PySpark — Merge Data Frames with different Schema
In order to merge data from multiple systems, we often come across situations where we might need to merge data frames which doesn’t have same columns or the columns are in different order.
union() and unionByName() are two famous method that comes into play when we want to merge two Data Frames. But, there is a small catch to it.
Union works with column sequences i.e. both Data Frames should have same columns and in-order. On the other hand, UnionByName does the same job but with column names. So, until we have same columns in both data frames we can merge them easily.
Lets check out this in action. First we will create our example Data Frames
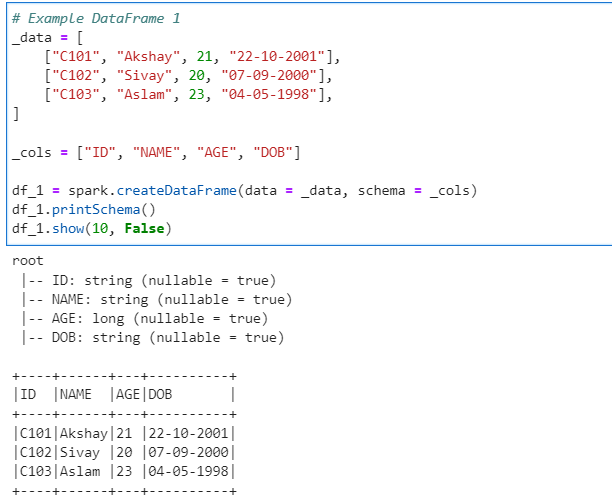
# Example DataFrame 1
_data = [
["C101", "Akshay", 21, "22-10-2001"],
["C102", "Sivay", 20, "07-09-2000"],
["C103", "Aslam", 23, "04-05-1998"],
]
_cols = ["ID", "NAME", "AGE", "DOB"]
df_1 = spark.createDataFrame(data = _data, schema = _cols)
df_1.printSchema()
df_1.show(10, False)
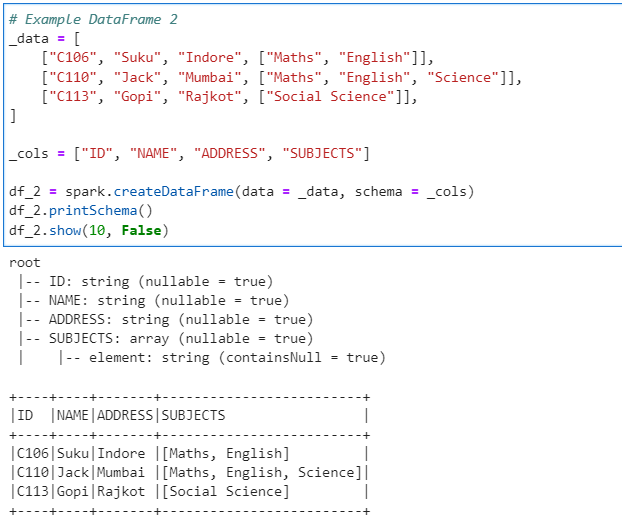
# Example DataFrame 2
_data = [
["C106", "Suku", "Indore", ["Maths", "English"]],
["C110", "Jack", "Mumbai", ["Maths", "English", "Science"]],
["C113", "Gopi", "Rajkot", ["Social Science"]],
]
_cols = ["ID", "NAME", "ADDRESS", "SUBJECTS"]
df_2 = spark.createDataFrame(data = _data, schema = _cols)
df_2.printSchema()
df_2.show(10, False)
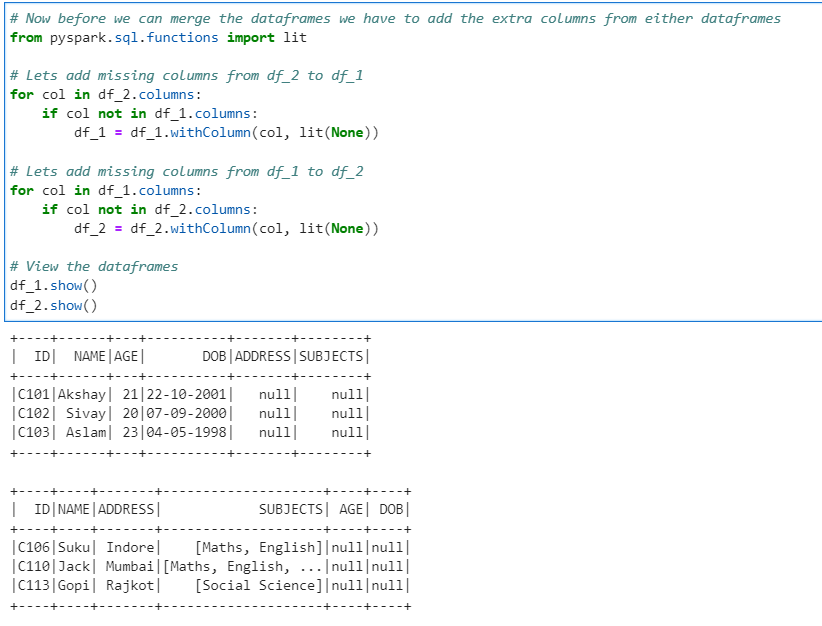
Now, we add missing columns from either Data Frames
# Now before we can merge the dataframes we have to add the extra columns from either dataframes
from pyspark.sql.functions import lit
# Lets add missing columns from df_2 to df_1
for col in df_2.columns:
if col not in df_1.columns:
df_1 = df_1.withColumn(col, lit(None))
# Lets add missing columns from df_1 to df_2
for col in df_1.columns:
if col not in df_2.columns:
df_2 = df_2.withColumn(col, lit(None))
# View the dataframes
df_1.show()
df_2.show()
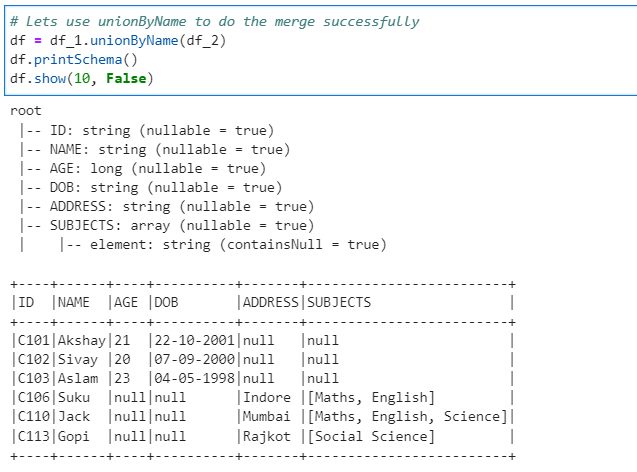
Finally, we are ready to merge
# Lets use unionByName to do the merge successfully
df = df_1.unionByName(df_2)
df.printSchema()
df.show(10, False)
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/6_merge_df_with_different_schema.ipynb
Checkout PySpark Medium series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal