PySpark — Count(1) vs Count(*) vs Count(col_name)
More often we are confused to choose correct the way for getting count from a table, where none of them is wrong. But which one is the most proficient one? Is it count(1) or count(*) or count(col_name)?
Both count(1) and count(*) basically gives you the total count of records, whereas count(col_name) basically gives you the count of NOT NULL records on that column.
Spark has its own way to deal with the above situation. As usual lets check this out with example.
We will create a Python decorator and use format “noop” for performance benchmarking.
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())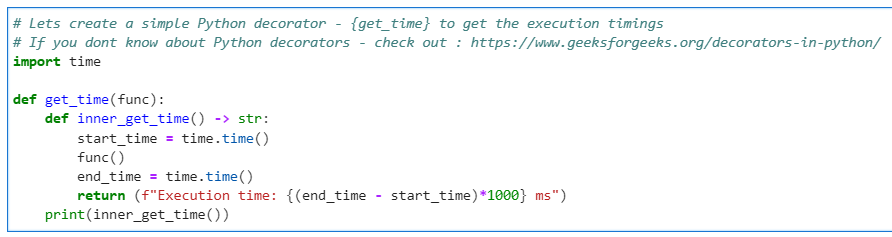
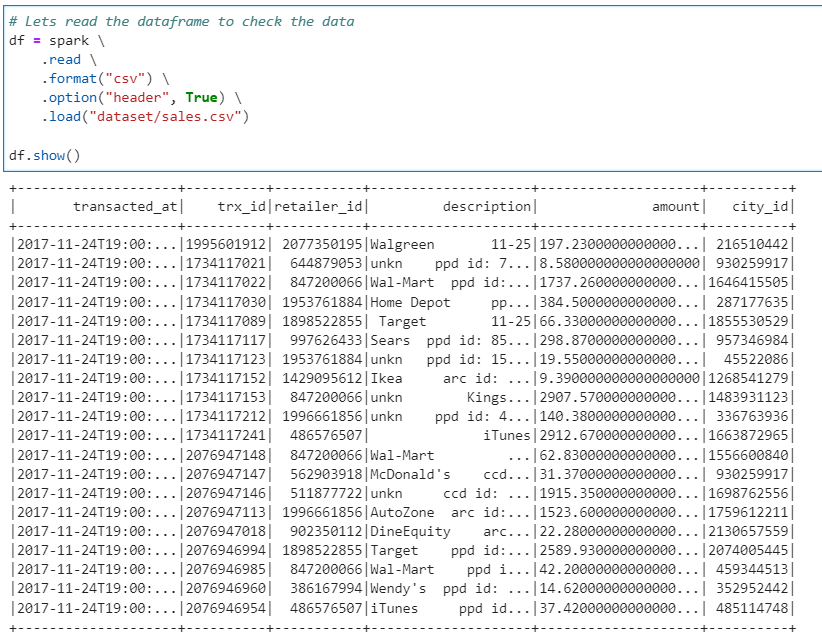
Our example dataset.
# Lets read the dataframe to check the data
df = spark \
.read \
.format("csv") \
.option("header", True) \
.load("dataset/sales.csv")
df.show()
Now to test the performance between the different ways of count, lets groupBy on trx_id.
COUNT(1) performance
# Get count(1) performance
from pyspark.sql.functions import lit, count
@get_time
def x(): df.groupBy("trx_id").agg(count(lit(1))).write.format("noop").mode("overwrite").save()

COUNT(*) performance
# Get count(*) performance
@get_time
def x(): df.groupBy("trx_id").agg(count("*")).write.format("noop").mode("overwrite").save()

COUNT(col_name) performance
# Get count(col_name) performance
@get_time
def x(): df.groupBy("trx_id").agg(count("city_id")).write.format("noop").mode("overwrite").save()

Now, if you keeping eye on the time of the results, count(1) and count(*) has almost same performance, but for count(col_name) its a little degraded.
But why is that? Only way to find out is to check the Explain Plans for all three to understand what’s happening under the hood.
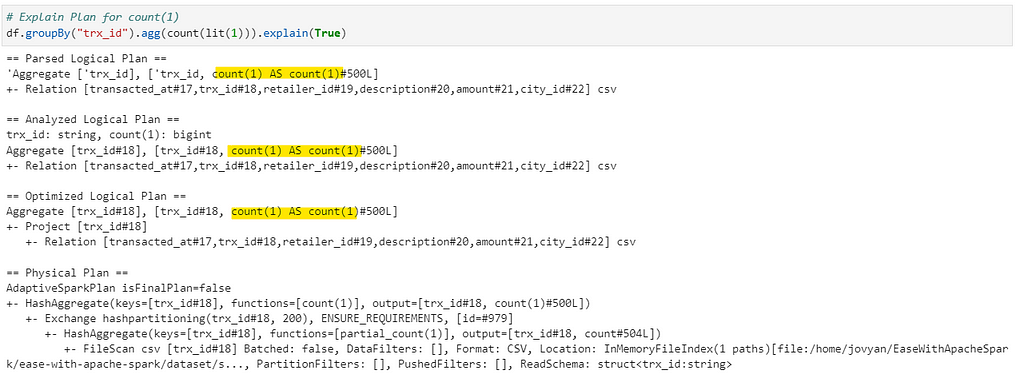
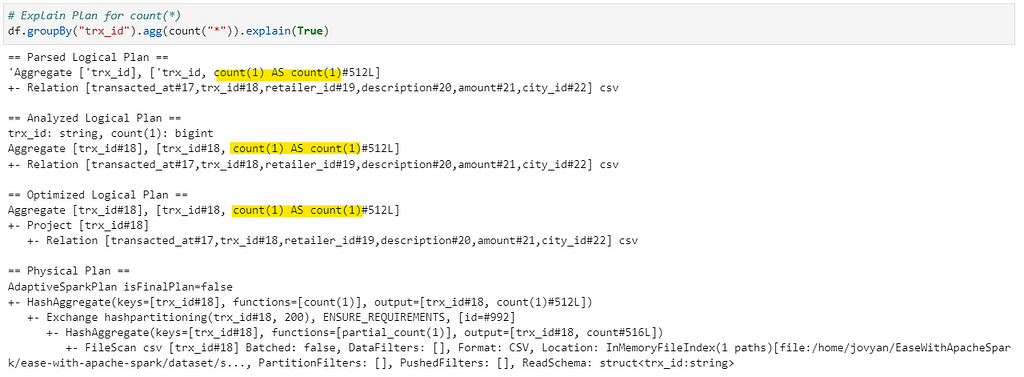
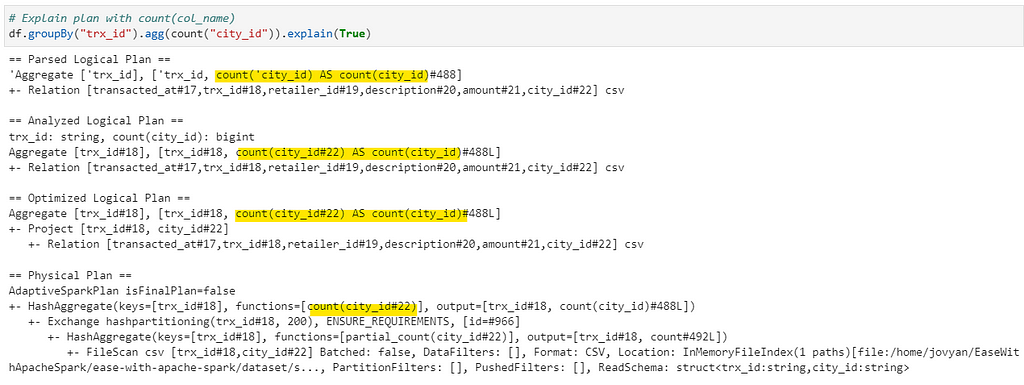
If you notice the highlighted segment in the explain plans, count(1) and count(*) has the same plan (function = [count(1)]) with no change at all, whereas in count(city_id) — Spark applies function=[count(city_id)], which has to iterate over column to check for null values.
Note: These results might vary with complexity of implementations. But, in all ideal cases it should result as demonstrated.
Conclusion: In case of count(1) and count(*) we have almost same performance (as explain plans are same) but with count(col_name) we can have slight performance hit, but that’s OK as sometimes we need to get the correct count based on columns.
So, next time you can choose the correct one for implementation or answer wisely to the question of the interviewer :)
Checkout the iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/18_count_explain_plan_comp.ipynb
Checkout my personal blog — https://urlit.me/blog/
Checkout PySpark Medium series — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Wish to Buy me a Coffee: Buy Subham a Coffee
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal