PySpark — Dynamic Partition Overwrite
INSERT OVERWRITE is a very wonderful concept of overwriting few partitions rather than overwriting the whole data in partitioned output. We have seen this implemented in Hive, Impala etc. But can we implement the same Apache Spark?
Yes, we can implement the same functionality in Spark with Version > 2.3.0 with a small configuration change with write mode “overwrite” itself.
As usual, we will follow along with an example to test this implementation. To implement this functionality we will change the following Spark Parameter
spark.sql.sources.partitionOverwriteMode — Check out Spark documentation https://spark.apache.org/docs/3.0.0/configuration.html
Test 1: We overwrite the partitions for the data with default value for partitionOverwriteMode i.e. STATIC
Lets create our Initial example dataset
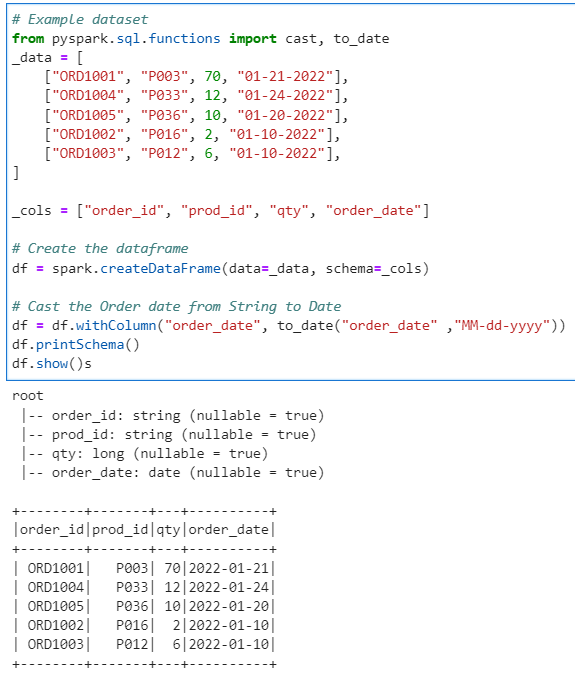
# Example dataset
from pyspark.sql.functions import cast, to_date
_data = [
["ORD1001", "P003", 70, "01-21-2022"],
["ORD1004", "P033", 12, "01-24-2022"],
["ORD1005", "P036", 10, "01-20-2022"],
["ORD1002", "P016", 2, "01-10-2022"],
["ORD1003", "P012", 6, "01-10-2022"],
]
_cols = ["order_id", "prod_id", "qty", "order_date"]
# Create the dataframe
df = spark.createDataFrame(data=_data, schema=_cols)
# Cast the Order date from String to Date
df = df.withColumn("order_date", to_date("order_date" ,"MM-dd-yyyy"))
df.printSchema()
df.show()
Current/Default configuration for spark.sql.sources.partitionOverwriteMode
# Check the mode for Partition Overwrite
spark.conf.get("spark.sql.sources.partitionOverwriteMode")

Repartition and save the Initial dataset, we have 4 partition with order_date
# Lets repartition the data with order_date and write
df.repartition("order_date") \
.write \
.format("parquet") \
.partitionBy("order_date") \
.mode("overwrite") \
.save("dataset/orders_partitioned")
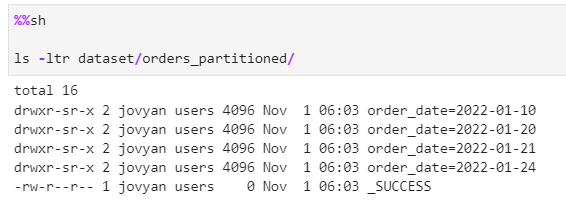
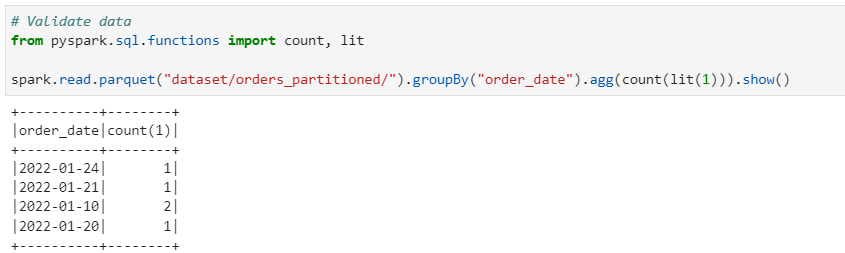
Generate the new delta dataset for overwrite
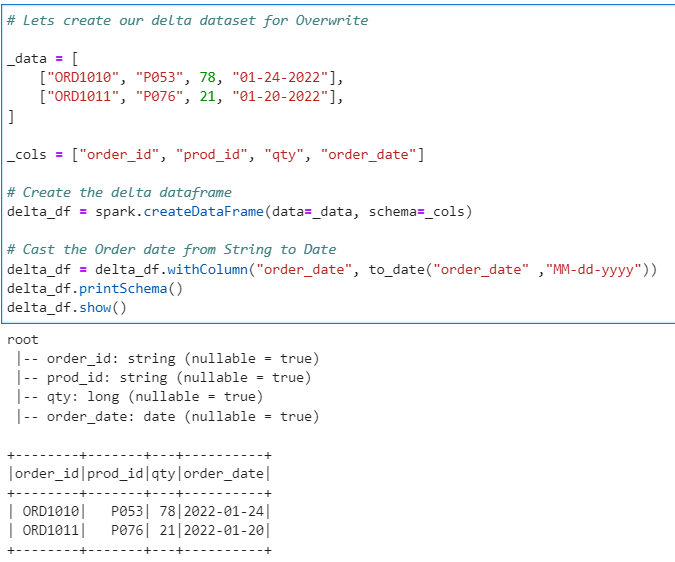
# Lets create our delta dataset for Overwrite
_data = [
["ORD1010", "P053", 78, "01-24-2022"],
["ORD1011", "P076", 21, "01-20-2022"],
]
_cols = ["order_id", "prod_id", "qty", "order_date"]
# Create the delta dataframe
delta_df = spark.createDataFrame(data=_data, schema=_cols)
# Cast the Order date from String to Date
delta_df = delta_df.withColumn("order_date", to_date("order_date" ,"MM-dd-yyyy"))
delta_df.printSchema()
delta_df.show()
Now, we overwrite the delta data with default configuration
# Lets write to the same location for Orders partitioned
delta_df.repartition("order_date") \
.write \
.format("parquet") \
.partitionBy("order_date") \
.mode("overwrite") \
.save("dataset/orders_partitioned")
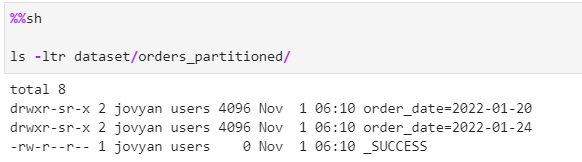
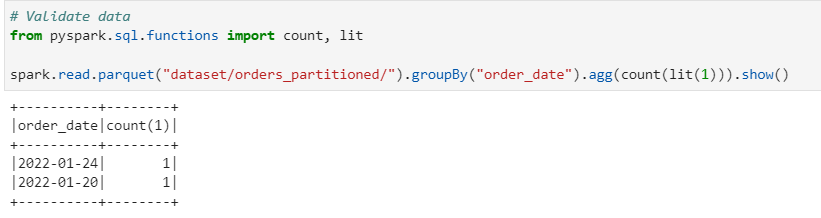
From the above test we conclude, The data is completely overwritten for all existing partitions from Initial data with Delta dataset.
Test 2: We overwrite the partitions for the data with partitionOverwriteMode as DYNAMIC
We follow the same above steps but this time we set the configuration value to DYNAMIC
# Setting the partitionOverwriteMode as DYNAMIC
spark.conf.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
spark.conf.get("spark.sql.sources.partitionOverwriteMode")

Initial dataset
# Example dataset
from pyspark.sql.functions import cast, to_date
_data = [
["ORD1001", "P003", 70, "01-21-2022"],
["ORD1004", "P033", 12, "01-24-2022"],
["ORD1005", "P036", 10, "01-20-2022"],
["ORD1002", "P016", 2, "01-10-2022"],
["ORD1003", "P012", 6, "01-10-2022"],
]
_cols = ["order_id", "prod_id", "qty", "order_date"]
# Create the dataframe
df = spark.createDataFrame(data=_data, schema=_cols)
# Cast the Order date from String to Date
df = df.withColumn("order_date", to_date("order_date" ,"MM-dd-yyyy"))
df.printSchema()
df.show()
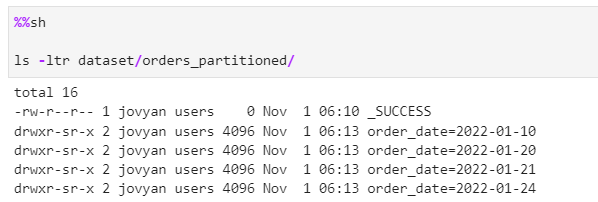
Write the partitioned Initial dataset
# Lets repartition the data with order_date and write
df.repartition("order_date") \
.write \
.format("parquet") \
.partitionBy("order_date") \
.mode("overwrite") \
.save("dataset/orders_partitioned")
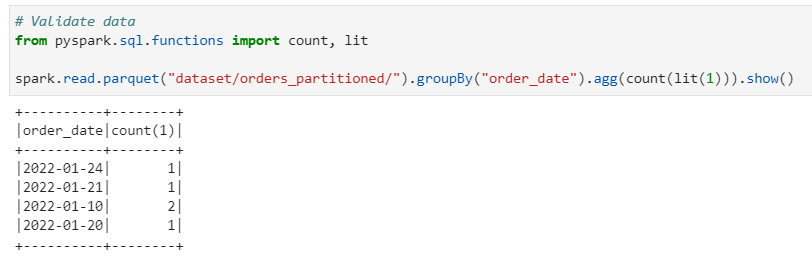
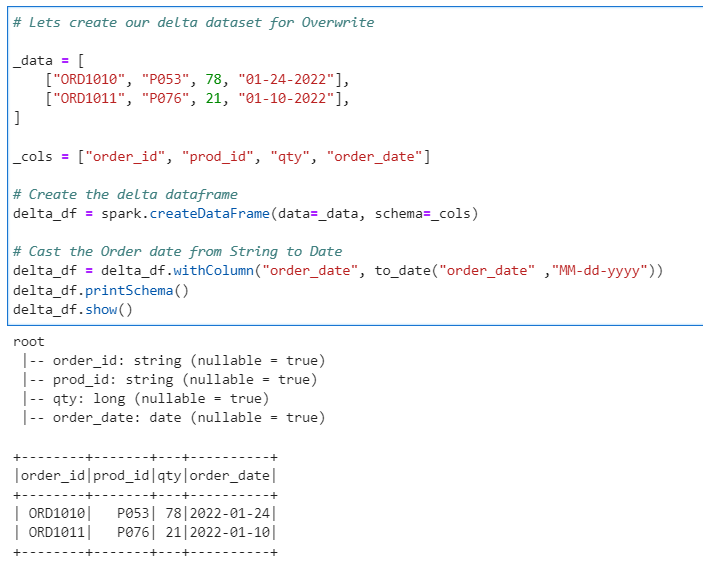
We create the same delta dataset
# Lets create our delta dataset for Overwrite
_data = [
["ORD1010", "P053", 78, "01-24-2022"],
["ORD1011", "P076", 21, "01-10-2022"],
]
_cols = ["order_id", "prod_id", "qty", "order_date"]
# Create the delta dataframe
delta_df = spark.createDataFrame(data=_data, schema=_cols)
# Cast the Order date from String to Date
delta_df = delta_df.withColumn("order_date", to_date("order_date" ,"MM-dd-yyyy"))
delta_df.printSchema()
delta_df.show()
Now, we write the dataset with same mode “overwrite”
# Lets write to the same location for Orders partitioned
delta_df.repartition("order_date") \
.write \
.format("parquet") \
.partitionBy("order_date") \
.mode("overwrite") \
.save("dataset/orders_partitioned")
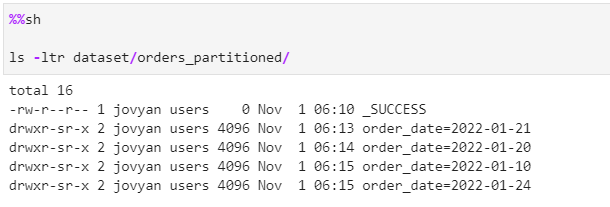
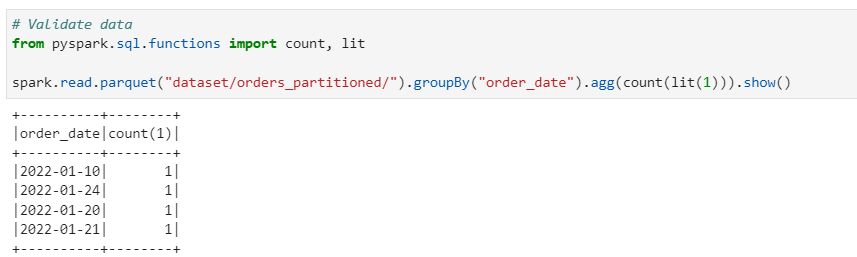
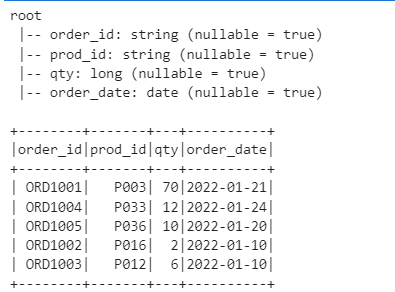
As its evident from above test, the partitioned in the delta dataset are only overwritten rather than the whole dataset.
Note: This will only work with partitioned dataset.
Conclusion: We can achieve INSERT OVERWRITE functionality in Spark > 2.3.0 with configuration parameter for changed for Partition Overwrite to dynamic.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/24_Partition_Overwrite.ipynb
Checkout my Personal blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal