PySpark — The Magic of AQE Coalesce
With the introduction of Adaptive Query Engine aka AQE in Spark, there has been a lot changes in term of Performance improvements. Bad Shuffles always had been a trouble to data engineers also trigger other problem such as skewness, spillage etc.
AQE Coalesce is now a Out of the box magic which coalesce contiguous shuffle partitions according to the target size (specified by spark.sql.adaptive.advisoryPartitionSizeInBytes), to avoid too many small tasks created.
Checkout the AQE documentation : https://spark.apache.org/docs/latest/sql-performance-tuning.html#adaptive-query-execution
So, lets check this out in action. First we check the default configuration.
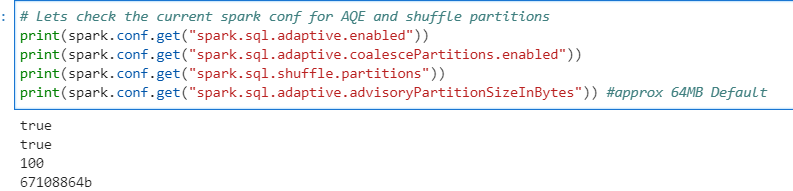
# Lets check the current spark conf for AQE and shuffle partitions
print(spark.conf.get("spark.sql.adaptive.enabled"))
print(spark.conf.get("spark.sql.adaptive.coalescePartitions.enabled"))
print(spark.conf.get("spark.sql.shuffle.partitions"))
print(spark.conf.get("spark.sql.adaptive.advisoryPartitionSizeInBytes")) #approx 64MB Default
Lets disable AQE and change Spark Shuffle Partition to random to understand it better
# Disable AQE and change Shuffle partition
spark.conf.set("spark.sql.adaptive.enabled", False)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", False)
spark.conf.set("spark.sql.shuffle.partitions", 289)

Lets read sales dataset of approx. 431MB of size and groupBy to trigger Shuffle
# Read example data set
df = spark.read.format("csv").option("header", True).load("dataset/sales.csv")
df.printSchema()
print("Initial Partition after read: " + str(df.rdd.getNumPartitions()))
# GroupBy operation to trigger Shuffle
from pyspark.sql.functions import sum
df_count = df.selectExpr("city_id","cast(amount as double) as amount_double").groupBy("city_id").agg(sum("amount_double"))
print("Output shuffle partitions: " + str(df_count.rdd.getNumPartitions()))
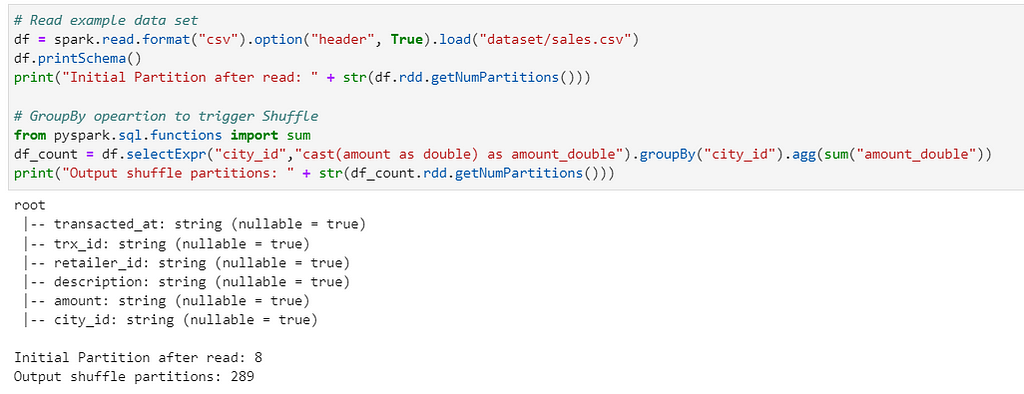
Since AQE was disabled the job created 289 partitions as we defined in shuffle partitions above.
Now, lets do the same operation by this time with AQE enabled
# Enable AQE and change Shuffle partition
spark.conf.set("spark.sql.adaptive.enabled", True)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", True)
spark.conf.set("spark.sql.shuffle.partitions", 289)

# GroupBy opeartion to trigger Shuffle
# Since our output with city_id as group by is smaller than < 64MB thus the data is written in single partiton
from pyspark.sql.functions import sum
df_count = df.selectExpr("city_id","cast(amount as double) as amount_double").groupBy("city_id").agg(sum("amount_double"))
print("Output shuffle partitions: " + str(df_count.rdd.getNumPartitions()))

Since the output dataset was less than 64MB as defined for spark.sql.adaptive.advisoryPartitionSizeInBytes , thus only single shuffle partition is created.
Now, we change the group by condition to generate more data
# GroupBy opeartion to trigger Shuffle but this time with trx_id (which is more unique - thus more data)
# Since our output with trx_id as group by is > 64MB thus the data is written in multiple partitions
from pyspark.sql.functions import sum
df_count = df.selectExpr("trx_id","cast(amount as double) as amount_double").groupBy("trx_id").agg(sum("amount_double"))
print("Output shuffle partitions: " + str(df_count.rdd.getNumPartitions()))

More number of partitions created this time. But AQE automatically took care of the coalesce to reduce unwanted partitions and reduce the number of tasks in further pipeline.
Note: its not mandatory to have all partitions with 64MB size. There are multiple other factors involved as well.
AQE Coalesce feature is available from Spark 3.2.0 and is enabled by default.
Checkout the iPython notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/11_spark_aqe.ipynb
Checkout PySpark Series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal