PySpark — Columnar Read Optimization
Parquet, ORC etc are very popular Columnar File formats used in Big Data for data storage and retrieval. These are popular choice for fast analytics workloads.
To check about different columnar file format, checkout — http://urlit.me/t43HI
We are going to see how we can proactively optimize our data read operations from those columnar files.
For our example we are going to consider Parquet file format, which are popularly used for their Big Data Data Warehousing use cases.
Without delay, lets jump into action mode. Our Parquet example file (118M of size).

As usual we will create out Python decorator for performance measurement.
# Lets create a simple Python decorator - {get_time} to get the execution timings
# If you dont know about Python decorators - check out : https://www.geeksforgeeks.org/decorators-in-python/
import time
def get_time(func):
def inner_get_time() -> str:
start_time = time.time()
func()
end_time = time.time()
return (f"Execution time: {(end_time - start_time)*1000} ms")
print(inner_get_time())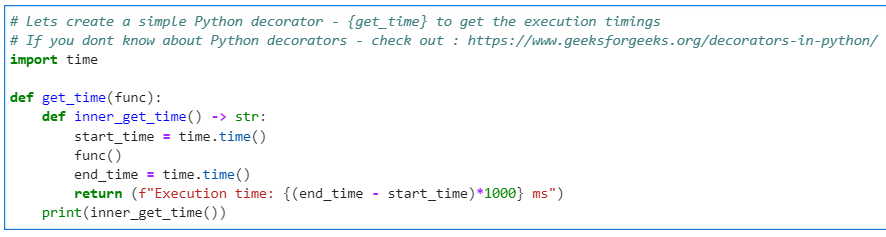
We are going to use “noop” format for performance benchmarking. Keep a note of the timings.
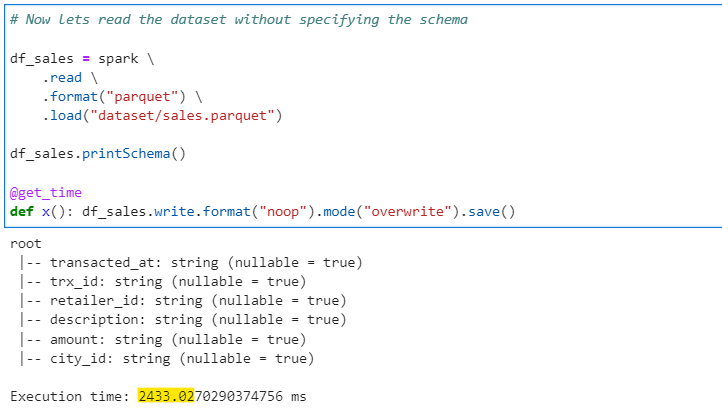
Method 1 — Lets read the data without specifying any schema. This will allow spark to read the schema on the fly.
# Now lets read the dataset without specifying the schema
df_sales = spark \
.read \
.format("parquet") \
.load("dataset/sales.parquet")
df_sales.printSchema()
@get_time
def x(): df_sales.write.format("noop").mode("overwrite").save()
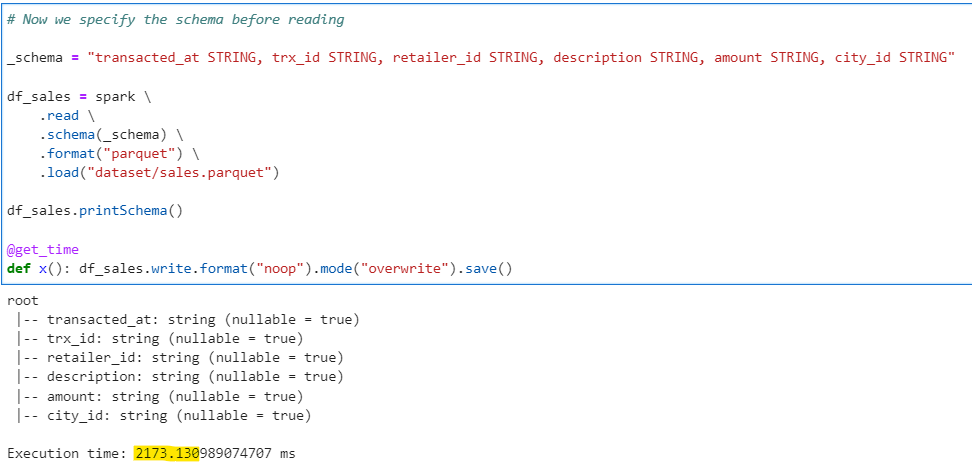
Method 2 — Reading data with schema specified
# Now we specify the schema before reading
_schema = "transacted_at STRING, trx_id STRING, retailer_id STRING, description STRING, amount STRING, city_id STRING"
df_sales = spark \
.read \
.schema(_schema) \
.format("parquet") \
.load("dataset/sales.parquet")
df_sales.printSchema()
@get_time
def x(): df_sales.write.format("noop").mode("overwrite").save()
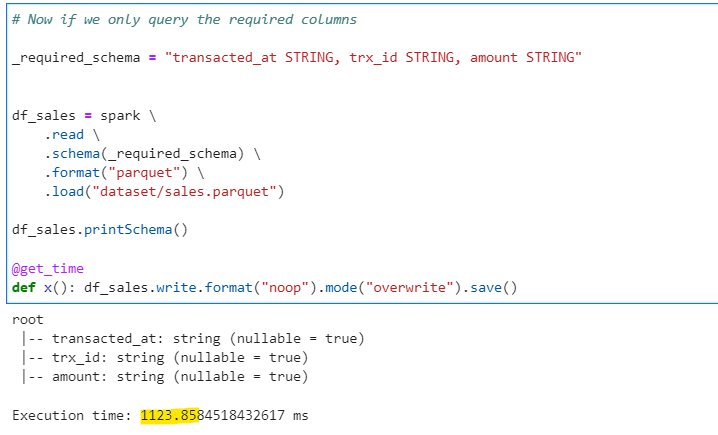
Method 3 — Reading data with only required columns, not all columns
# Now if we only query the required columns
_required_schema = "transacted_at STRING, trx_id STRING, amount STRING"
df_sales = spark \
.read \
.schema(_required_schema) \
.format("parquet") \
.load("dataset/sales.parquet")
df_sales.printSchema()
@get_time
def x(): df_sales.write.format("noop").mode("overwrite").save()
Method 4 — Reading data with required columns using select()
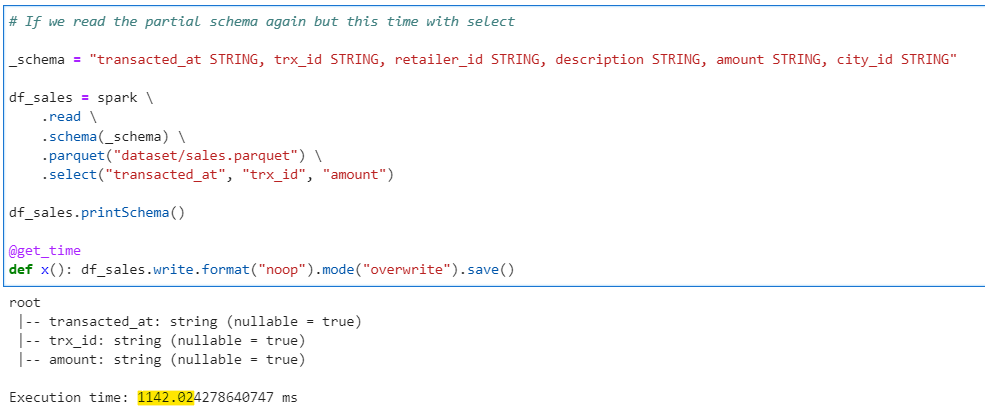
# If we read the partial schema again but this time with select
_schema = "transacted_at STRING, trx_id STRING, retailer_id STRING, description STRING, amount STRING, city_id STRING"
df_sales = spark \
.read \
.schema(_schema) \
.parquet("dataset/sales.parquet") \
.select("transacted_at", "trx_id", "amount")
df_sales.printSchema()
@get_time
def x(): df_sales.write.format("noop").mode("overwrite").save()
Method 5 — Reading required columns using drop() to remove un-necessary columns
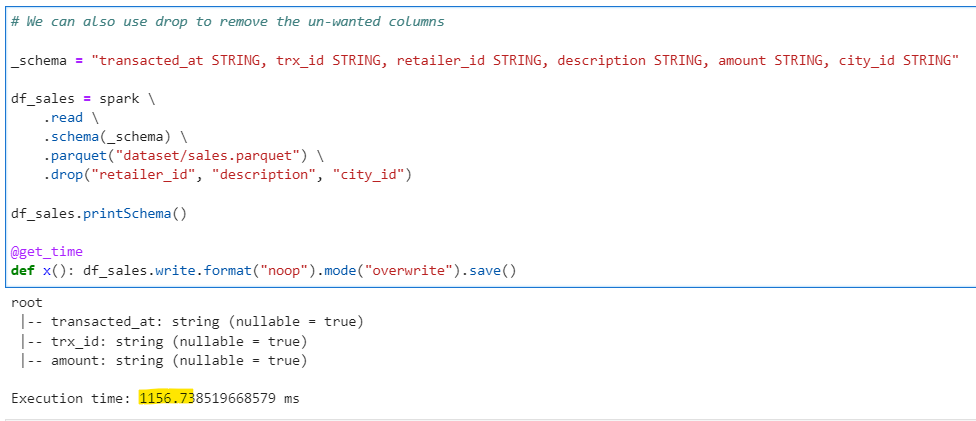
# We can also use drop to remove the un-wanted columns
_schema = "transacted_at STRING, trx_id STRING, retailer_id STRING, description STRING, amount STRING, city_id STRING"
df_sales = spark \
.read \
.schema(_schema) \
.parquet("dataset/sales.parquet") \
.drop("retailer_id", "description", "city_id")
df_sales.printSchema()
@get_time
def x(): df_sales.write.format("noop").mode("overwrite").save()
Note: The above result will change with the number of columns and size of dataset. With increase, the timing difference will also vary significantly.
Conclusion — As demonstrated, if we specify schema during columnar reads with required columns only, the read time can be cut-off by huge margin. We can use specify schema directly or use select/drop for the same.
Checkout iPython Notebook on Github — https://github.com/subhamkharwal/ease-with-apache-spark/blob/master/10_columnar_data_optimization.ipynb
Checkout PySpark Series on Medium — https://subhamkharwal.medium.com/learnbigdata101-spark-series-940160ff4d30
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal