PySpark — Optimize Pivot Data Frames like a PRO
Pivoting data is a very common scenario in every data engineering pipeline. Spark provides out-of-the-box pivot() method to do the job right. But, do you know we have a performance trade off in Spark Data Frame using pivot(), if it is not used properly.
Lets check that out in action.
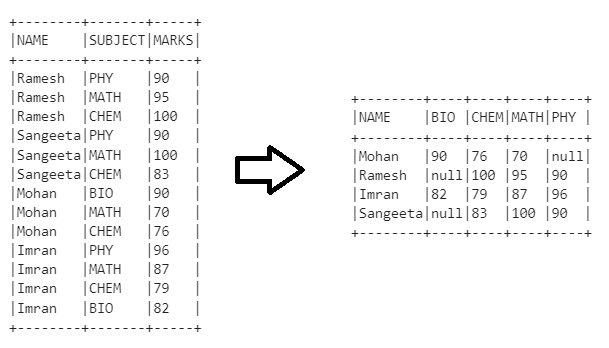
First, we create our example Data Frame
# Example Data Set
_data = [
["Ramesh", "PHY", 90],
["Ramesh", "MATH", 95],
["Ramesh", "CHEM", 100],
["Sangeeta", "PHY", 90],
["Sangeeta", "MATH", 100],
["Sangeeta", "CHEM", 83],
["Mohan", "BIO", 90],
["Mohan", "MATH", 70],
["Mohan", "CHEM", 76],
["Imran", "PHY", 96],
["Imran", "MATH", 87],
["Imran", "CHEM", 79],
["Imran", "BIO", 82]
]
_cols = ["NAME", "SUBJECT", "MARKS"]
# Generate Data Frame
df = spark.createDataFrame(data=_data, schema = _cols)
df.show(truncate = False)
To measure the performance, we will create a simple Python decorator.
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())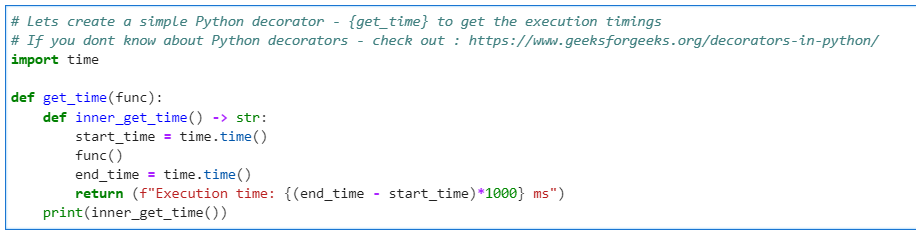
Method 1 — Pivoting the data without specifying the Pivot column names
# Pivot data without specifying the column names(values) and checking the execution time
from pyspark.sql.functions import sum
@get_time
def x(): df.groupBy("NAME").pivot("SUBJECT").agg(sum("MARKS"))

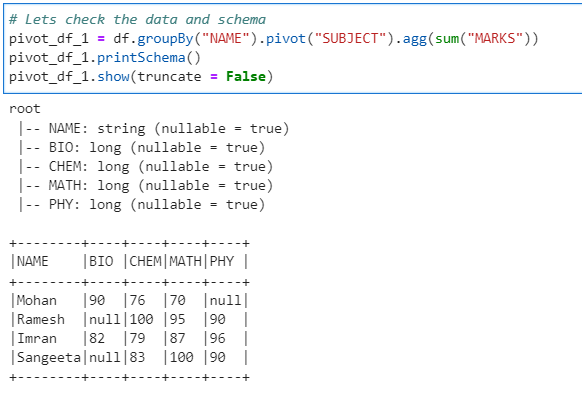
Checking the data
# Lets check the data and schema
pivot_df_1 = df.groupBy("NAME").pivot("SUBJECT").agg(sum("MARKS"))
pivot_df_1.printSchema()
pivot_df_1.show(truncate = False)
Method 2 — Specifying the column names
First, we have to get the distinct column names from the SUBJECT column
# Get the distinct list of Subjects
_subjects = df.select("SUBJECT").distinct().rdd.map(lambda x: x[0]).collect()
_subjects

Now, if we use the distinct column name for PIVOT
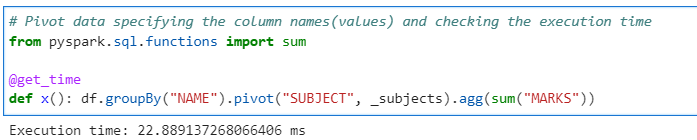
# Pivot data specifying the column names(values) and checking the execution time
from pyspark.sql.functions import sum
@get_time
def x(): df.groupBy("NAME").pivot("SUBJECT", _subjects).agg(sum("MARKS"))
Check the data
# Lets check the data and schema
pivot_df_2 = df.groupBy("NAME").pivot("SUBJECT", _subjects).agg(sum("MARKS"))
pivot_df_2.printSchema()
pivot_df_2.show(truncate = False)
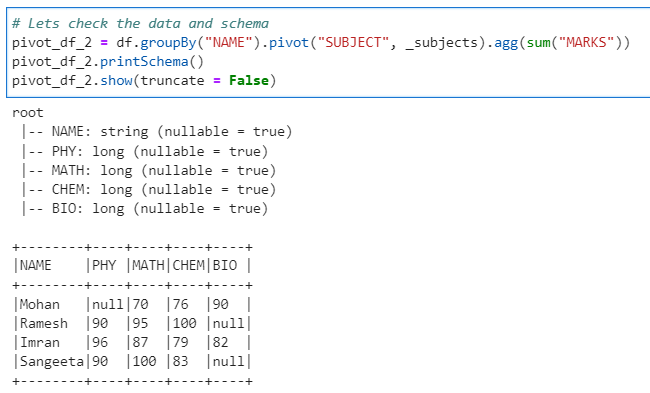
As we can see the second time with column names specified the pivot() method ran much quicker.
Conclusion: We can now easily conclude that if the column names are specified the execution is much quicker. But, don’t forget the execution time required to get the distinct columns as well.
So, If the column name are already known/pre-specified for a larger dataset, we should always try to specify them.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/7_pivot_data_frame.ipynb
Checkout the PySpark Series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal