PySpark — The Factor of Cores
Default Parallelism is a very standout factor in Spark executions. Basically its the number of tasks Spark can raise in parallel and it very well depends on the number of cores we have for execution.

For a well optimized data load, it is very important to tune the degree of parallelism and the factor of core comes into play. Default Parallelism in Spark is defined as the total number of cores available for execution.
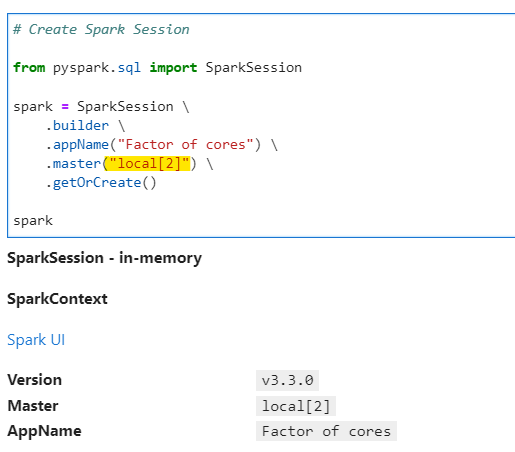
Let run through a quick example to understand the same. We define the our environment with two cores for simple understanding and visualization of problem.
# Create Spark Session
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Factor of cores") \
.master("local[2]") \
.getOrCreate()
spark
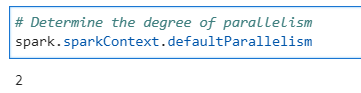
Available parallelism now
# Determine the degree of parallelism
spark.sparkContext.defaultParallelism
Disable all AQE features for baseline
# Disable all AQE optimization for benchmarking tests
spark.conf.set("spark.sql.adaptive.enabled", False)
spark.conf.set("spark.sql.adaptive.localShuffleReader.enabled", False)
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", False)
We would execute the following code for performance benchmarking.
# Code for benchmarking
from pyspark.sql.functions import count, lit
@get_time
def x():
df = spark.read.format("parquet").load("dataset/sales.parquet/")
df.groupBy("trx_id").agg(count(lit(1))).write.format("noop").mode("overwrite").save()

Test 1: Change the Spark Shuffle partition to non-factor of 2 (default parallelism) say for example to 9
# Define shuffle partitions which is not Factor of core
spark.conf.set("spark.sql.shuffle.partitions", 9)

So if we check the performance from the Spark UI


Now, its evident that one of the core has to do an extra task, which increased the time.
Test 2: We set the shuffle partitions to factor of core for example say 8, now if we check the performance

So, no extra effort here, thus the timing for execution is also less.
This also stands true for re-partitioning of data.
Test 3: Repartition data to a number of partitions which is not factor of cores.
# Not re-partitiong with factor
spark.read.format("parquet").load("dataset/sales.parquet/").repartition(9).write.format("noop").mode("overwrite").save()


Again, extra effort by one core.
Test 4: Repartition data to a number of partitions which is factor of cores.
# Repartitiong based on factor of cores
spark.read.format("parquet").load("dataset/sales.parquet/").repartition(8).write.format("noop").mode("overwrite").save()


Since, the number of partitions are factor of cores thus, no extra effort here.
Conclusion: It is always recommended to set the shuffle partitions or the number of re-partitioned data to a factor of number of cores available for execution. This example is just to give you a hint, consider a Production scenario where each task takes around 30 min to complete, you would never want to wait extra 30 min just because of a simple misconfiguration.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/22_Factor_of_cores.ipynb
Checkout my personal blog — https://urlit.me/blog/
Checkout the PySpark Series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal