PySpark — DAG & Explain Plans
Understand How Spark divides Jobs into Stages and Tasks?
Knowing what happens when we send a job or application in Spark for execution is really important. We usually ignore it because we don’t realize how crucial it is. But if we want to get why it matters, DAGs and Explain plans can help us figure it out.

Today we will understand how Spark divides a simple job into Stages and tasks and how can DAG and Explain plan help us to understand it.
Now if you are new to Spark, PySpark or want to learn more — I teach Big Data, Spark, Data Engineering & Data Warehousing on my YouTube Channel — Ease With Datahttps://medium.com/media/bc2c16be6ddb2223368ba8421c13f202/href
Example
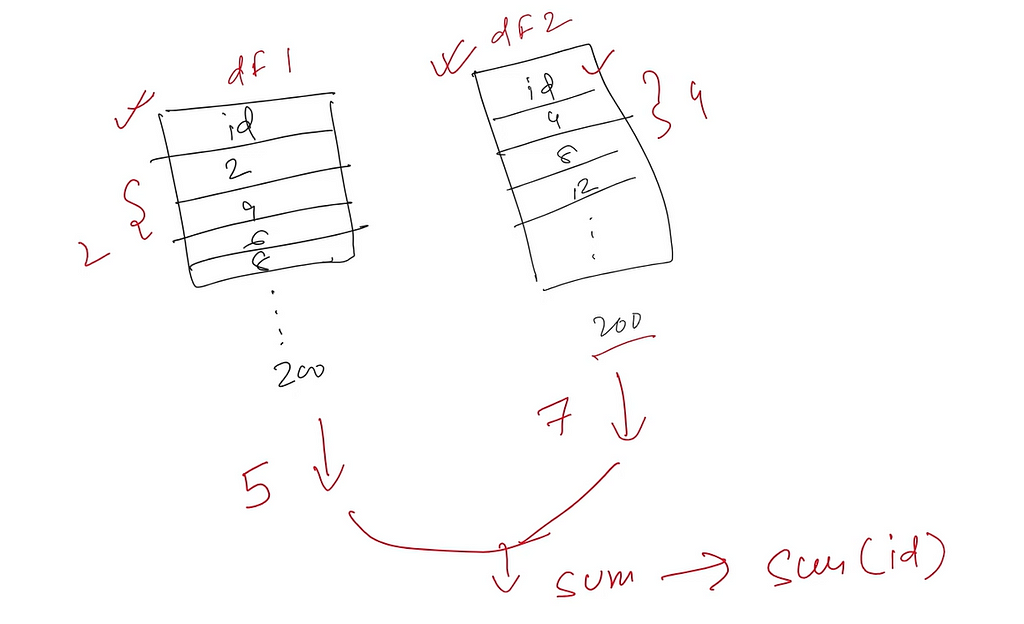
1. We will consider two Spark DataFrames (df_1 and df_2) with even numbers till 200 with only 1 column “id” and with step of 2 and 4 respectively.
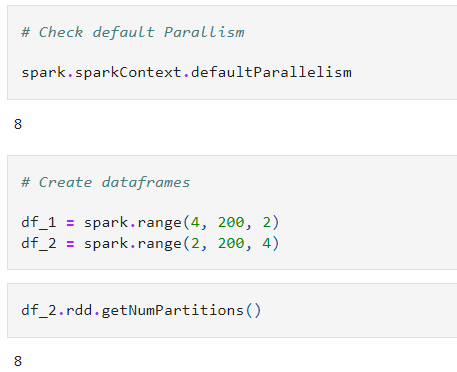
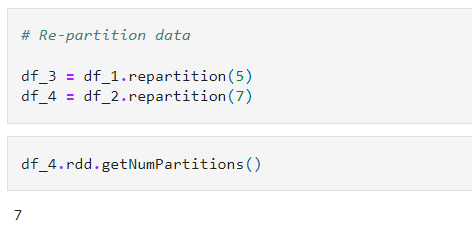
2. Next we will repartition those DataFrames in 5 and 7 partitions respectively.
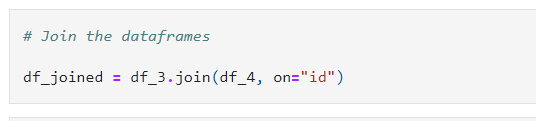
3. Once the DataFrames are re-partitioned, we will join them(inner join on id column) to create a joined DF.
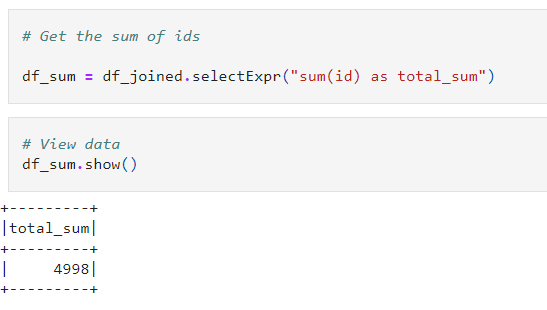
4. And at last, we will find the sum of all “id” from the joined DataFrame.
Flow diagram of complete example (pardon my handwriting) :
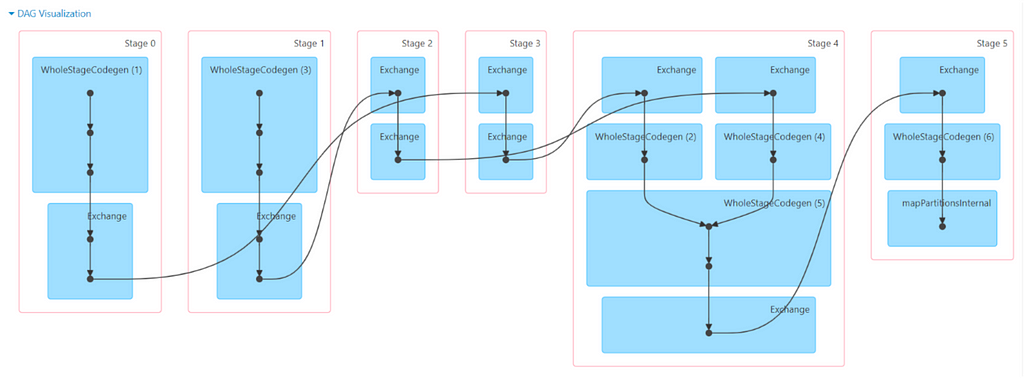
Now once we trigger the Action in Step 4 you can see the job in Spark UI with DAG as below(notice how a simple task can create complex DAG)
Also the Explain Plan for Step 4
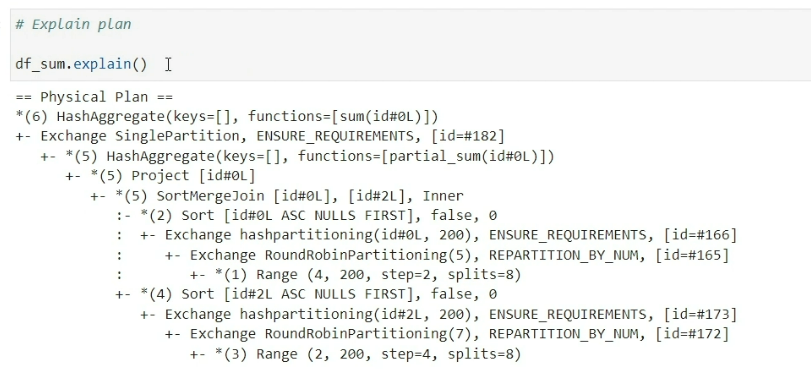
Now, to notice which part of Explain Plan is related to which step of the DAG check the numbers mentioned in the DAG step and Explain Plan step.
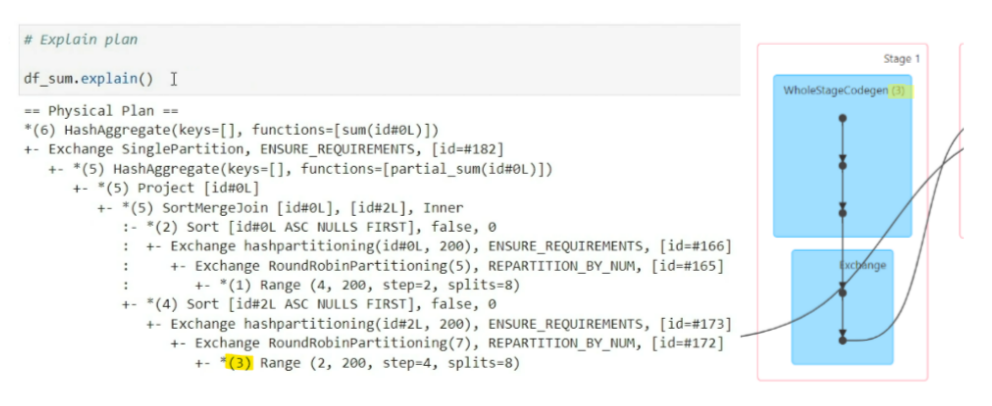
So, if we repeat the same process again, we can read the complete DAG with relation to Explain Plan.
Now, to count the number of Stages and Tasks, we need to find the number of partitions of data at each step and number of Shuffle or Exchange involved.
The Process
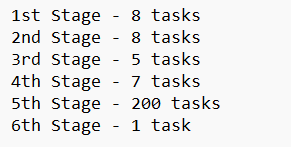
For Step 1: We read two DF with 8 partition each, so 2 stages will read with 8 partition (8 tasks) each. Shuffle data will be written after reading as next Step is repartition.
For Step 2: We are repartitioning both DF so there is shuffle involved, thus 2 new stages will be created with each of 5 and 8 partitions each. Shuffle data will be written as next step is join which will also involve data exchange.
For Step 3: We will read the data from repartitioned DFs and after joining will write the data in 200 partitions(default shuffle partition for Spark in 200) for Sum (thus 200 tasks) with 1 new stage.
For Step 4: 1 Stage and 1 task will be created to show the sum(action) which will read all 200 partition Shuffle write data from the joined DF.
So, here is the break up of the Stages and tasks:
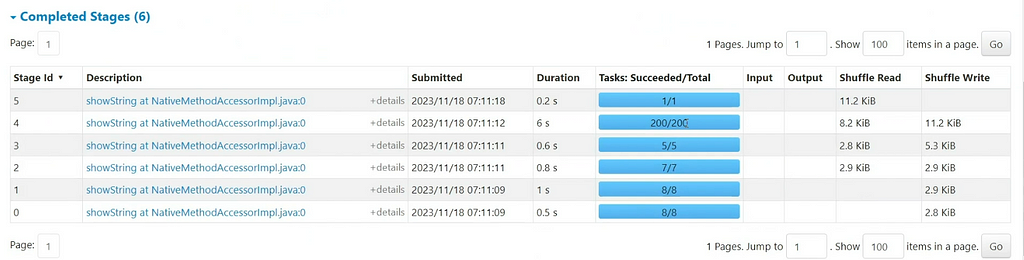
And this is what we can see in the Spark UI as well, notice how Spark write and reads data once Shuffle or Exchange is involved (Shuffle Read/Write). And this is accordance to the DAG and Explain Plan generated.
If you still in doubt, check out this YouTube video if you want to understand the same with more clarity.
https://medium.com/media/cc7f9afdcdc9f3b88257ba3a46ec3f6a/hrefConclusion ✌️
So, we can now understand how Spark resolves complex DAGs with simple Stages and Tasks to make things easier in background. Note: for this example we disables AQE and Broadcast join.
Now if you are new to Spark, PySpark or want to learn more — I teach Big Data, Spark, Data Engineering & Data Warehousing on my YouTube Channel — Ease With Data
Make sure to Like and Subscribe ❤️
Checkout Ease With Data YouTube Channel: https://www.youtube.com/@easewithdata
Wish to connect with me: https://topmate.io/subham_khandelwal
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/pyspark-zero-to-hero/blob/master/14_understand_dag_plan.ipynb
Checkout my Personal Blog — https://urlit.me/blog/
Checkout the PySpark Medium Series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal