PySpark — Delta Lake Integration using Manifest
Delta Lake enables to read data from Other sources such as Presto, AWS Athena with the help of Symlink manifest file.
To integrate other sources we have to generate a manifest file from the delta table. This manifest file lists the data files of the current version after all operations on the table.
Consider the following delta lake table.
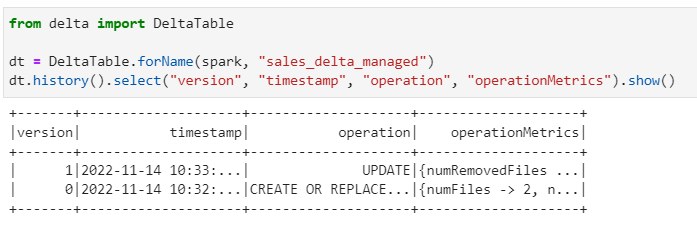
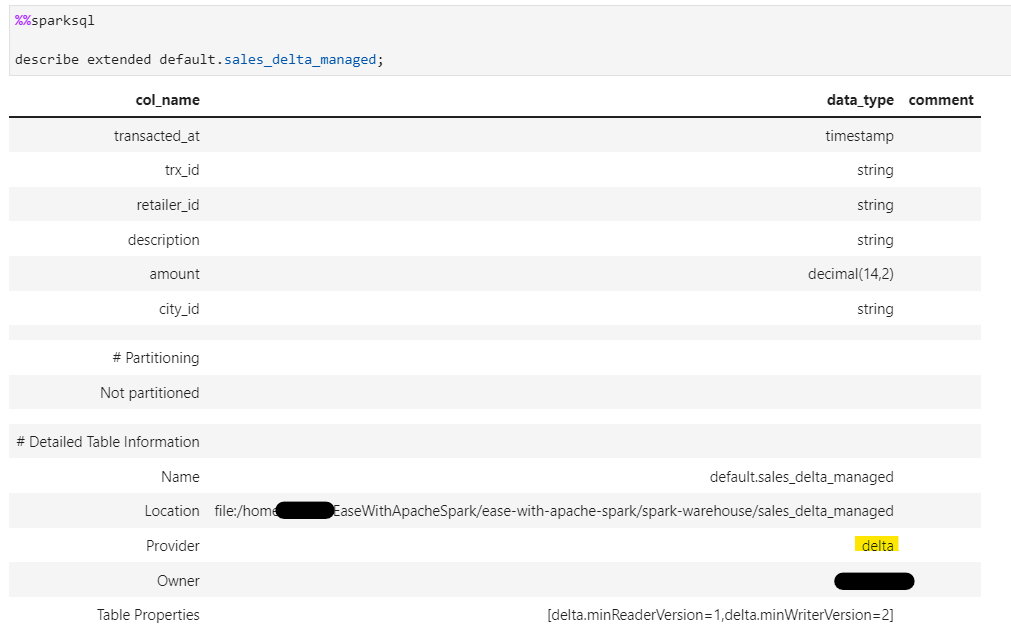
Now, if we create an External Athena table directly on the location, we will have issues as all versions of data files still exists in the same location.
So, to fix that we will generate a manifest and point the Athena table to read data files with help of manifest.
# Generate the symlink manifest for the delta table
dt.generate("symlink_format_manifest")
This command creates a new folder within table folder location with manifest file as shown below:
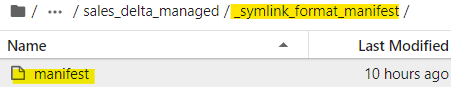
And the contents of the manifest, contains the name of the latest data files

Presto or Athena reads only the files mentioned in manifest file to fetch the latest data from the table avoiding the duplicates due to versions.
To generate & update the manifest files automatically after each delta table operation and avoid manual intervention, set the following Table parameter with delta table:
TBLPROPERTIES(delta.compatibility.symlinkFormatManifest.enabled=true)
Now, what do we do if we want read the data from an External HIVE table? The answers is not straight as Hive doesn’t support manifest file reading out of the box.
We have to go through a little trick here. Now, lets create the Hive table to check data first, pointing to the delta table location.
%%sparksql
CREATE TABLE default.sales_hive_table
(
transacted_at timestamp,
trx_id string,
retailer_id string,
description string,
amount decimal(14,2),
city string
)
STORED AS PARQUET
LOCATION "sales_delta_managed/"
;
Now, if we check the data between both tables, we see the hive table shows almost double data which is due to duplications from the old version files.
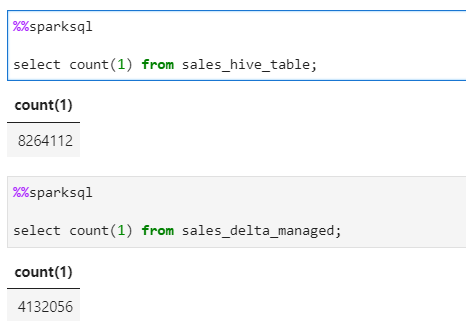
Now, lets vaccum the delta table to “0” to reatain only the latest data files and remove the rest.
# Vaccum the delta table to read from hive
spark.conf.set("spark.databricks.delta.retentionDurationCheck.enabled","false")
dt.vacuum(0)
Now lets refresh the hive table and check the data.
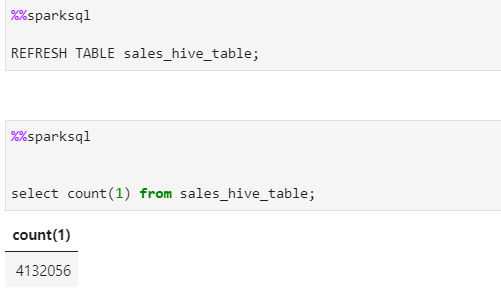
As, its evident that Hive table now shows the correct count/data. But, vacuuming the delta table while read and write operations can lead to table corruption.
So, its always advised to use the above operation very carefully.
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/29_delta_read_from_hive.ipynb
Checkout my Personal blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal