PySpark — The Tiny File Problem
The tiny file problem is one of the popular known problems in any system. Spark file read performance is often decided by the overheads it require to read a file.
But, Why are Tiny files a Problem ? The major reason is Overheads. When we do a job but with extra effort every time, then that's a Problem.
What are these Overheads? Checkout the parameters in Spark Documentation — https://spark.apache.org/docs/latest/sql-performance-tuning.html
Lets understand the problem with an example. We will use noop for Performance benchmarking.
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())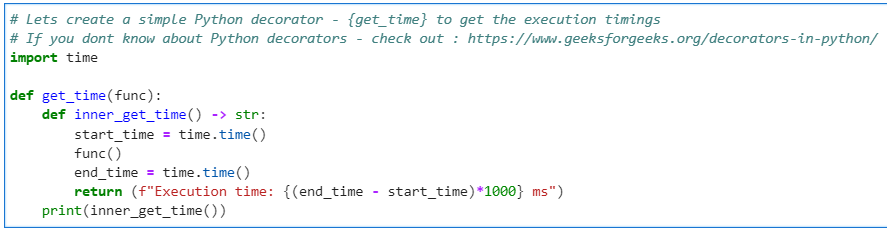
Let us first read a single Parquet file which is not partitioned of size approx. 210MB
# Lets read the single parquet file directly
@get_time
def x(): spark.read.parquet("dataset/sales.parquet").write.format("noop").mode("overwrite").save()

Now, lets read the same dataset, but this time partitioned on trx_id which created too many tiny files. Number of files that we have is 41331
# Read the trx_id partitioned parquet files
@get_time
def x(): spark.read.parquet("dataset/sales_trx_id.parquet").write.format("noop").mode("overwrite").save()

So, to read the same amount of data this time it took around 7X time extra.
What if we partitioned it properly with say city_id which created less number of files approx. 221
# Read the city_id partitioned parquet files
@get_time
def x(): spark.read.parquet("dataset/sales_city_id.parquet").write.format("noop").mode("overwrite").save()

From the above three examples its quite evident that we need to have our data partitioned properly.
So, the resolution for the problem - The answers are not so concrete but if applied properly this will help.
- Always try to write files with proper partition sizes. Use repartition() or coalesce() or set the shuffle partitions parameter properly. Bad partitioning of data during writes, is one of major reason why we have tiny files in first place.
- Compact the files to larger sizes if possible before reading. This may not be true for some file formats such as Parquet, but this can be done easily for text file formats such as CSV, TXT etc.
- Third and most important is the identification of such files. It is more often we don’t even bother to check for tiny files in our file systems. We should always try to identify such files and implement the point 1 or 2 to avoid these problem in hand.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/12_tiny_file_problem.ipynb
Checkout the PySpark series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal