PySpark — Delta Lake Column Mapping
Delta Lake validates the schema of data that is being written to it. It supports explicit DDL operations to alter table schema definitions. Following are the types of changes that Delta Lake currently supports:
- Adding of new columns
- Re-ordering of columns
- Removing or Renaming columns(few features are still experimental)
We would look into the third point — Removing or Renaming Columns.
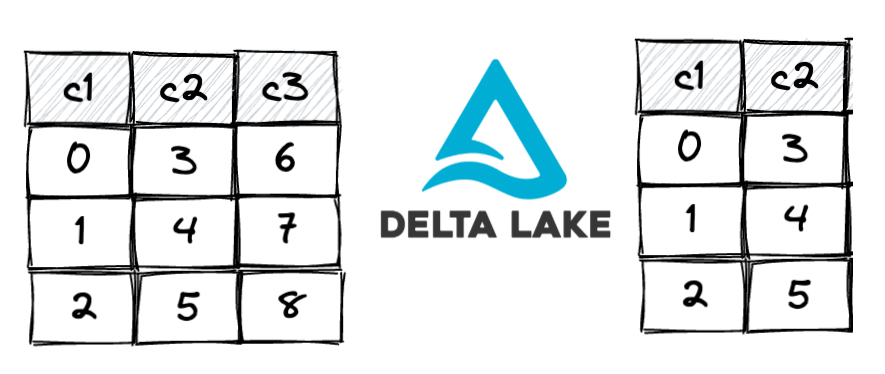
In situations where we need to update the schema of an existing table we also requires to change the schema of underlying data. But Delta table enables us with a fantastic option called - Column Mappings.
And to use the same, we need to change the protocol version of the existing table.

To know more about Protocol version, checkout — https://docs.delta.io/latest/versioning.html
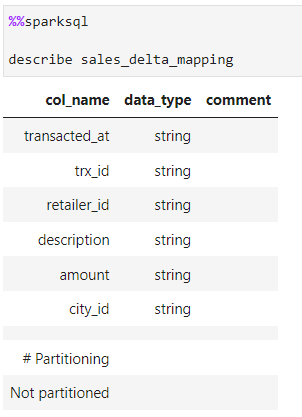
Lets run through an example to checkout this feature. We start my creating a demo delta table “spark_delta_mapping”
%%sparksql
create table sales_delta_mapping
using delta
as
select * from sales_managed;
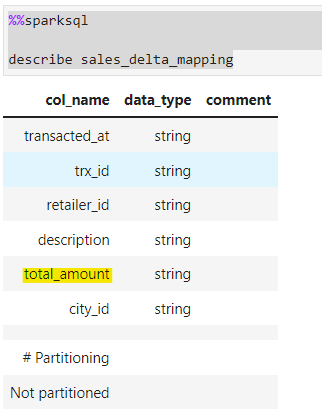
Now, in case we want to rename column amount => total_amount, we have to change the schema of the underlying data as well.
# Renaming column with underlying data
spark.read.table("sales_delta_mapping") \
.withColumnRenamed("trx_id", "transaction_id") \
.write \
.format("delta") \
.mode("overwrite") \
.option("overwriteSchema", "true") \
.saveAsTable("sales_delta_mapping")
And this step, requires scanning of whole dataset and re-writing the same into the table.
Same is the case for dropping a column say transaction_id (which we renamed in previous step)
# Dropping column with underlying data
spark.read.table("sales_delta_mapping") \
.drop("transaction_id") \
.write \
.format("delta") \
.mode("overwrite") \
.option("overwriteSchema", "true") \
.saveAsTable("sales_delta_mapping")
Now, if we enable and use the Column Mapping feature, Delta Lake maintains the lineage/column mapping internally and we now don’t need to change the schema of the underlying data. Thus, performance is optimized.
Lets enable the same on our demo table. Make a note of the protocols being used.
%%sparksql
ALTER TABLE sales_delta_mapping SET TBLPROPERTIES (
'delta.columnMapping.mode' = 'name',
'delta.minReaderVersion' = '2',
'delta.minWriterVersion' = '5')
;
Now, we alter the column, and check the schema
%%sparksql
alter table sales_delta_mapping rename column amount to total_amount;
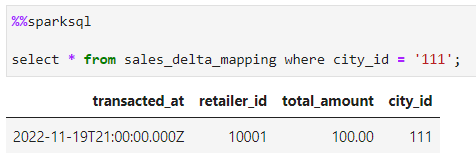
Now lets drop a column description
%%sparksql
alter table sales_delta_mapping drop column description;
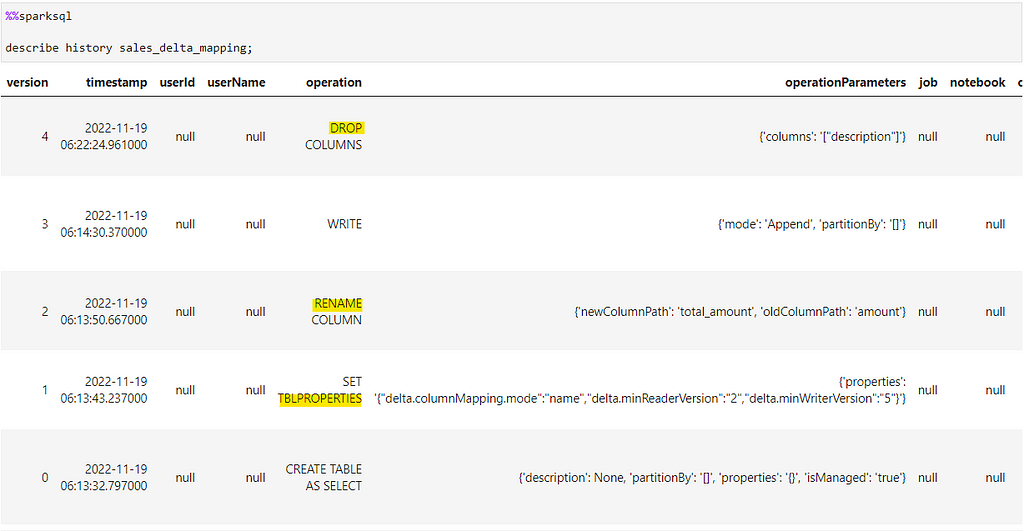
So, if we check the history for the changes of the table
WARNING from delta.io: Protocol version upgrades are irreversible, and upgrading the protocol version may break the existing Delta Lake table readers, writers, or both.
Please make sure to check and experiment on the data, before moving this feature onto Production tables as certain features are still in experimental mode and can lead to data loss.
Checkout the Delta Lake documentation — https://docs.delta.io/latest/versioning.html#column-mapping
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/28_delta_column_mapping.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal