PySpark — Read/Parse JSON column from another Data Frame
There are many scenarios where we store raw JSON payload in a column of Data Frame. Now for further processing we need to Read/Parse that JSON payload and create new Data Frames.
Consider a use case, where we have two pipelines — one which reads streaming/API data and write into a raw data frame and the other reads/parses that raw data frame and process the JSON payload.
Checkout the following code which reads the JSON schema dynamically for Schema evolution and parses accordingly.
Lets create an example Data Frame with JSON Payload as column.
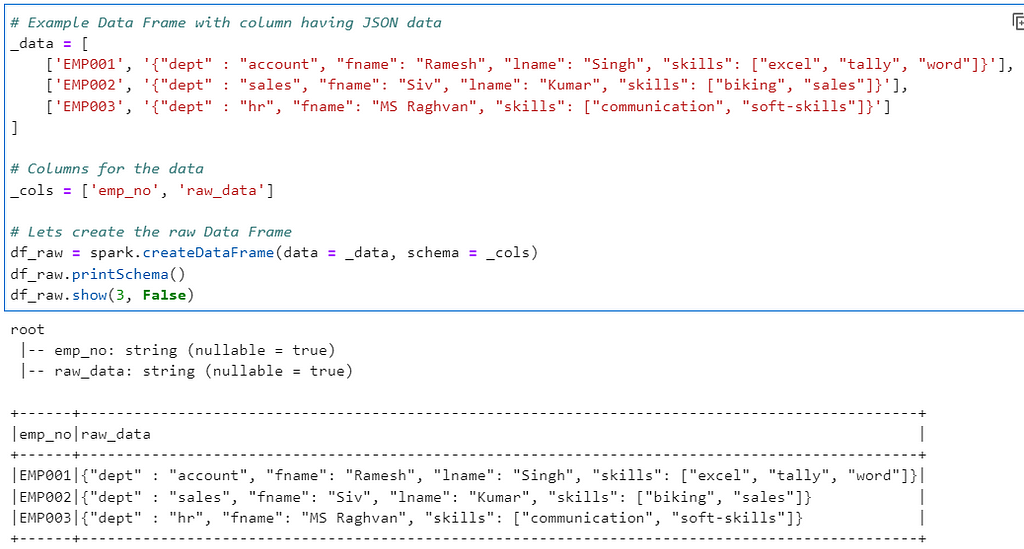
# Example Data Frame with column having JSON data
_data = [
['EMP001', '{"dept" : "account", "fname": "Ramesh", "lname": "Singh", "skills": ["excel", "tally", "word"]}'],
['EMP002', '{"dept" : "sales", "fname": "Siv", "lname": "Kumar", "skills": ["biking", "sales"]}'],
['EMP003', '{"dept" : "hr", "fname": "MS Raghvan", "skills": ["communication", "soft-skills"]}']
]
# Columns for the data
_cols = ['emp_no', 'raw_data']
# Lets create the raw Data Frame
df_raw = spark.createDataFrame(data = _data, schema = _cols)
df_raw.printSchema()
df_raw.show(3, False)
Lets parse the schema for the column dynamically for Schema evolution(detect schema changes)
# Determine the schema of the JSON payload from the column
json_schema_df = spark.read.json(df_raw.rdd.map(lambda row: row.raw_data))
json_schema = json_schema_df.schema

Now, we parse the column data with above schema
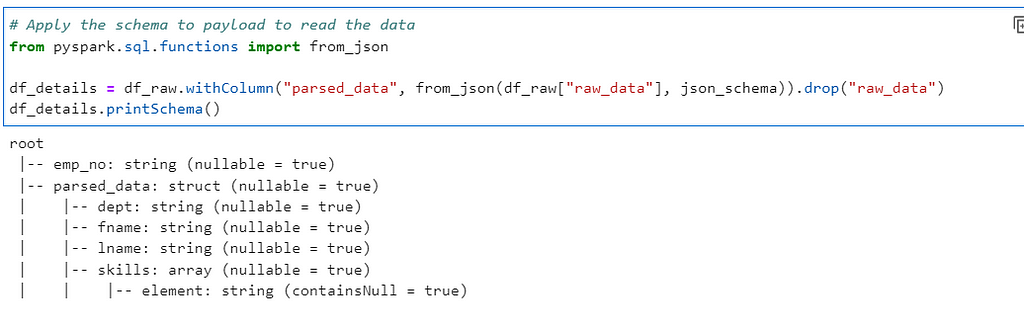
# Apply the schema to payload to read the data
from pyspark.sql.functions import from_json
df_details = df_raw.withColumn("parsed_data", from_json(df_raw["raw_data"], json_schema)).drop("raw_data")
df_details.printSchema()
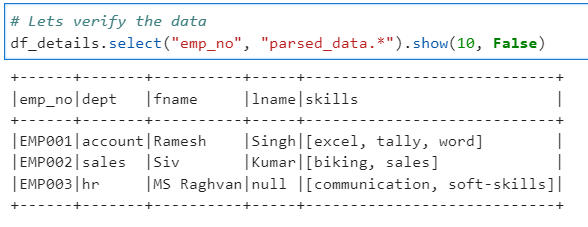
# Lets verify the data
df_details.select("emp_no", "parsed_data.*").show(10, False)
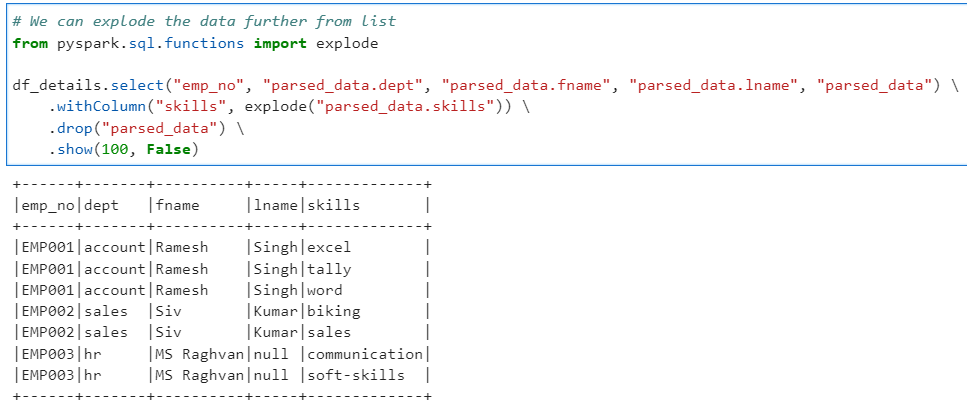
In case you want to explode the array field for data flattening
# We can explode the data further from list
from pyspark.sql.functions import explode
df_details.select("emp_no", "parsed_data.dept", "parsed_data.fname", "parsed_data.lname", "parsed_data") \
.withColumn("skills", explode("parsed_data.skills")) \
.drop("parsed_data") \
.show(100, False)
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/4_read_json_from_df_column.ipynb
Checkout more such articles at: https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal