PySpark — Tune JDBC for Parallel effect
Now, if you are following me — Last post shared some performance optimization techniques for reading SQL Data Sources through JDBC. We looked upon Predicate Pushdown, Pushdown Query options.
Today let us tune the JDBC connection further to squeeze out each ounce of performance benefit for SQL data source reads.

In case you missed my last post on JDBC Predicate Pushdown, Checkout — https://urlit.me/blog/pyspark-jdbc-predicate-pushdown/
As usual we will do this with an example.
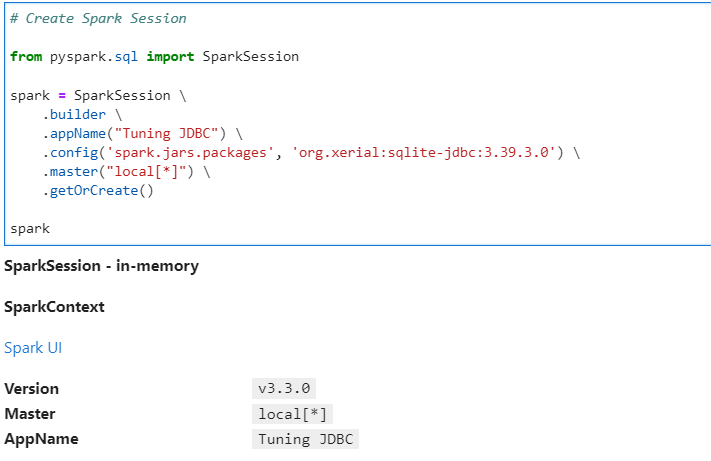
Lets create our SparkSession, with the required library files to read from a SQLite data source using JDBC.
# Create Spark Session
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Tuning JDBC") \
.config('spark.jars.packages', 'org.xerial:sqlite-jdbc:3.39.3.0') \
.master("local[*]") \
.getOrCreate()
spark
Python decorator to measure the performance. We will use “noop” format for performance benchmarking.
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())Define the SQLite JDBC parameters for SQL read
# Set up to read from JDBC SQLite database
driver: str = "org.sqlite.JDBC"
db_path: str = "dataset/jdbc/demo-sqlite.db"
jdbc_url: str = "jdbc:sqlite:" + db_path
table_name: str = "sales_csv"
Now lets read the data from database without any tuning. We are not focussing on Predicate Pushdown in this example.
Keep a note on the timings.
# Checking the performance for Full read without any Predicate Pushdown
@get_time
def x():
df_full = spark \
.read \
.format("jdbc") \
.option("driver", driver) \
.option("url", jdbc_url) \
.option("dbtable", table_name) \
.load()
df_full.write.format("noop").mode("overwrite").save()
df_full.printSchema()
print("Number of Partitons: "+ str(df_full.rdd.getNumPartitions()))

As you can see, the full read was made with single connection to the DB. There were no parallel reads made.
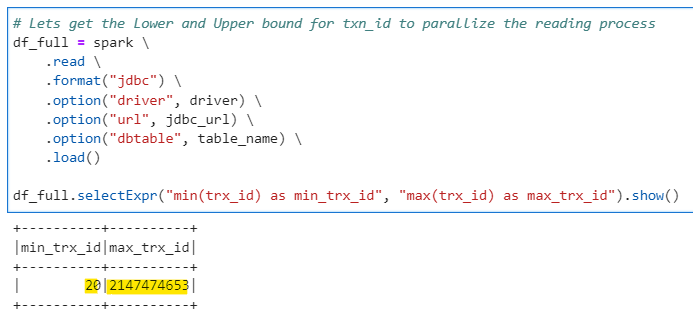
Lets optimize this. Identify a partition key with upperBound and lowerBound values to create parallel partitions. In this case, lets assume trx_id.
# Lets get the Lower and Upper bound for txn_id to parallize the reading process
df_full = spark \
.read \
.format("jdbc") \
.option("driver", driver) \
.option("url", jdbc_url) \
.option("dbtable", table_name) \
.load()
df_full.selectExpr("min(trx_id) as min_trx_id", "max(trx_id) as max_trx_id").show()
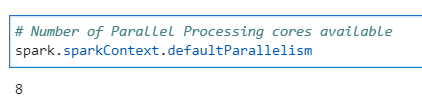
Determine the parallel processing capability
So, lets tune our JDBC connection with above parameters
# Checking the performance for with upper/lower bound with numPartitions
@get_time
def x():
df_full = spark \
.read \
.format("jdbc") \
.option("driver", driver) \
.option("url", jdbc_url) \
.option("dbtable", table_name) \
.option("partitionColumn", "trx_id") \
.option("lowerBound", 20) \
.option("upperBound", 2147474653) \
.option("numPartitions", 8) \
.load()
df_full.write.format("noop").mode("overwrite").save()
df_full.printSchema()
print("Number of Partitons: "+ str(df_full.rdd.getNumPartitions()))
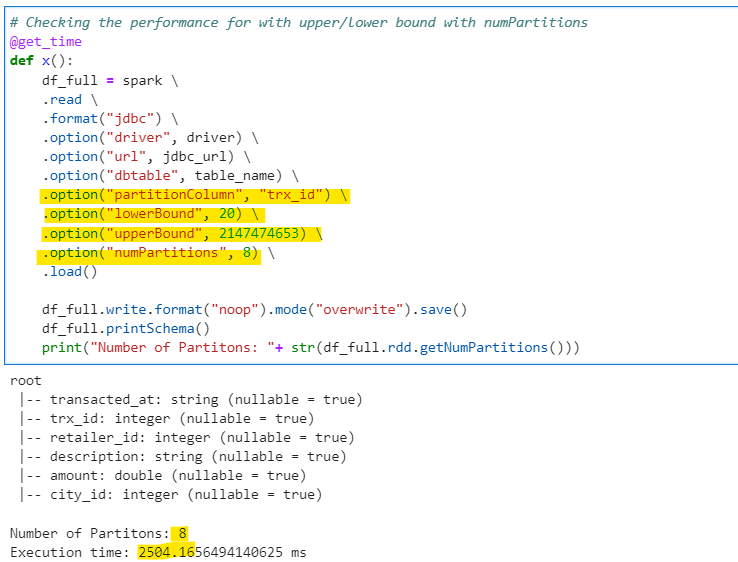
Its took almost 1/3rd time, leading to 3X times faster reads and our data is also partitioned now. This difference will change with the amount of data and variation of partitionColumn.
It is always advised to use non-skewed partitionColumn for further improvements and data distribution. Make sure to increase the numPartitions which is supported with the JDBC.
There are many more parameters available, checkout — https://spark.apache.org/docs/latest/sql-data-sources-jdbc.html
Checkout iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/16_Tuning_JDBC.ipynb
Checkout my personal blog — https://urlit.me/blog/
Checkout PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal