Data Lakehouse with PySpark — Setup PySpark Docker Jupyter Lab env
As part of the series Data Lakehouse with PySpark, we need to setup the PySpark environment on Docker in Jupyter lab. Today we are going to set up the same in few simple steps. This environment can further be used for your personal use-cases and practise.

If you are still not following, checkout the playlist on YouTube — https://youtube.com/playlist?list=PL2IsFZBGM_IExqZ5nHg0wbTeiWVd8F06b
There are few prerequisites for the environment setup, check below image. We will not need AWS account for now, but will definitely needed in future course.

Now, install docker desktop on your machine. You can download it from Docker official website — https://www.docker.com/.
The setup is pretty straight forward and will not need any speciality.
Turn on the docker desktop and wait until the Docker Engine colour changes to GREEN.
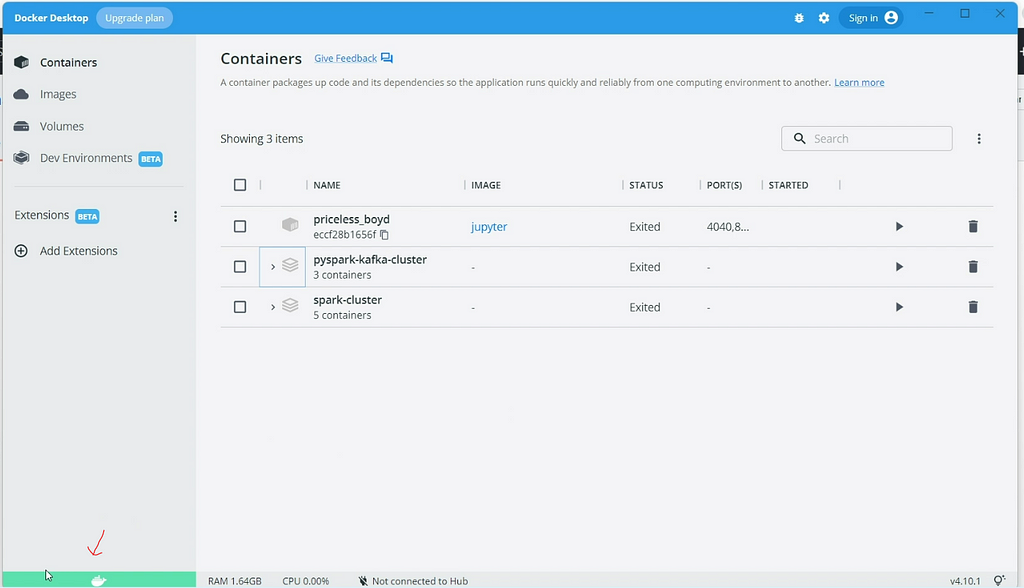
Go ahead and clone/download the Docker images Github repo — https://github.com/subhamkharwal/docker-images.
Once cloned/downloaded move into the folder pyspark-jupyter-lab and open Command prompt to run the following command which will build the required docker image.
docker build --tag easewithdata/pyspark-jupyter-lab .
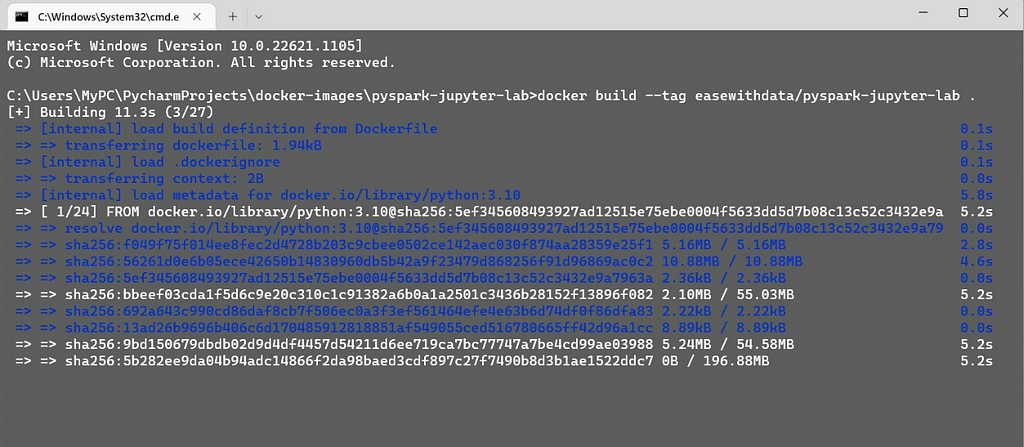
The command will run for sometime depending on the internet bandwidth, once complete you can find the image listed in your Docker desktop.
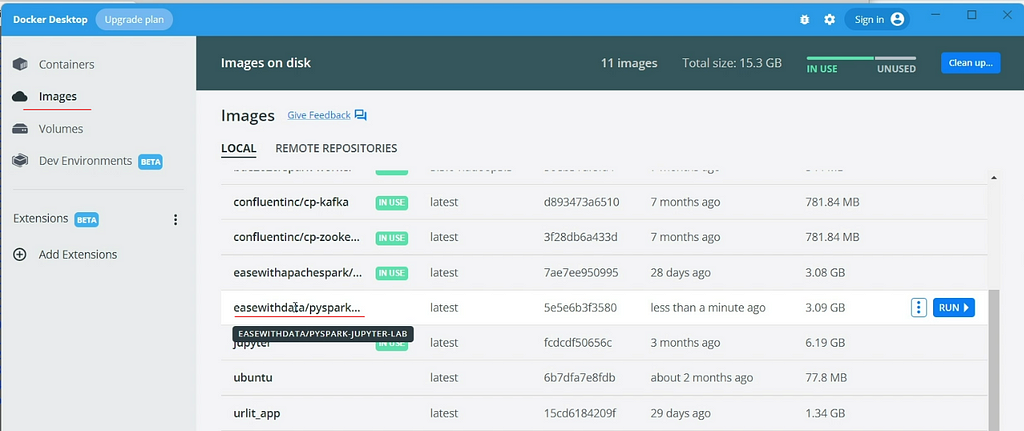
Now, run the following command to create the container, which will run our PySpark Jupyter Lab env on Docker.
docker run -d -p 8888:8888 -p 4040:4040 --name jupyter-lab easewithdata/pyspark-jupyter-lab
You can find one container created in the containers tab.
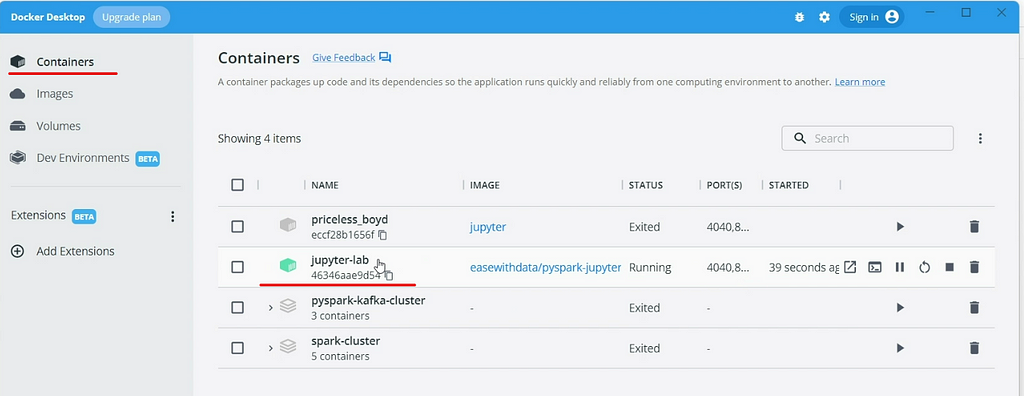
Copy the token from the jupyter-lab container logs by clicking on jupyter-lab container.
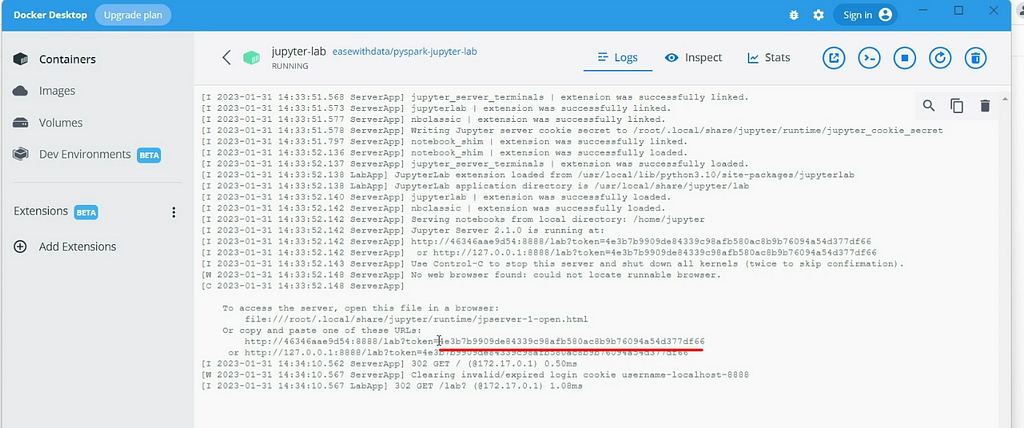
Now, open http://localhost:8888 to login into the Jupyter Lab environment. Paste the copied token and set up a new password.
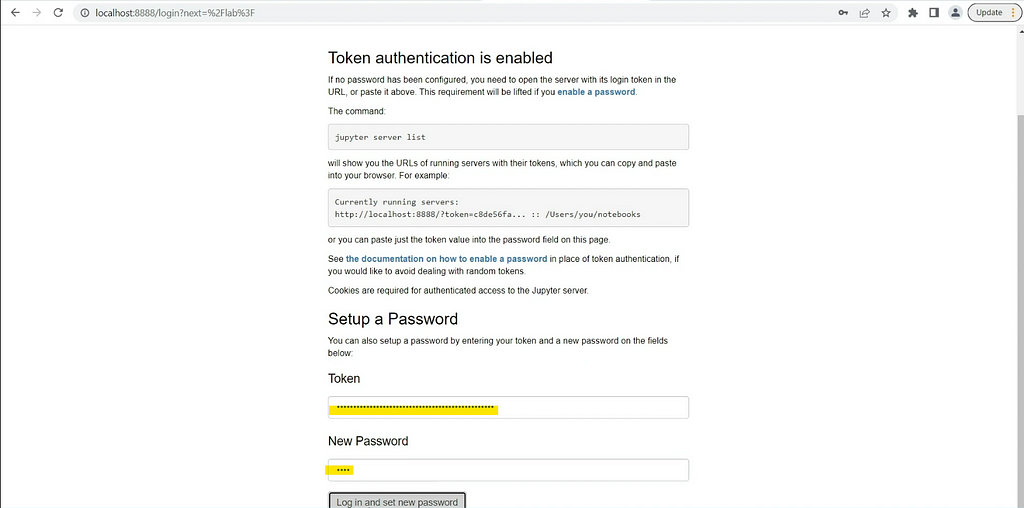
Voila, we just created a brand new PySpark Jupyter lab environment on Docker.

Next time you just need to start the container, open the website and login using the set password.
To check out SparkSession web UI — http://localhost:4040
Note: This is a completely configured PySpark env, open a notebook create a SparkSession and start using it. There is no need of any setup of Spark, Python etc. In case you need any library, you can install it as it comes with root privileges by default.
Still struggling, checkout the following YouTube video
https://medium.com/media/95e62b63838c2ad349a87b96b818eb37/hrefMake sure to Like and Subscribe.
Follow us on YouTube: https://youtube.com/@easewithdata
If you are new to Data Warehousing checkout — https://youtube.com/playlist?list=PL2IsFZBGM_IE-EvpN9gaZZukj-ysFudag
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal