files are generated and dumped in an input folder. The notification team requires the data to be flattened in real-time and written in output in JSON format for sending out notifications and reporting accordingly.

A sample JSON input file contains the following data points

Now, to design the real time streaming pipeline to ingest the file and flatten, lets create the SparkSession
# Create the Spark Session
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Streaming Process Files") \
.config("spark.streaming.stopGracefullyOnShutdown", True) \
.master("local[*]") \
.getOrCreate()
spark
Create the DataFrameStreamReader dataframe
# To allow automatic schemaInference while reading
spark.conf.set("spark.sql.streaming.schemaInference", True)
# Create the streaming_df to read from input directory
streaming_df = spark.readStream\
.format("json") \
.option("cleanSource", "archive") \
.option("sourceArchiveDir", "data/archive/device_data/") \
.option("maxFilesPerTrigger", 1) \
.load("data/input/")
Few points to note:
- Option cleanSource — It can archive or delete the source file after processing. Values can be archive, delete and default is off.
- Option sourceArchiveDir — Archive directory if the cleanSource option is set to archive.
- Option maxFilesPerTrigger — Sets how many files to process in a single go.
- We need to set spark.sql.streaming.schemaInference to True to allow streaming schemaInference.
Now, if we need to check the Schema, just replace the readStream to read for debugging
# To the schema of the data, place a sample json file and change readStream to read
streaming_df.printSchema()
streaming_df.show(truncate=False)
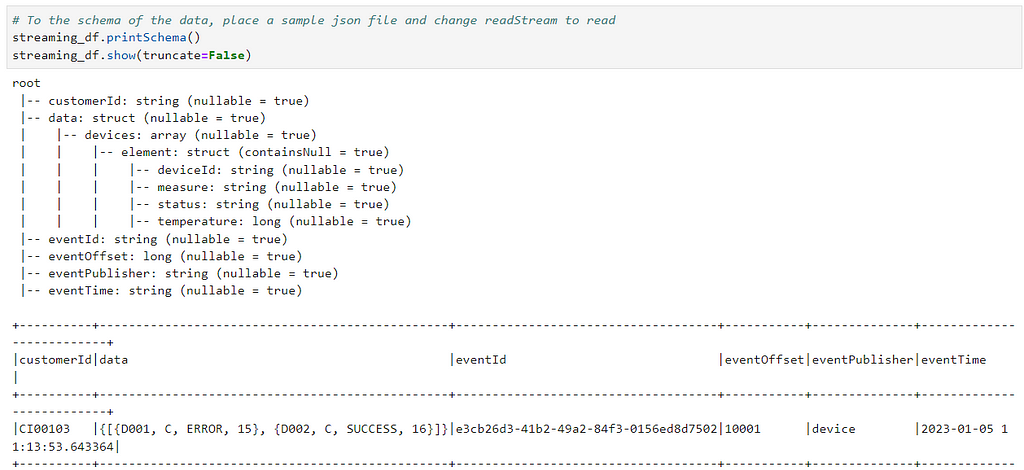
Since the data is for multiple devices in list/array we need to explode the dataframe before flattening
# Lets explode the data as devices contains list/array of device reading
from pyspark.sql.functions import explode, col
exploded_df = streaming_df \
.select("customerId", "eventId", "eventOffset", "eventPublisher", "eventTime", "data") \
.withColumn("devices", explode("data.devices")) \
.drop("data")
Flattening dataframe
# Flatten the exploded df
flattened_df = exploded_df \
.selectExpr("customerId", "eventId", "eventOffset", "eventPublisher", "eventTime",
"devices.deviceId as deviceId", "devices.measure as measure",
"devices.status as status", "devices.temperature as temperature")
Lets write the streaming data to output folder in JSON format
# Write the output to console sink to check the output
writing_df = flattened_df.writeStream \
.format("json") \
.option("path", "data/output/device_data") \
.option("checkpointLocation","checkpoint_dir") \
.outputMode("append") \
.start()
# Start the streaming application to run until the following happens
# 1. Exception in the running program
# 2. Manual Interruption
writing_df.awaitTermination()
As soon we put a new file in input directory, same is processed in real-time. See in action:
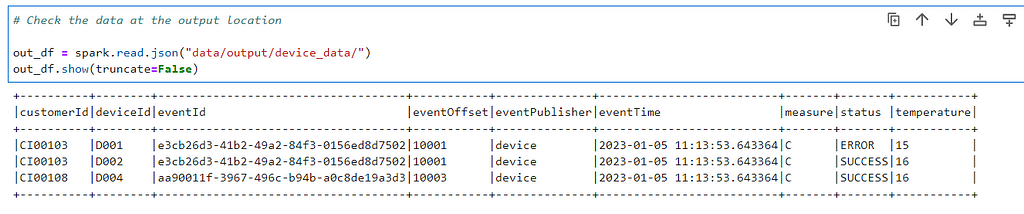
Lets check the output
# Check the data at the output location
out_df = spark.read.json("data/output/device_data/")
out_df.show(truncate=False)
Check the Spark UI, to see the micro bach executions

Checkout Structured Streaming basics — https://urlit.me/blog/pyspark-the-basics-of-structured-streaming/
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/32_spark_streaming_read_from_files.ipynb
Checkout the docker images to quickly start — https://github.com/subhamkharwal/docker-images
Checkout my Personal blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://medium.com/@subhamkharwal/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal