Data Lakehouse with PySpark — Setup Delta Lake Warehouse on S3 and Boto3 with AWS
Next, as part of the series Data Lakehouse with PySpark, we need to setup boto3 and Delta Lake to communicate with AWS S3. This will help us to create our default warehouse location for Delta Lake on AWS S3. We will also setup the metastore location for Delta Lake.

To start, we need the AWS credentials Access Key and Secret Access Key. Checkout — https://medium.com/@subhamkharwal/pyspark-connect-aws-s3-20660bb4a80e to know more. In case of any issues, please follow the YouTube video at the end.
Connect AWS from boto3:
Once we have the AWS Access Key and Secret Access Key, create a new folder .aws and file credentials in the user’s root directory. Add the following lines replacing the Access Key, Secret Key with profile as default and save the file.
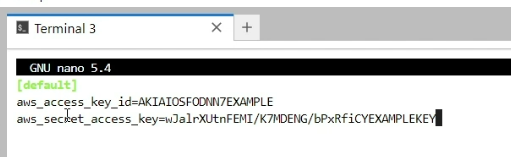
[default]
aws_access_key_id=<Your AWS Access Key>
aws_secret_access_key=<Your AWS Secret Key>
And we are done, now boto3 can easily use the credentials from the default profile to connect with AWS.
Connect AWS from Delta Lake:
To connect Delta Lake with AWS S3 and create the default warehouse location on AWS S3. Add the following lines in the bottom on spark-defualts.conf file.
park.jars.packages io.delta:delta-core_2.12:2.1.1,org.apache.hadoop:hadoop-aws:3.3.2
spark.sql.extensions io.delta.sql.DeltaSparkSessionExtension
spark.sql.catalog.spark_catalog org.apache.spark.sql.delta.catalog.DeltaCatalog
spark.sql.warehouse.dir s3a://easewithdata/dw-with-pyspark/warehouse
spark.driver.extraJavaOptions -Dderby.system.home=/home/jupyter/ease-with-data/dw-with-pyspark/derby

Please change parameter as per your location on S3. This setup is done as per the session of Data Lakehouse on YouTube — https://youtube.com/playlist?list=PL2IsFZBGM_IExqZ5nHg0wbTeiWVd8F06b
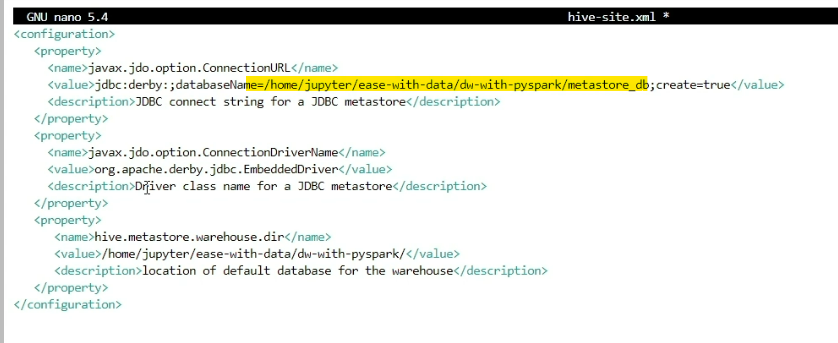
We can also define the location of the metastore for Delta Lake using the hive-site.xml file.
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=/home/jupyter/ease-with-data/dw-with-pyspark/metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/jupyter/ease-with-data/dw-with-pyspark/</value>
<description>location of default database for the warehouse</description>
</property>
</configuration>
Save the files and we would now be able to easily create Delta table with default warehouse location on S3.
Github location for conf files — https://github.com/subhamkharwal/ease-with-data/tree/master/dw-with-pyspark/conf
Still struggling, checkout the following YouTube video
https://medium.com/media/814f8ba52eb1ebb4e82c402980b275af/hrefMake sure to Like and Subscribe.
Follow us on YouTube: https://youtube.com/@easewithdata
If you are new to Data Lakehouse checkout — https://youtube.com/playlist?list=PL2IsFZBGM_IExqZ5nHg0wbTeiWVd8F06b
Top Five
Following are the top five articles as per views. Don't forget check them out:
Buy me a Coffee
If you like my content and wish to buy me a COFFEE. Click the link below or Scan the QR.
Buy Subham a Coffee
*All Payments are secured through Stripe.

About the Author
Subham is working as Senior Data Engineer at a Data Analytics and Artificial Intelligence multinational organization.
Checkout portfolio: Subham Khandelwal